
Python 爬虫进阶必备 | 关于 rs 5 代的分析随笔
第一时间关注Python技术干货!

图源:极简壁纸
写在前面
之前简白大佬说过现在关于某数的分析资料汗牛充栋。
当时还特意去百度了下汗牛充栋是啥意思,其实就是形容资料很多。
的确,现在 web 逆向的大佬越来越多,瑞数之前的 js 逆向天花板也变成二线加密的一员。
大佬们现在也开始挑战更多的高峰了,过年的时候看了下某个站的加密发现失效了,想着过年就不去卷了,年后再看看
年后试了下发现加密没有变化代码又能跑了,但是笔记不能白写,就简单整理发出来

这里再次感谢NTrach佬的帮助~
分析流程
1、搭建调试环境。
分析某数的加密是要先把代码固定下来,所以 Fiddler 的 autoresponse直接整起来,比较简单的方法就是把要分析的页面直接保存一份到本地然后直接替换就可以了

页面上meta content、inner script、script中分别代表的含义大家之前看其他的文章都知道,就不反复说了
2、定位cookie生成位置。
这里比较常用的就是hook定位,直接用编程喵志远大佬的插件就可以了,代码如下
//当前版本hook工具只支持Content-Type为html的自动hook
//下面是一个示例:这个示例演示了hook全局的cookie设置点
(function() {
//严谨模式 检查所有错误
'use strict';
//document 为要hook的对象 这里是hook的cookie
var cookieTemp = "";
Object.defineProperty(document, 'cookie', {
//hook set方法也就是赋值的方法
set: function(val) {
debugger;
//这样就可以快速给下面这个代码行下断点
//从而快速定位设置cookie的代码
console.log('Hook捕获到cookie设置->', val);
cookieTemp = val;
return val;
},
//hook get方法也就是取值的方法
get: function()
{
return cookieTemp;
}
});
})();
使用插件,刷新页面出现如下的情况

当插件hook到已经生成cookie的时候,向上查看堆栈就可以找cookie生成的位置了
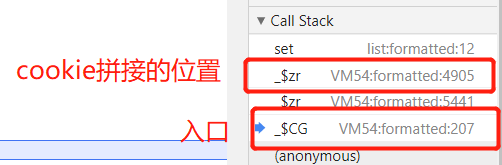
这样就可以初步定位cookie生成的位置了
3、明确调试入口。
在上面的断点中可以知道以下位置的作用,第二个_$zr是cookie拼接的位置,说明运行到这个步骤的时候cookie已经生成好了
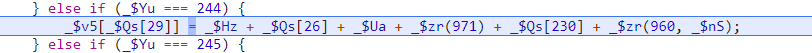
我们需要通过调试理清楚_$zr这一整个步骤都做了什么操作最后才得出了cookie
所以我们的调试入口应该放在的_$CG这一步
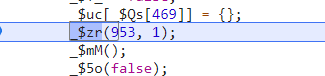
经过了_$zr(953,1)之后就完成了cookie的生成
在上一步单步调试进去之后
就开始控制流混淆了,在这里不会调试的同学只要记住你键盘上只有F11这个键就行了
直到下面这个位置,这里可以看作是入口2

