
基于 Flink 构建万亿数据量下的实时数仓及实时查询系统
一、背景介绍
推荐系统
对于推荐同学来说,想知道一个推荐策略在不同人群中的推荐效果是怎么样的。
运营
对于运营的同学来说,想知道在广东省的用户中,最火的广东地域内容是哪些?方便做地域 push。
审核
对于审核的同学,想知道过去 5 分钟游戏类被举报最多的内容和账号是哪些,方便能够及时处理。
内容创作
对于内容的作者,想知道今天到目前为止,内容被多少个用户观看,收到了多少个点赞和转发,方便能够及时调整他的策略。
老板决策
对于老板来说,想知道过去 10 分钟有多少用户消费了内容,对消费人群有一个宏观的了解。

2. 开发前调研

■ 2.1 离线数据分析平台能否满足这些需求
调研的结论是不能满足离线数据分析平台,不行的原因如下:
首先用户的消费行为数据上报需要经过 Spark 的多层离线计算,最终结果出库到 MySQL 或者 ES 提供给离线分析平台查询。这个过程的延时至少是 3-6 个小时,目前比较常见的都是提供隔天的查询,所以很多实时性要求高的业务场景都不能满足。
另一个问题是腾讯看点的数据量太大,带来的不稳定性也比较大,经常会有预料不到的延迟,所以离线分析平台是无法满足这些需求的。
■ 2.2 准实时数据分析平台
3. 腾讯看点信息流的业务流程
第 1 步,内容创作者发布内容;
第 2 步,内容会经过内容审核系统启用或者下架;
第 3 步,启用的内容给到推荐系统和运营系统,分发给 C 侧用户;
第 4 步,内容分发给 C 侧用户之后,用户会产生各种行为,比如说曝光、点击举报等,这些行为数据通过埋点上报,实时接入到消息队列中;
第 5 步,构建实时数据仓库;
第 6 步,构建实时数据查询系统。
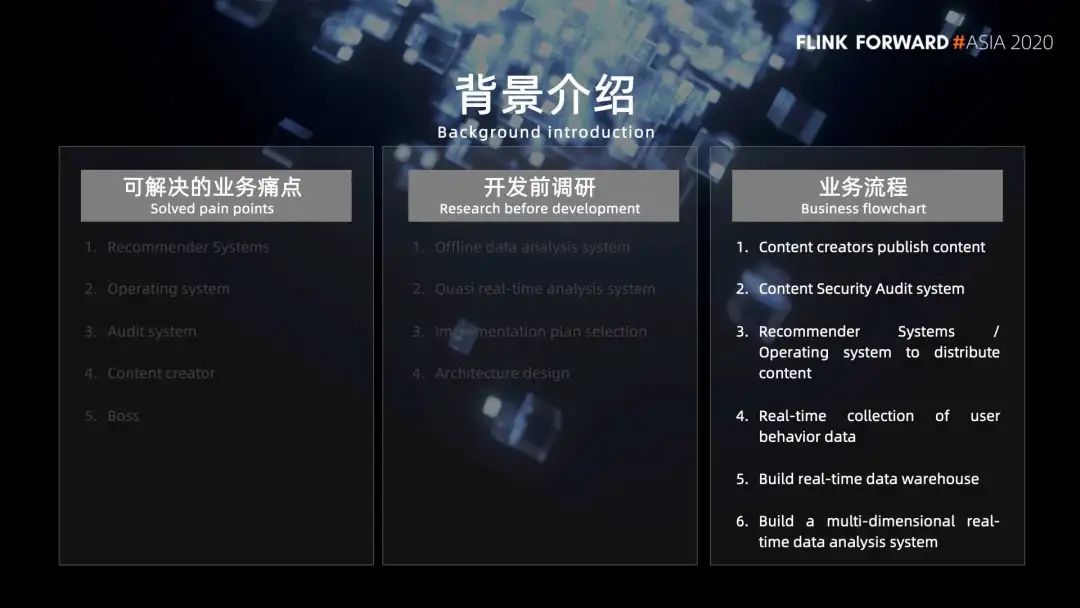
在业务流程图中,我们主要做的两部分工作,就是图中有颜色的这两部分:
橙色部分,我们构建了一个腾讯看点的实时数据仓库;
绿色部分,我们基于了 OLAP 的存储计算引擎,开发了实时数据分析系统。
二、架构设计
1. 设计的目标与难点
首先来看一下数据分析系统的设计目标与难点。我们的实时数据分析系统分为四大模块:
实时计算引擎;
实时存储引擎;
后台服务层;
前端展示层。

