
学习笔记 ——深度学习和机器视觉
击上方“机器视觉”,点右上角...选择“置顶/星标”公众号
接收最新推文!
一、深度学习:理论和关注机制的进展(Yoshua Bengio)
二、深度语义学习 (Xiaodong He)
三、深度神经网络和GPU(Julie Bernauer)
四、深度视觉Keynote(Rahul Sukthankar)
五、学习和理解视觉表示(Andrea Vedaldi)
六、用于目标检测的可变深度卷积神经网络(Xiaogang Wang)
一直自称研究方向是“机器视觉、机器学习和深度学习”,然而除了做过几个相关的项目以外,感觉自己对这个领域并没有足够深入的认识和理解。趁着这个假期我要好好补补课了。今天先来看一些high level的内容,看看深度学习近期的最近进展以及其在机器视觉问题中的应用。学习资料来源于2015年CVPR的Deep Learning in Computer Vision Workshop 里invited speaker的slides,介绍了理论、应用、实现等方面的内容,应该是干货满满的。对于每一个talk,我会把内容框架记录下来(可以check一下对这些点是否有一定了解?),并记下一些个人觉得有趣的点。想看完整内容就戳这个链接吧:Deep Learning in Computer Vision Workshop:http://www.deep-vision.net/
一、深度学习:理论和关注机制的进展(Yoshua Bengio)
顾名思义,Bengio的talk主要讲了两个部分:理论进展和attention mechanism。理论进展介绍了:
分布式表示的“指数级”优点
深度的“指数级”优点
非凸优化和局部最小值
自编码器的概率解释
Attention 机制则介绍了在机器翻译、语音、图像、视频和记忆单元中的应用。
分布式表示和深度的优点Bengio之前的talk里已经讲过不少次了。简单的说,虽然类似local partition的方法可以得到有用的表示,浅层(2层)的神经网络也可近似任意的函数,但是分布式表示和深度的引入可以使特征表示和模型变得更加紧凑(compact),达到exponentially more statistically efficient的效果。
接下来提到了在深度学习中凸性质(convexity)可能并不是必要的。因为在高维空间中,鞍点(saddle point)的存在是主要问题,而局部最小值通常都会很接近全局最小值了。这部分的内容比较陌生,有兴趣可以看看最近的论文。
Attention 机制方面,讲了很多最新的进展。有很多相关的paper都非常有趣,我要找个时间好好看看这个系列了。一个基本的思路是:我们给每一层引入一个额外的输入,这个输入反应的是之前的一个加权,来表示它们的关注程度。在所谓的soft-attention中,这个加权的值可以直接通过BP训练得到。记下几句有趣的话:
- They (Attention mechanism) could be interesting for speech recognition and video, especially if we used them to capture multiple time scales
- They could be used to help deal with long-term dependencies, allowing some states to last for arbitrarily long
