
MongoDB vs MySQL,哪个效率更高?
互联网架构师后台回复 2T 有特别礼包
一、MongoDB批量操作
BulkWriteResult com.mongodb.client.MongoCollection.bulkWrite(List<? extends WriteModel<? extends Document>> requests)
1、插入操作
public void bulkWriteInsert(List<Document> documents){
List<WriteModel<Document>> requests = new ArrayList<WriteModel<Document>>();
for (Document document : documents) {
//构造插入单个文档的操作模型
InsertOneModel<Document> iom = new InsertOneModel<Document>(document);
requests.add(iom);
}
BulkWriteResult bulkWriteResult = collection.bulkWrite(requests);
System.out.println(bulkWriteResult.toString());
}
TestMongoDB instance = TestMongoDB.getInstance();
ArrayList<Document> documents = new ArrayList<Document>();
for (int i = 0; i < 100000; i++) {
Product product = new Product(i,"书籍","追风筝的人",22.5);
//将java对象转换成json字符串
String jsonProduct = JsonParseUtil.getJsonString4JavaPOJO(product);
//将json字符串解析成Document对象
Document docProduct = Document.parse(jsonProduct);
documents.add(docProduct);
}
System.out.println("开始插入数据。。。");
long startInsert = System.currentTimeMillis();
instance.bulkWriteInsert(documents);
System.out.println("插入数据完成,共耗时:"+(System.currentTimeMillis() - startInsert)+"毫秒");

(2)、逐条插入
下面再通过非批量插入10万个数据对比下,方法如下:
public void insertOneByOne(List<Document> documents) throws ParseException{
for (Document document : documents){
collection.insertOne(document);
}
}
测试:10万条数据
System.out.println("开始插入数据。。。");
long startInsert = System.currentTimeMillis();
instance.insertOneByOne(documents);
System.out.println("插入数据完成,共耗时:"+(System.currentTimeMillis() - startInsert)+"毫秒");
结果:12068毫秒,差距非常大。由此可见,MongoDB批量插入比逐条数据插入效率提高了非常多。

补充:
MongoCollection的insertMany()方法和bulkWrite()方法是等价的,测试时间差不多,不再贴图。
public void insertMany(List<Document> documents) throws ParseException{
//和bulkWrite()方法等价
collection.insertMany(documents);
}
2、删除操作
_id字段,该字段在文档插入数据库后自动生成,没插入数据库前document.get("_id")为null,如果使用其他条件比如productId,那么要在文档插入到collection后在productId字段上添加索引collection.createIndex(new Document("productId", 1));
因为随着collection数据量的增大,查找将越耗时,添加索引是为了提高查找效率,进而加快删除效率。另外,值得一提的是DeleteOneModel表示至多删除一条匹配条件的记录,DeleteManyModel表示删除匹配条件的所有记录。为了防止一次删除多条记录,这里使用DeleteOneModel,保证一个操作只删除一条记录。当然这里不可能匹配多条记录,因为_id是唯一的。搜索公众号互联网架构师后台回复“2T”,获取一份惊喜礼包。
public void bulkWriteDelete(List<Document> documents){
List<WriteModel<Document>> requests = new ArrayList<WriteModel<Document>>();
for (Document document : documents) {
//删除条件
Document queryDocument = new Document("_id",document.get("_id"));
//构造删除单个文档的操作模型,
DeleteOneModel<Document> dom = new DeleteOneModel<Document>(queryDocument);
requests.add(dom);
}
BulkWriteResult bulkWriteResult = collection.bulkWrite(requests);
System.out.println(bulkWriteResult.toString());
}
System.out.println("开始删除数据。。。");
long startDelete = System.currentTimeMillis();
instance.bulkWriteDelete(documents);
System.out.println("删除数据完成,共耗时:"+(System.currentTimeMillis() - startDelete)+"毫秒");

(2)、逐条删
来看看在非批量下的删除
public void deleteOneByOne(List<Document> documents){
for (Document document : documents) {
Document queryDocument = new Document("_id",document.get("_id"));
DeleteResult deleteResult = collection.deleteOne(queryDocument);
}
}
System.out.println("开始删除数据。。。");
long startDelete = System.currentTimeMillis();
instance.deleteOneByOne(documents);
System.out.println("删除数据完成,共耗时:"+(System.currentTimeMillis() - startDelete)+"毫秒");