难点主要在于前两个模块,实时计算引擎和实时存储引擎。
千万级每秒的海量数据如何实时的接入,并且进行极低延迟的维表关联是有难度的;
实时存储引擎如何支持高并发的写入。高可用分布式和高性能的索引查询是比较难的,可以看一下我们的系统架构设计来了解这几个模块的具体实现。
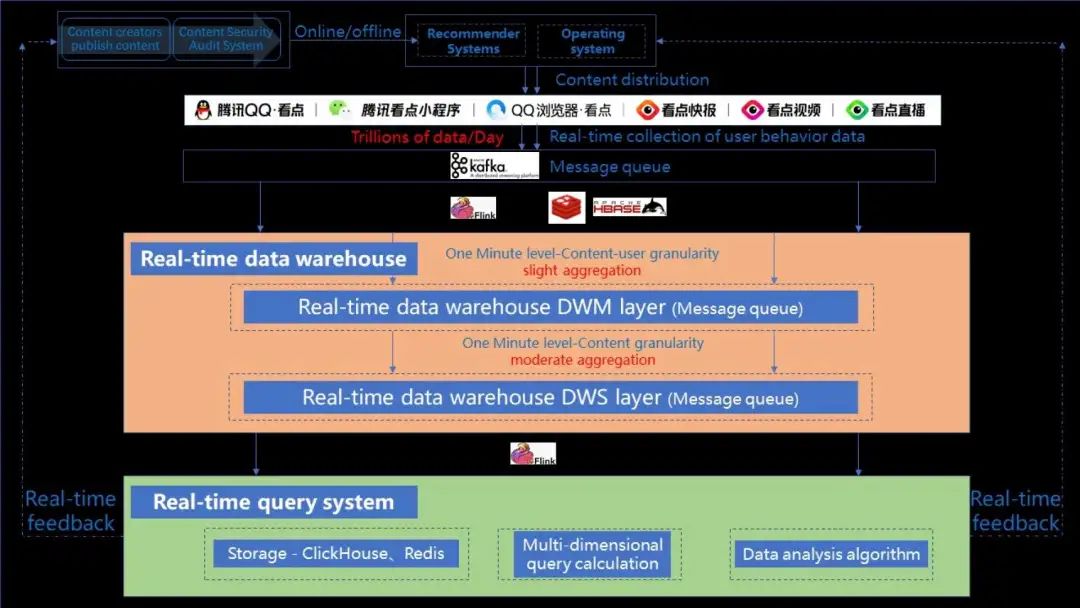
2. 系统架构设计
■ 2.1 实时计算
接入层主要是从千万级每秒的原始消息队列中拆分出不同业务不同行为数据的微队列。拿 QQ 看点的视频内容来说,拆分过后的数据就只有百万级每秒了。
实时计算层主要是负责多行行为流水数据进行 "行转列" 的操作,实时关联用户画像数据和内容维度数据。
实时数仓存储层主要就是设计出符合看点的业务,下游好用的实时消息队列。