二、深度语义学习 (Xiaodong He)
来自微软研究院的报告,主要内容:
学习文本的语义性(semantic)表示
知识库和问答系统
多模态(图片——文本)语义模型
讲座开始引入了一点有趣的motivation:一般我们测试机器是否能够理解图片(其实就是训练对了),方法是给图片标记标签然后计算其错误率。然而对于含有丰富内容的复杂场景来说,很难定义所有fine-grained的类别。因此,用自然语言的描述来测试对图片的理解是比较好的方式。
从 Word2Vec 到 Sent2Vec:Deep Structured Semantic Model (DSSM),虽然我们不知道该如何标记一个句子的语义,但我们知道哪些句子的语义是比较接近的,因此文章通过优化一个基于相似性的目标函数来训练模型,使具有相近语义的句子产生距离相近的向量。接着还介绍了很多模型的细节和变种(卷积DSSM、递归DSSM),在此就不赘述了。
Deep Multimodal Similarity Model (DMSM):将目标函数中两个句子的相似性改成句子和图片的相似性,便可以将DSSM扩展为一个多模态的模型。
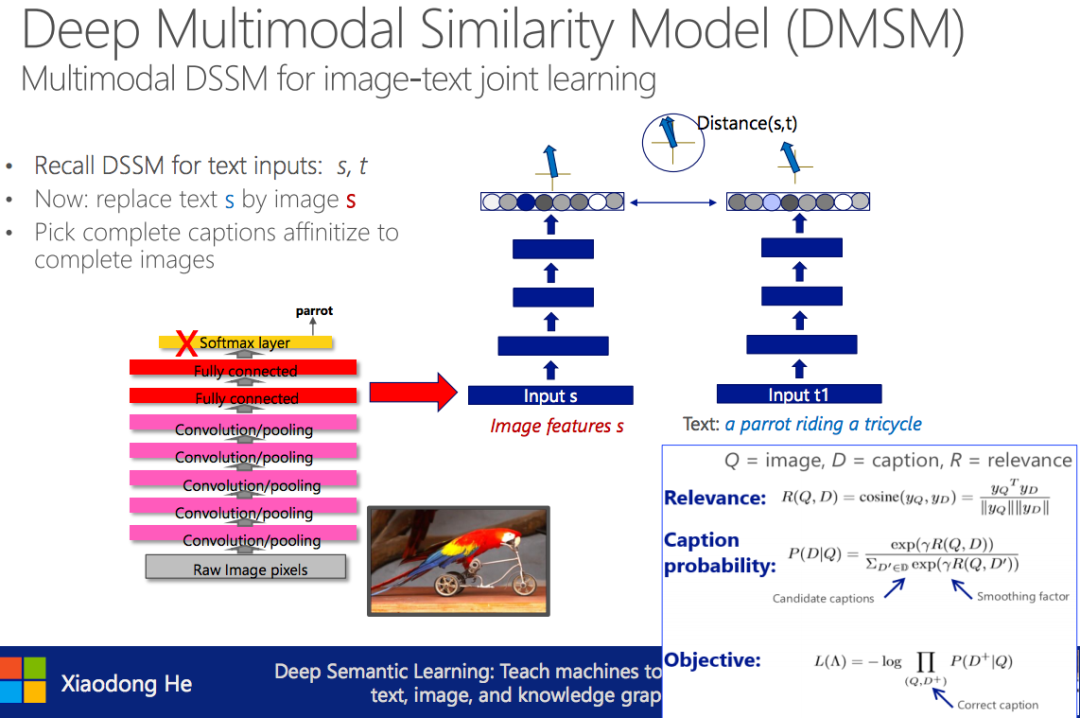
MSR系统解决图片–>语言问题:
图片词语检测(Image word detection)
句子生成(Language generation)
全局语义性重排序(Global semantic re-ranking)
其中图片词语检测用了CNN+MIL(Multiple Instance Learning)的方法,个人对此比较感兴趣,文章在此。
三、深度神经网络和GPU(Julie Bernauer)
换个口味,我们来看看NVIDIA关于深度学习和GPU的结合。总的来说,内容上跟NVIDIA官网上介绍深度学习的slides没什么不同。主要介绍了GPU有什么好处、GPU有多牛,还有一些支持GPU的库和工具。
一张比较好的图:

有用的工具:
Lasagne:基于theano上的开源库,能方便搭建一个深度网络。(Keras用得不太爽,可以试试这个)
四、深度视觉Keynote(Rahul Sukthankar)
来看看来自google的报告。这个talk里面的内容都不太熟悉,但是看起来都非常有意思。主要内容有:
用Peer Presssure方法来找high value mistake
结合深度学习和其他机器学习方法来更好解决视觉问题
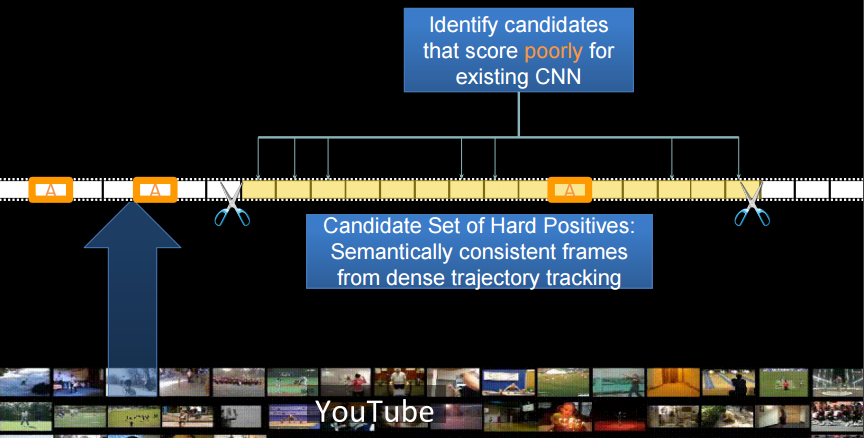
首先来看看Peer Pressure。这是Rahul组最近的一个工作:The Virtues of Peer Pressure: A Simple Method for Discovering High-Value Mistakes。所谓“high-value mistake”,指的是那些我们认为训练好的模型可以准确预测的样本,结果它却“犯傻”了。因此这些样本也叫做“hard positive”,难以答对的样子。
