
自动驾驶 | 特斯拉纯视觉机器学习解决方案
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:计算机视觉联盟
Scaled ML Conference今年2月26-27召开,特斯拉AI高级总监Andrej Karpathy在会上给了一个报告,其中一些内容在去年6月ICML也讲过了。下面以网上的视频截屏作为笔记,我稍稍注释一下。



报告纲要

特斯拉30亿英里的驾驶数据,无人匹敌。
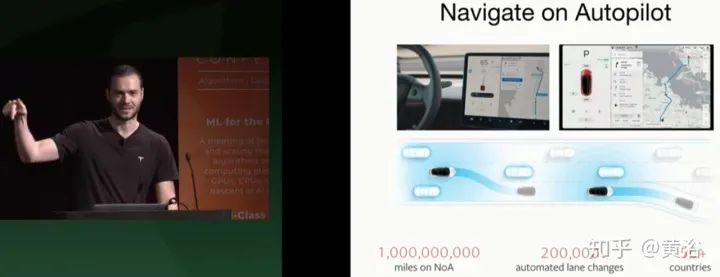
前不久提供的导航功能(高速闸口),能自动换道。
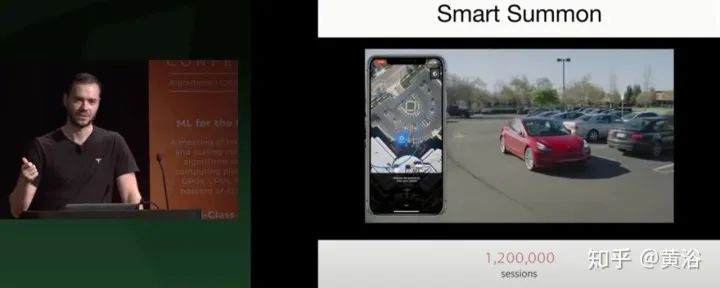
还有停车场的手机召唤。

这是最近实现的L2.5功能。

三个短视频,介绍行人AEB。

这里展示了特斯拉的全自动驾驶的视频,看到上下高速。

这里提了一下谷歌维摩,解释为什么人家那么早就开始了,因为有激光雷达,高清地图。
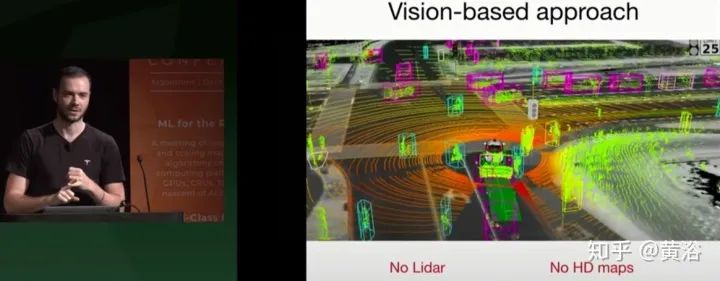
这是维摩的自动驾驶展示,强调特斯拉是纯视觉技术。

这里就是视觉的任务。
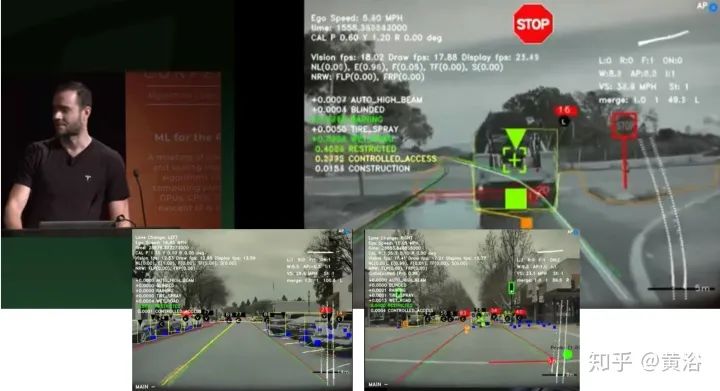
展示全自动驾驶视频中的视觉技术。

为强调视觉的难度,特意拿stop sign detection为例子,展示各种困难。
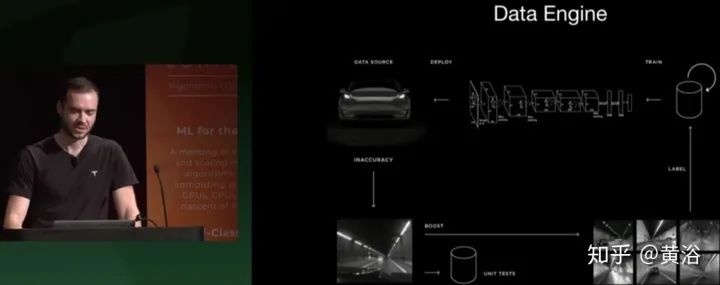
介绍Data Engine的平台,以前ICML也讲过,同时强调特斯拉的shadow mode。