我们暂时提供了两个消息队列,作为实时数仓的两层:
第一层是 DWM 层,它是内容 ID 和用户 ID 粒度聚合的,就是说一条数据包含了内容 ID 和用户 ID,然后还有 B 侧的内容维度数据,C 侧的用户行为数据,还有用户画像数据。
第二层是 DWS 层,这一层是内容 ID 粒度聚合的,就是一条数据包含了内容 ID、B 侧数据和 C 侧数据。可以看到内容 ID 和用户 ID 粒度的消息,队列流量进一步减小到了 10 万级每秒,内容 ID 粒度更是减小到了万级每秒,并且格式更加清晰,维度信息更加丰富。

■ 2.2 实时存储
实时写入层主要是负责 Hash 路由,将数据写入;
OLAP 存储层是利用 MPP 的存储引擎,设计出符合业务的索引和物化视图,高效存储海量数据;
后台接口层是提供了高效的多维实时查询接口。

■ 2.3 后台服务
■ 2.4 前端服务
3. 方案选型

■ 3.1 实时数仓的选型
■ 3.2 实时计算引擎的选型
■ 3.3 实时存储引擎
三、实时数仓
实时数仓也分为三块来介绍:
第一是如何构建实时数仓;
第二是实时数仓的优点;
第三是基于实时数仓,利用 Flink 开发实时应用时候遇到的一些问题。
1. 如何构建实时数仓

■ 1.1数据清洗
■ 1.2 高性能维表关联
■ 1.3 不同粒度聚合
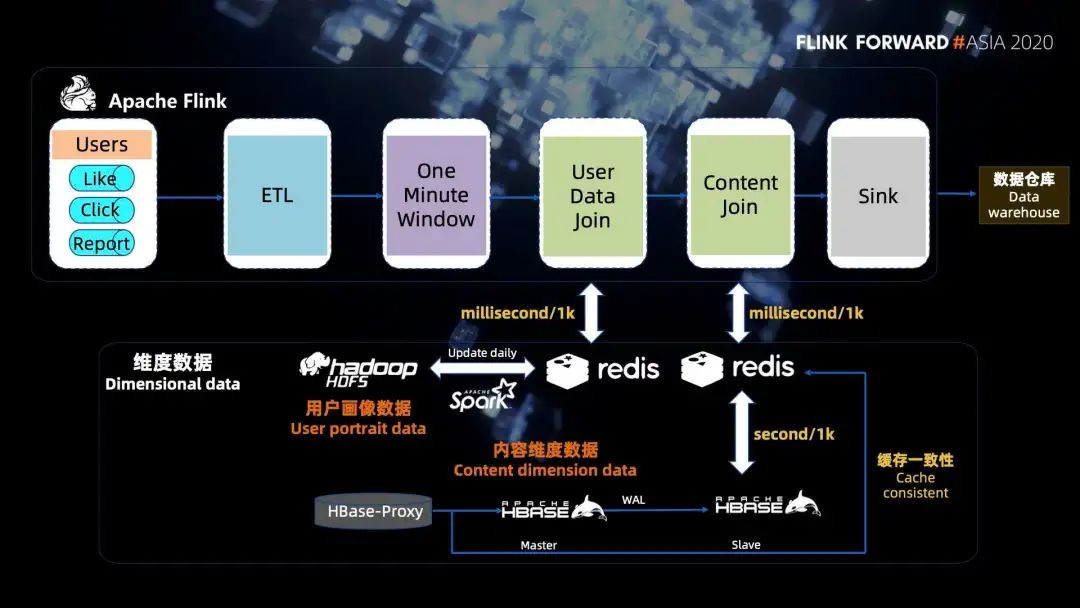
接下来详细介绍一下第二步中高性能实时维表关联是怎么处理的。
几十亿的用户画像数据存放在 HDFS 上,肯定是无法进行高性能的维表关联的,所以需要进行缓存。由于数据量太大,本地缓存的代价不合理,我们采用的是 Redis 进行缓存,具体实现是通过 Spark 批量读取 HDFS 上的画像数据,每天更新 Redis 缓存,内容维度数据存放在 HBase 中。
为了不影响线上的业务,我们访问的是 HBase 的备库,而且由于内容维度变化的频率远高于用户画像,所以维度关联的时候,我们需要尽量的关联到实时的 HBase 数据。
一分钟窗口的数据,如果直接关联 HBase 的话,耗时是十几分钟,这样会导致任务延迟。我们发现 1000 条数据访问 HBase 是秒级的,而访问 Redis 的话只是毫秒级的,访问 Redis 的速度基本上是访问 HBase 的 1000 倍,所以我们在访问 HBase 的内容之前设置了一层 Redis 缓存,然后通过了监听 HBase-proxy 写流水,通过这样来保证缓存的一致性。
这样一分钟的窗口数据,原本关联内容维度数据耗时需要十几分钟,现在就变成了秒级。我们为了防止过期的数据浪费缓存,缓存的过期时间我们设置成了 24 个小时。
最后还有一些小的优化,比如说内容数据上报过程中会上报不少非常规的内容 ID,这些内容 ID 在 HBase 中是不存储的,会造成缓存穿透的问题。所以在实时计算的时候,我们直接过滤掉这些内容 ID,防止缓存穿透,又减少了一些时间。另外,因为设置了定时缓存,会引入一个缓存雪崩的问题,所以我们在实时计算的过程中进行了削峰填谷的操作,错开了设置缓存的时间,来缓解缓存雪崩的问题。
2. 实时数仓的优点