在这一步单步进去之后才开始cookie的生成的前期准备。
有看过其他大佬瑞数文章的朋友,一定知道瑞数的cookie生成和一个128位数组息息相关,这个128位数组经过拼接后计算会生成最后的cookie
在本篇文章中,开始为128位数组写值的过程称之为主流程
4、主流程调试的技巧。
在主流程调试之前进行了以下的一些操作:
4.1、时间戳的差值计算
这一步生成的时间差值会在128位数组中添加一个长度为8的数组
这一步如果是补环境调试的话直接hook返回固定的就行,保证你的环境和页面返回的时间戳一致,不影响调试就行
4.2、自动化检测
这一步主要检测的就是webdriver、selenium和driver,如果你是补环境没用自动化就不用管
window._Selenium_IDE_Recorder
window._selenium
window.callSelenium
document.__driver_evaluate
document.__webdriver_evaluate
document.__selenium_evaluate
document.__fxdriver_evaluate
document.__driver_unwrapped
document.__webdriver_unwrapped
document.__selenium_unwrapped
document.__fxdriver_unwrapped
document.__webdriver_script_func
document.__webdriver_script_fn
4.3、ua 检测
这一步会根据ua计算出一个长度为10的字符串,这个字符串你可以不用和网页上一致,毕竟每个人浏览器不一样,这一步生成的字符串串会在最后参与128位数组第15个数组的生成,会是他值的一小部分
4.4、平台检测
这一步会获取你的平台信息,也就是navigator.platform的值,这里只是获取到值,并没有计算,在主流程中会参与计算
所以如果补环境的话,你懂的
4.5、toString 检测
这一步会获取window.eval.toString()的长度,正常来说浏览器中获取到的长度的是33也就是如下代码的计算结果
window.eval.toString().length
'function eval() { [native code] }'.length
33
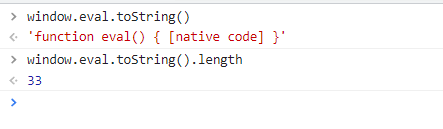
这个如果是补环境的话就需要注意toString保护是否到位
这个数值也会被添加到128位数组中
还有一些零碎的值,是属于加密的前期准备,这步生成的值大多都是有用的
大致检测的范围是navigator、window下的属性
主流程分析
现在回到主流程的调试上来,其他的大佬的文章说的太多了
关于每一个值的生成啥的,都可以参考文末推荐的资料,一篇就够了
其实这一步我都感觉都没啥好说的,所以就主要讲讲调试技巧,大佬们都是肝出来的
我们上面提过本文的主流程就是128数组值的生成
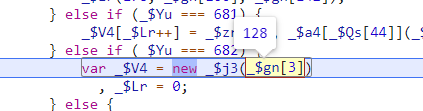
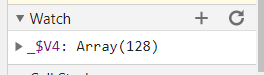
所以在128数组创建之后就要关心,这个数组中的值和我们自己环境生成的是否一致。
所以我们需要watch变量_$V4,观察他的值的变化
这里有一个调试技巧,这个技巧是NTrach佬教给我的
观察堆栈的层数
在生成128位数组的时候,我们注意这个时候_$zr堆栈的层数
如下
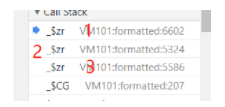
所以当堆栈层数>3的时候都是在写入计算128位数组的一个值
如果你最后生成的值和浏览器一致就没有必要再浪费时间在这一步
通过这样的方法,就可以一步步把_$V4所有值的生成,拆分成很多个小的流程,一步步调试就可以完成128所有值的生成逻辑分析。
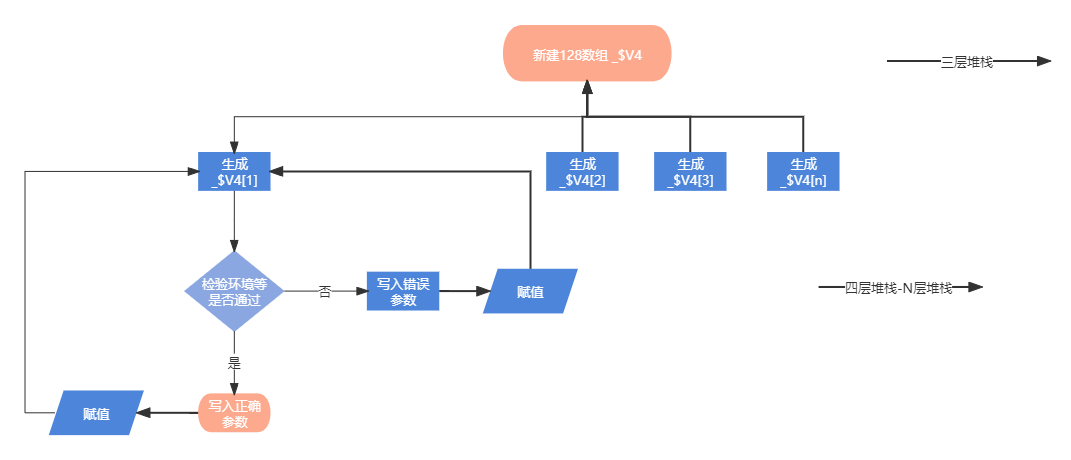
如果128位数组中的值全都对的上,生成的cookie也就没有问题。
以上就是我关于瑞数分析的一点点小技巧。
推荐资料
时一姐 yyds :https://mp.weixin.qq.com/s/VaxSQqKnPQn4gsvrn2O_MQ
好了,以上就是今天的全部内容了。
我是没有更新就在摸鱼的咸鱼
收到请回复~
我们下次再见。
 对了,看完记得一键四连,这个对我真的很重要。
对了,看完记得一键四连,这个对我真的很重要。