这里举例,上面是遮挡,下面是右转弯不需要遵守stop。

评估测度。

介绍hydranet,以前就是多任务训练(multi task learning),给了个名字。
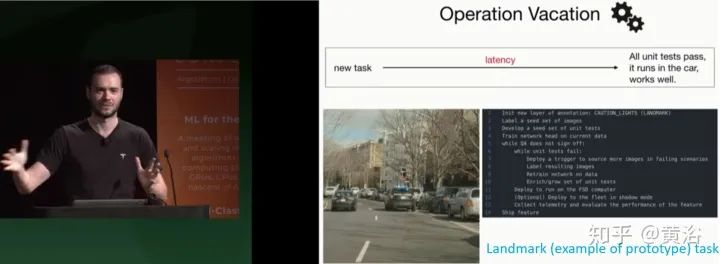
重新介绍operation vacation,举例police alert light检测,称为landmark task,landmark定义为example of prototype。

举例HydraNet,检测运动目标、道路边缘和道路线。
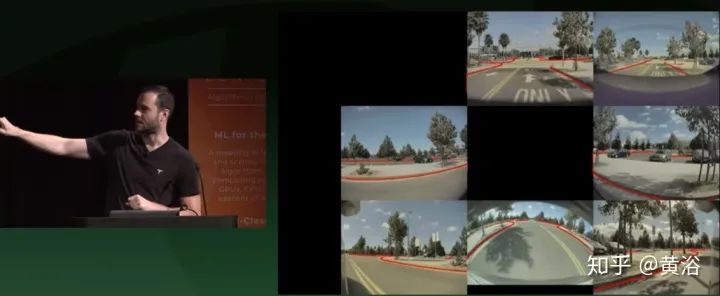
这是其中Road Edge网络输出。
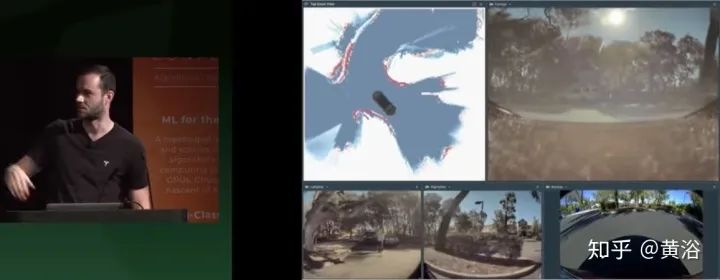
这是Occupancy tracker,将道路边缘连接成空区域,可用于smart summon。
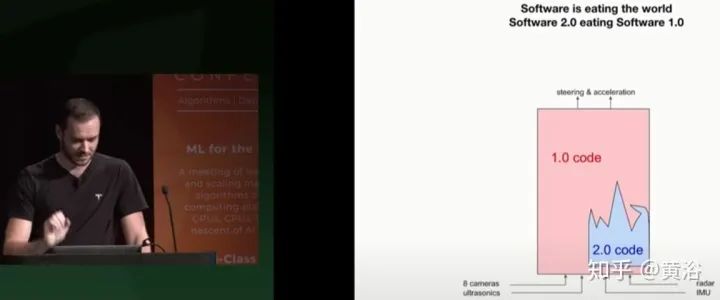
过了两年,重提SW 2.0,不过这里是用于泊车场。

提出BEV Net,即鸟瞰视图的预测,backbone共享,多个head。

这里介绍BEV Net结果好于2D边缘预测的方法。

应用视频:停车场红色边缘,绿色是分界。

另外一个应用视频:停车场手机召唤。

强调深度图,伪激光雷达,3D目标检测。

介绍自己的非监督学习深度图预测,还是强调伪激光雷达的效果。

特斯拉有最多的视频数据。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~