我们可以看一下,在我们建设实时数仓的前后,开发一个实时应用的区别。
没有数仓的时候,我们需要消费千万级每秒的原始队列,进行复杂的数据清洗,然后再进行用户画像关联、内容维度关联,才能够拿到符合要求格式的实时数据。开发和扩展的成本都会比较高。如果想开发一个新的应用,又要走一遍流程。现在有了实时数仓之后,如果再想开发一个内容 ID 粒度的实时应用,就直接申请 TPS 万级每秒的 DWS 层消息对列即可,开发成本变低很多,资源消耗小了很多,可扩展性也强了很多。
我们看一个实际的例子,开发我们系统的实时数据大屏,原本需要进行如上的所有操作才能够拿到数据,现在只需要消费 DWS 层消息队列写一条 Flink SQL 即可,仅仅会消耗 2 个 CPU 核心和 1GB 的内存。以 50 个消费者为例,建立实时数仓的前后,下游开发一个实时应用,可以减少 98% 的资源消耗,包括了计算资源、存储资源、人力成本和开发人员的学习接入成本等等,并且随着消费者越多节省的就越多,就拿 Redis 存储这一部分来说,一个月就能够省下上百万的人民币。
3. Flink 开发过程中遇到的问题总结
■ 3.1 实时数据大屏

■ 3.2 Flink state 的 TTL

■ 3.3 使用 Flink valueState 和 mapState 经验总结
虽然通过 valueState 也可以存储 map 结构的数据,但是能够使用 mapState 的地方尽量使用 mapState,最好不要通过 valueState 来存储 map 结构的数据,因为 Flink 对 mapState 是进行了优化的,效率会比 valuState 中存储 map 结构的数据更加高效。
比如我们遇到过的一个问题就是使用 valueState 存储了 map 结构的数据,选择的是 rocksDB backend。我们发现磁盘的 IO 变得越来越高,延迟也相应的增加。后面发现是因为 valueState 中修改 map 中的任意一个 key 都会把整个 map 的数据给读出来,然后再写回去,这样会导致 IO 过高。但是 mapState,它每一个 key 在 rocksDB 中都是一条单独的 key,磁盘 IO 的代价就会小很多。