3、更新操作
(1)、批量更新
public void bulkWriteUpdate(List<Document> documents){
List<WriteModel<Document>> requests = new ArrayList<WriteModel<Document>>();
for (Document document : documents) {
//更新条件
Document queryDocument = new Document("_id",document.get("_id"));
//更新内容,改下书的价格
Document updateDocument = new Document("$set",new Document("price","30.6"));
//构造更新单个文档的操作模型
UpdateOneModel<Document> uom = new UpdateOneModel<Document>(queryDocument,updateDocument,new UpdateOptions().upsert(false));
//UpdateOptions代表批量更新操作未匹配到查询条件时的动作,默认false,什么都不干,true时表示将一个新的Document插入数据库,他是查询部分和更新部分的结合
requests.add(uom);
}
BulkWriteResult bulkWriteResult = collection.bulkWrite(requests);
System.out.println(bulkWriteResult.toString());
}
System.out.println("开始更新数据。。。");
long startUpdate = System.currentTimeMillis();
instance.bulkWriteUpdate(documents);
System.out.println("更新数据完成,共耗时:"+(System.currentTimeMillis() - startUpdate)+"毫秒");

(2)、逐条更新
对比非批量下的更新
public void updateOneByOne(List<Document> documents){
for (Document document : documents) {
Document queryDocument = new Document("_id",document.get("_id"));
Document updateDocument = new Document("$set",new Document("price","30.6"));
UpdateResult UpdateResult = collection.updateOne(queryDocument, updateDocument);
}
}
System.out.println("开始更新数据。。。");
long startUpdate = System.currentTimeMillis();
instance.updateOneByOne(documents);
System.out.println("更新数据完成,共耗时:"+(System.currentTimeMillis() - startUpdate)+"毫秒");