从头说起,深度神经网络虽然有很多成功的应用,但同时也被发现很容易犯愚蠢的错误(比如上述的high-value mistake)。因此作者提出了Peer Pressure:集成+对抗训练(emsembles+adversarial training)的方法,来找到这些错误。简单来说就是,有一组训练于同样数据但是初始化或者结构不同的NN分类器(称作peers),如果一个样本出现其中一个NN输出与其它都不一致的情况(其它NN淡然都是一致的了),那么它应该就是high-value mistake。寻找这类错误当然是有价值的啦:(1)它可以用在发掘无标签的数据中(2)可以用来合成新的hard positive样本。
接下来提到将上述的方法应用到视频当中,找出anchor frame附近的hard positive 帧,用来训练更好的模型。其中具有semantic consistency的帧是通过Dense Trajectory来确定的。感觉挺有意思,可惜没找到相应的paper,那就上张图吧。
五、学习和理解视觉表示(Andrea Vedaldi)
来自牛津大学的报告,题目看起来还是很吸引人的。大纲如下(略有失望,好像就是讲CNN的):
黑盒:一个将CNN用于图片文字识别的例子
架构:卷积和纹理
可视化:CNN所知道的图片
性质:对比CNN和视觉几何
第一个例子用CNN做OCR,感觉并不是很有趣。一个challenge是它的类别特别多(90k个类,对应90k个单词)。他们解决的办法是增量地训练网络,即先只训练5k个类,再逐步添加5k个新的类。。。效果好像还不错。
第二部分讲分辨纹理。提出用CNN的卷积层加上Fisher Vector(替换全连接层)来做,效果不错不错的。
第三部分可视化,看看就好。
第四部分还不错,讲的是图像变换对特征表示的影响。除去语义层面上的影响(特征的不变性跟任务相关),我们通常希望图像的特征表示不受图像变换的影响,如翻转和仿射变换。
类内差异大,包括:部分出现(part existence)、颜色、遮挡、变形

六、用于目标检测的可变深度卷积神经网络(Xiaogang Wang)
最后一个talk,讲的是我最近比较关注的目标检测问题,主要介绍他们的DeepID-Net。
第一部分他们的工作,用深度学习进行行人识别。其中着重讲了通过设计大小可变的卷积核来实现部分检测器(Part detector),对于行人识别应该是重要的一部分。
第二部分讲更general的目标检测问题。首先介绍目标检测的困难有(经筛选):
对比了他们的DeepID-Net和RCNN:

后面详细的介绍了他们模型的每个环节。总体来说,感觉每个环节都比较tricky,暂时也看不到有什么insight,故先略过了。之后专门研究object detection时可能还会重新看看他们的工作。
版权声明:本文为CSDN博主「xtyang315」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yjn03151111/article/details/50437951
004:Facebook 开源计算机视觉系统,从像素水平理解图像(附论文及代码)
009:从洗衣妹到谷歌首席科学家,她靠孤独改变了人工智能界!
019:机器人控制系统相关知识大汇集
020:机器人的工作原理,史上最详细的解析!
021:光源选型知识点
022:这才是机械手,这才是自动化,你那算什么?
023:摄像机和镜头的基础知识
024:物联网产业链全景图(附另13大电子行业全景图,必收藏)
025:日本到底强大到什么地步?让人窒息!看后一夜未眠
026:德国机械用行动惊艳全世界:无敌是多么寂寞
 欢迎转发、留言、点赞、分享,感谢您的支持!
欢迎转发、留言、点赞、分享,感谢您的支持!