■ 3.4 Checkpoint 超时问题
我们还遇到过一些问题,比如说 Checkpoint 超时了,当时我们第一个想法就是计算资源不足,并行度不够导致的超时,所以我们直接增加了计算资源,增大了并行度,但是超时的情况并没有得到缓解。后面经过研究才发现是数据倾斜,导致某个节点的 barrier 下发不及时导致的,通过 rebalance 之后才能够解决。
总的来说 Flink 功能还是很强的,它文档比较完善,网上资料非常丰富,社区也很活跃,一般遇到问题都能够比较快的找到解决方案。
四、实时数据查询系统
我们的实时查询系统,多维实时查询系统用的是 Clickhouse 来实现的,这块分为三个部分来介绍。第一是分布式高可用,第二是海量数据的写入,第三是高性能的查询。
Click house 有很多表引擎,表引擎决定了数据以什么方式存储,以什么方式加载,以及数据表拥有什么样的特性?目前 Clickhouse 拥有 merge tree、replaceingMerge Tree、AggregatingMergeTree、外存、内存、IO 等 20 多种表引擎,其中最体现 Clickhouse 性能特点的是 merge tree 及其家族表引擎,并且当前 Clickhouse 也只有 merge 及其家族表引擎支持了主键索引、数据分区、数据副本等优秀的特性。我们当前使用的也是 Clickhouse 的 merge tree 及其家族表引擎,接下来的介绍都是基于引擎展开的。
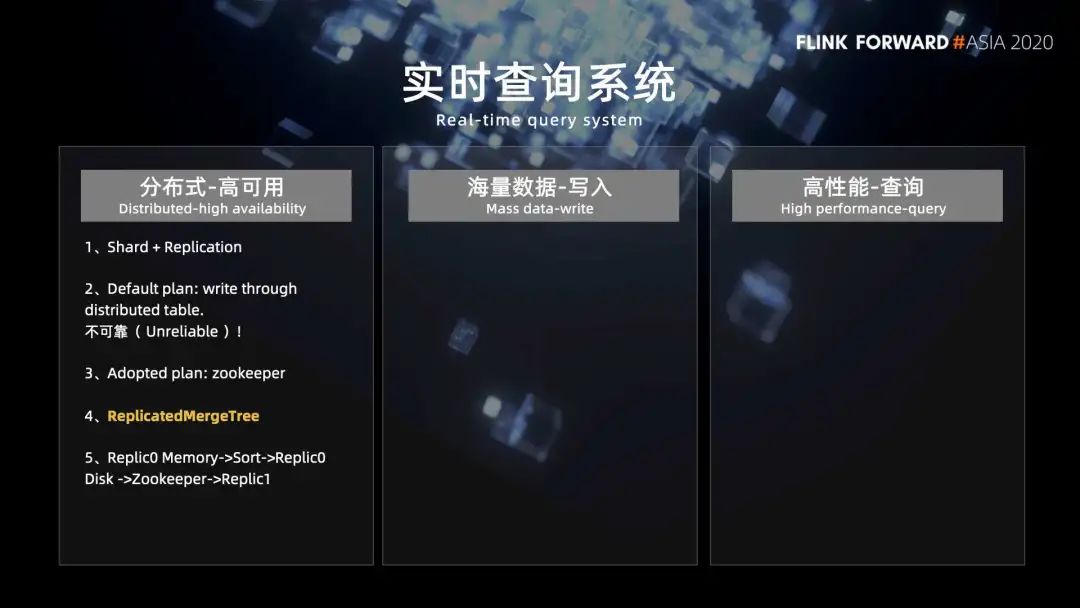
1. 分布式高可用
2. 海量数据的写入
■ 2.1 Append + Merge