4、混合批量操作
public void bulkWriteMix(){
List<WriteModel<Document>> requests = new ArrayList<WriteModel<Document>>();
InsertOneModel<Document> iom = new InsertOneModel<Document>(new Document("name","kobe"));
UpdateManyModel<Document> umm = new UpdateManyModel<Document>(new Document("name","kobe"),
new Document("$set",new Document("name","James")),new UpdateOptions().upsert(true));
DeleteManyModel<Document> dmm = new DeleteManyModel<Document>(new Document("name","James"));
requests.add(iom);
requests.add(umm);
requests.add(dmm);
BulkWriteResult bulkWriteResult = collection.bulkWrite(requests);
System.out.println(bulkWriteResult.toString());
}
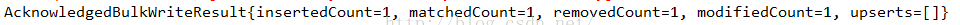
注意:updateMany()、deleteMany()两个方法和insertMany()不同,它俩不是批量操作,而是代表更新(删除)匹配条件的所有数据。
二、与MySQL性能对比
1、插入操作
与MongoDB一样,也是插入Product实体对象,代码如下
public void insertBatch(ArrayList<Product> list) throws Exception{
Connection conn = DBUtil.getConnection();
try {
PreparedStatement pst = conn.prepareStatement("insert into t_product value(?,?,?,?)");
int count = 1;
for (Product product : list) {
pst.setInt(1, product.getProductId());
pst.setString(2, product.getCategory());
pst.setString(3, product.getName());
pst.setDouble(4, product.getPrice());
pst.addBatch();
if(count % 1000 == 0){
pst.executeBatch();
pst.clearBatch();//每1000条sql批处理一次,然后置空PreparedStatement中的参数,这样也能提高效率,防止参数积累过多事务超时,但实际测试效果不明显
}
count++;
}
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
DBUtil.closeConnection(conn);
}
connection.setAutoCommit(false);
public static void main(String[] args) throws Exception {
TestMysql test = new TestMysql();
ArrayList<Product> list = new ArrayList<Product>();
for (int i = 0; i < 1000; i++) {
Product product = new Product(i, "书籍", "追风筝的人", 20.5);
list.add(product);
}
System.out.println("MYSQL开始插入数据。。。");
long insertStart = System.currentTimeMillis();
test.insertBatch(list);
System.out.println("MYSQL插入数据完成,共耗时:"+(System.currentTimeMillis() - insertStart)+"毫秒");
}
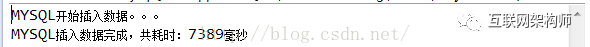
再来看看mysql逐条插入,代码如下:
public void insertOneByOne(ArrayList<Product> list) throws Exception{
Connection conn = DBUtil.getConnection();
try {
for (Product product : list) {
PreparedStatement pst = conn.prepareStatement("insert into t_product value(?,?,?,?)");
pst.setInt(1, product.getProductId());
pst.setString(2, product.getCategory());
pst.setString(3, product.getName());
pst.setDouble(4, product.getPrice());
pst.executeUpdate();
//conn.commit();//加上这句每次插入都提交事务,结果将是非常耗时
}
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
DBUtil.closeConnection(conn);
}
System.out.println("MYSQL开始插入数据。。。");
long insertStart = System.currentTimeMillis();
test.insertOneByOne(list);
System.out.println("MYSQL插入数据完成,共耗时:"+(System.currentTimeMillis() - insertStart)+"毫秒");
2、删除操作
public void deleteBatch(ArrayList<Product> list) throws Exception{
Connection conn = DBUtil.getConnection();
try {
PreparedStatement pst = conn.prepareStatement("delete from t_product where id = ?");//按主键查,否则全表遍历很慢
int count = 1;
for (Product product : list) {
pst.setInt(1, product.getProductId());
pst.addBatch();
if(count % 1000 == 0){
pst.executeBatch();
pst.clearBatch();
}
count++;
}
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
DBUtil.closeConnection(conn);
}
System.out.println("MYSQL开始删除数据。。。");
long deleteStart = System.currentTimeMillis();
test.deleteBatch(list);
System.out.println("MYSQL删除数据完成,共耗时:"+(System.currentTimeMillis() - deleteStart)+"毫秒");
public void deleteOneByOne(ArrayList<Product> list) throws Exception{
Connection conn = DBUtil.getConnection();
PreparedStatement pst = null;
try {
for (Product product : list) {
pst = conn.prepareStatement("delete from t_product where id = ?");
pst.setInt(1, product.getProductId());
pst.executeUpdate();
//conn.commit();//加上这句每次插入都提交事务,结果将是非常耗时
}
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
DBUtil.closeConnection(conn);
}
System.out.println("MYSQL开始删除数据。。。");
long deleteStart = System.currentTimeMillis();
test.deleteOneByOne(list);
System.out.println("MYSQL删除数据完成,共耗时:"+(System.currentTimeMillis() - deleteStart)+"毫秒");
3、更新操作
public void updateBatch(ArrayList<Product> list) throws Exception{
Connection conn = DBUtil.getConnection();
try {
PreparedStatement pst = conn.prepareStatement("update t_product set price=31.5 where id=?");
int count = 1;
for (Product product : list) {
pst.setInt(1, product.getProductId());
pst.addBatch();
if(count % 1000 == 0){
pst.executeBatch();
pst.clearBatch();//每1000条sql批处理一次,然后置空PreparedStatement中的参数,这样也能提高效率,防止参数积累过多事务超时,但实际测试效果不明显
}
count++;
}
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
DBUtil.closeConnection(conn);
}
System.out.println("MYSQL开始更新数据。。。");
long updateStart = System.currentTimeMillis();
test.updateBatch(list);
System.out.println("MYSQL更新数据完成,共耗时:"+(System.currentTimeMillis() - updateStart)+"毫秒");
public void updateOneByOne(ArrayList<Product> list) throws Exception{
Connection conn = DBUtil.getConnection();
try {
for (Product product : list) {
PreparedStatement pst = conn.prepareStatement("update t_product set price=30.5 where id=?");
pst.setInt(1, product.getProductId());
pst.executeUpdate();
//conn.commit();//加上这句每次插入都提交事务,结果将是非常耗时
}
conn.commit();
} catch (SQLException e) {
e.printStackTrace();
}
DBUtil.closeConnection(conn);
}
System.out.println("MYSQL开始更新数据。。。");
long updateStart = System.currentTimeMillis();
test.updateOneByOne(list);
System.out.println("MYSQL更新数据完成,共耗时:"+(System.currentTimeMillis() - updateStart)+"毫秒");
三、总结
原文链接:https://blog.csdn.net/u014513883/article/details/49365987
最后,关注公众号互联网架构师,在后台回复:2T,可以获取我整理的 Java 系列面试题和答案,非常齐全。
正文结束
1.心态崩了!税前2万4,到手1万4,年终奖扣税方式1月1日起施行~

评论