如果一次写入的数据太少,比如一条数据只写一次,就会产生大量的文件目录。当后台合并线程来不及合并的时候,文件目录的数量就会越来越多,这会导致 Clickhouse 抛出 too many parts 的异常,写入失败。
另外,之前介绍的每一次写入除了数据本身,Clickhouse 还会需要跟 Zookeeper 进行 10 来次的数据交互,而我们知道 Zookeeper 本身是不能够承受很高的并发的,所以可以看到写入 Clickhouse QPS 过高,导致 zookeeper 的崩溃。
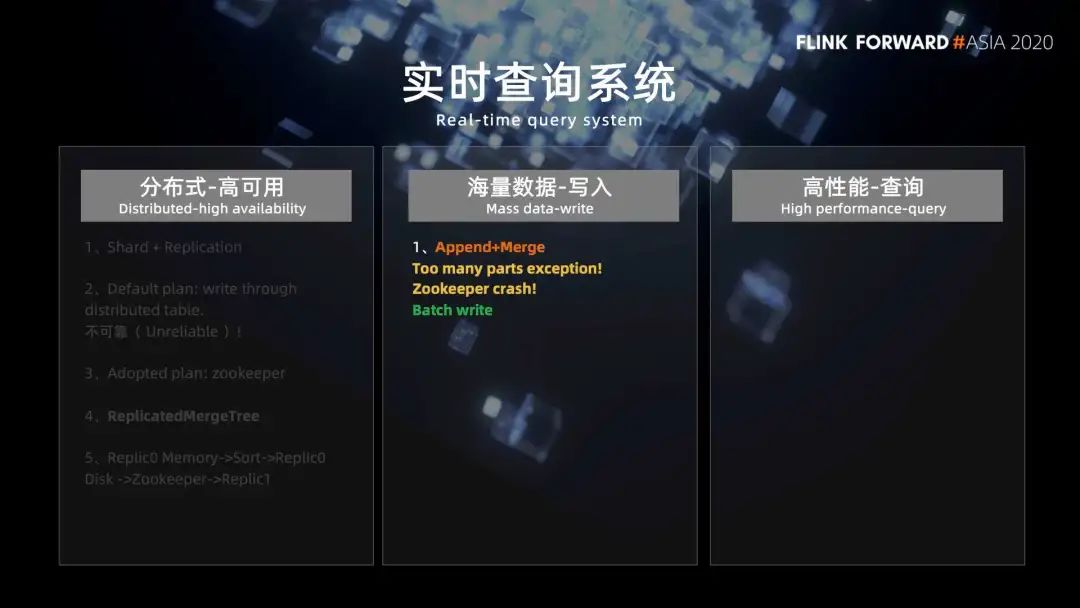
我们采用的解决方案是改用 batch 的方式写入,写入 zookeeper 一个 batch 的数据,产生一个数据目录,然后再与 Zookeeper 进行一次数据交互。那么 batch 设置多大?如果 batch 太小的话,就缓解不了 Zookeeper 的压力;但是 batch 也不能设置的太大,要不然上游的内存压力以及数据的延迟都会比较大。所以通过实验,最终我们选择了大小几十万的 batch,这样可以避免了 QPS 太高带来的问题。
其实当前的方案还是有优化空间的,比如说 Zookeeper 无法线性扩展,我有了解到业内有些团队就把 Mark 和 date part 相关的信息不写入 Zookeeper。这样能够减少 Zookeeper 的压力。不过这样涉及到了对源代码的修改,对于一般的业务团队来说,实现的成本就会比较高。
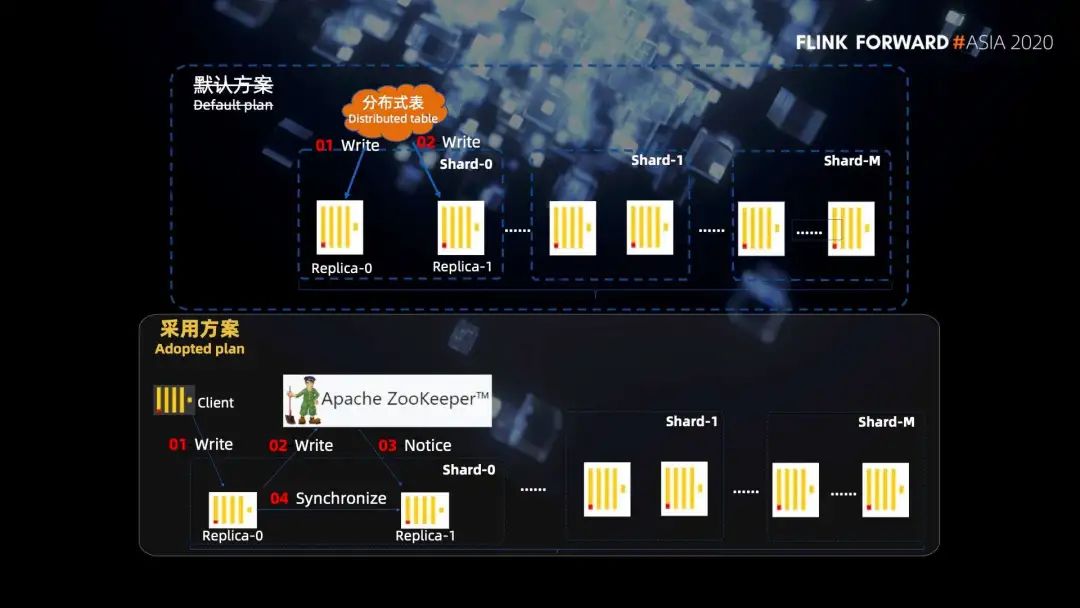
■ 2.2 分布式表写入

这里有一个很容易误解的地方,我们最开始也是以为分布式表只是按照一定的规则做一个网络的转发,以为万兆网卡的带宽就足够,不会出现单点的性能瓶颈。但是实际上 Clickhouse 是这样做的,我们看一个例子,有三个分片 shard1,shard2 和 shard3,其中分布式表建立在 shard2 的节点上。
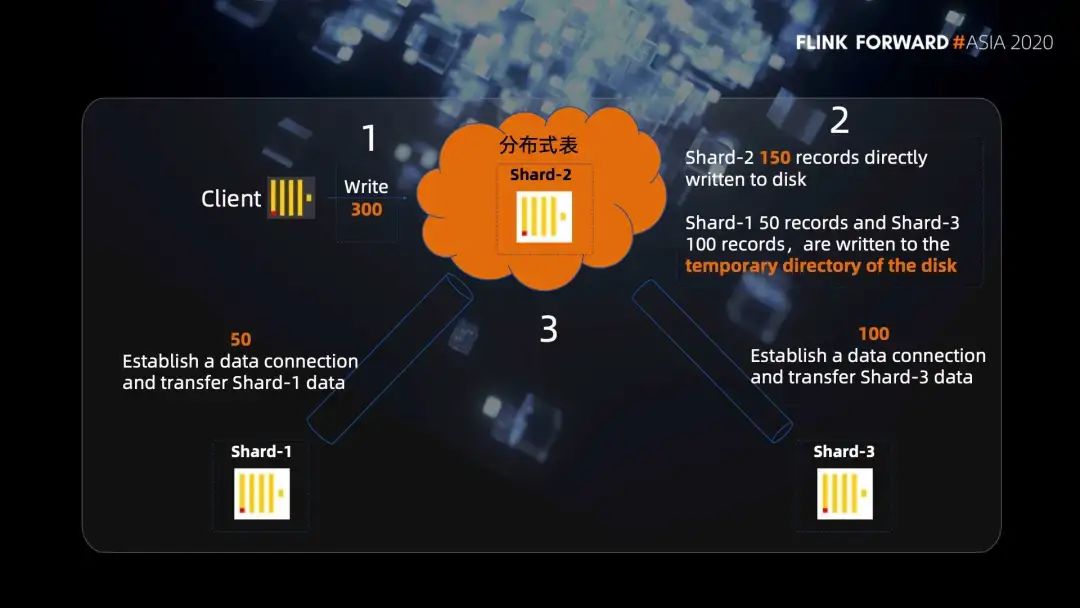
第一步,我们给分布式表写入 300 条数据,分布式表会根据路由规则把数据进行分组,假设 shard1 分到 50 条,shard2 分到 150 条,shard3 分到 100 条。
第二步,因为分布式表跟 shard2 是在同一台机器上,所以 shard2 的 150 条就直接写入磁盘了。然后 shard1 的 50 条和 shard3 的 100 条,并不是直接转发给他们的,而是也会在分布式表的机器上先写入磁盘的临时目录。
第三步,分布式表节点 shard2 会向 shard1 节点和 shard3 节点分别发起远程连接的请求,将对应临时目录的数据发送给 shard1 和 shard3。
第一个就是对磁盘做了 RAID 提升了磁盘的 IO;
第二就是在写入之前,上游进行了数据的划分分表操作,直接分开写入到不同的分片上,磁盘的压力直接变为了原来的 n 分之一,这样就很好的避免了磁盘的单点的瓶颈。

■ 2.3 局部 Top 并非全局 Top

第二是会造成数据错误,我们做的优化就是在写入之前加上了一层路由,我们将同一个内容 ID 的数据全部路由到了同一个分片上,解决了该问题。这里需要多说一下,现在最新版的 Clickhouse 都是不存在这样这个问题的,对于有 group by 和 limit 的 SQL 命令,只把 group by 语句下发到本地表进行执行,然后各个本地表执行完的全量结果都会传到分布式表,在分布式表再进行一次全局的 group by,最后再做 limit 的操作。
这样虽然能够保证全局 top N 的正确性,但代价就是牺牲了一部分的执行性能。如果想要恢复到更高的执行性能,我们可以通过 Clickhouse 提供的 distributed_group_by_no_merge 参数来选择执行的方式。然后再将同一个内容 ID 的记录全部路由到同一个分片上,这样在本地表也能够执行 limit 操作。
3. 高性能的存储和查询

举个例子,通过 summary merge tree 建立一个内容 ID 粒度聚合的累积,累加 pv 的物化视图,这样相当于提前进行了 group by 的计算,等真正需要查询聚合结果的时候,就直接查询物化视图,数据都是已经聚合计算过的,且数据的扫描量只是原始流水的千分之一。
分布式表查询还会有一个问题,就是查询单个内容 ID 的时候,分布式表会将查询请求下发到所有的分片上,然后再返回给查询结果进行汇总。实际上因为做过路由,一个内容 ID 只存在于一个分片上,剩下的分片其实都是在空跑。针对这类的查询,我们的优化就是后台按照同样的规则先进行路由,然后再查询目标分片,这样减少了 n 分之 n -1 的负载,可以大量的缩短查询时间。而且由于我们提供的是 OLAP 的查询,数据满足最终的一致性即可。所以通过主从副本的读写分离,也可以进一步的提升性能。我们在后台还做了一个一分钟的数据缓存,这样针对相同条件的查询,后台就可以直接返回。

4. Clickhouse 扩容方案
比如说 HBase 原始数据是存放在 HDFS 上的,扩容只是 region server 的扩容,并不涉及到原始数据的迁移。
但是 Clickhouse 的每个分片数据都是在本地,更像是 RocksDB 的底层存储引擎,不能像 HBase 那样方便的扩容。
然后是 Redis,Redis 是 Hash 槽这一种,类似于一致性 Hash 的方式,是比较经典的分布式缓存方案。
五、实时系统应用成果总结
我们输出了腾讯看点的实时数据仓库,DWM 层和 DWS 层两个消息队列,上线了腾讯看点的实时数据分析系统,该系统能够亚秒级的响应多维条件查询请求。在未命中缓存的情况下:
过去 30 分钟的内容查询,99% 的请求耗时在一秒内;
过去 24 小时的内容查询 90% 的请求耗时在 5 秒内,99% 的请求耗时在 10 秒内。
