
阿里医疗NLP实践与思考

来源:DataFunTalk 本文约8000字,建议阅读10+分钟 本文将从数据、算法、知识3个层面带来阿里在医疗NLP领域的工作、遇到的问题以及相应的思考。

医学影像(国内较为成功的医疗AI公司基本都是医学影像方向); 文本信息抽取和疾病预测(我们今天分享的重点); 病患语音识别和机器翻译(三甲医院医生用话筒讲话,然后ASR语音识别转录成电子病历的内容,通常用到RNN或Seq2Seq的技术实现); 体征监测和疾病风险评估(应用场景包括慢病评估,健康管理等); 新药研发(新冠疫情之后逐渐兴起,目前该领域较为火爆) 手术机器人(交叉学科,一般会涉及到增强学习技术)。
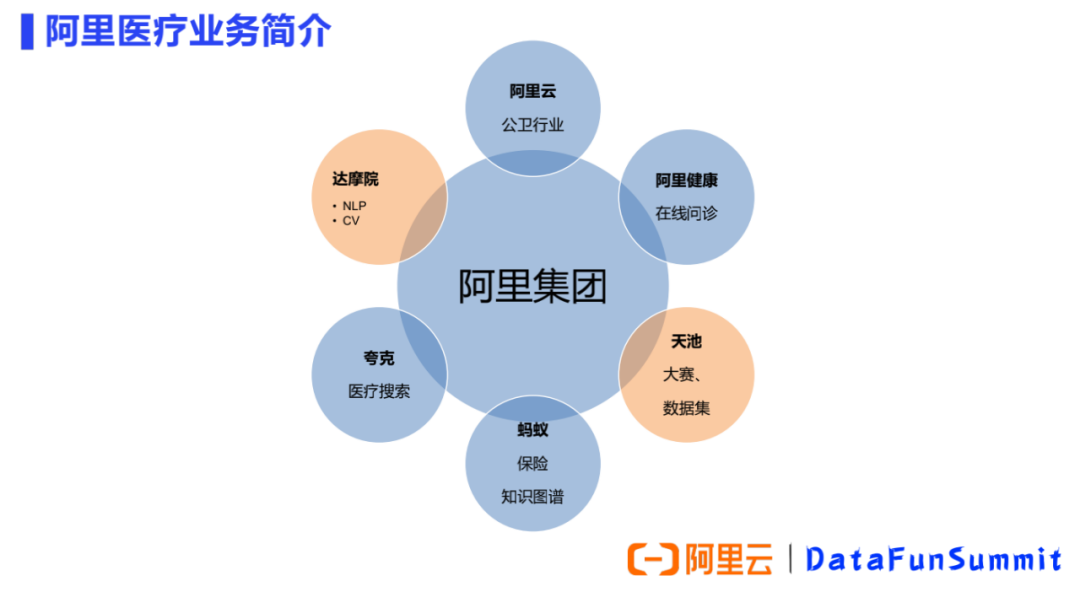
阿里云:面向B端,主要服务于公卫领域如医院、卫健委等智慧医疗的应用场景。 阿里健康:可分为两部分,包括电商售药和互联网在线问诊,其中线上问诊涉及到的自动问答技术与NLP强相关。 蚂蚁保险:在智能理赔过程中,患者上传病历或收据,经OCR识别、文本信息抽取后被用于服务核保核赔预测模型。 夸克浏览器:面向医疗的垂直搜索。 达摩院:两个团队在做医疗AI的业务。①NLP团队:主要负责NLP原子技术能力,服务于阿里集团内的一些业务方、以及阿里云的生态合作伙伴。②华先胜博士所负责的城市大脑团队:主要负责医学影像,根据影像图片做辅助诊疗。 天池:天池大赛的定位是针对人工智能技术尚未成熟的行业,先通过来源于真实场景的数据集把问题提出来,然后征募选手来做比赛方案,相当于做一个先期的技术验证。天池开放了很多行业稀缺的数据集,尤其是医疗行业。
电子病历数据:是讲者处理较多的数据,特点是数据的非标准化和多样性。 药品说明书,检查报告单和体检报告:这3类数据比较规范。 在线问诊,论坛问答:数据质量较差,其特点是口语多,噪音大。患者就诊过程中涉及较多不相关信息,医生的工作主要负责识别、总结有效信息,然后我们再应用NLP去做后续的分析处理。 医学教科书、科研文献:数据比较规范。我们应用NLP技术把文本类内容解析出来。
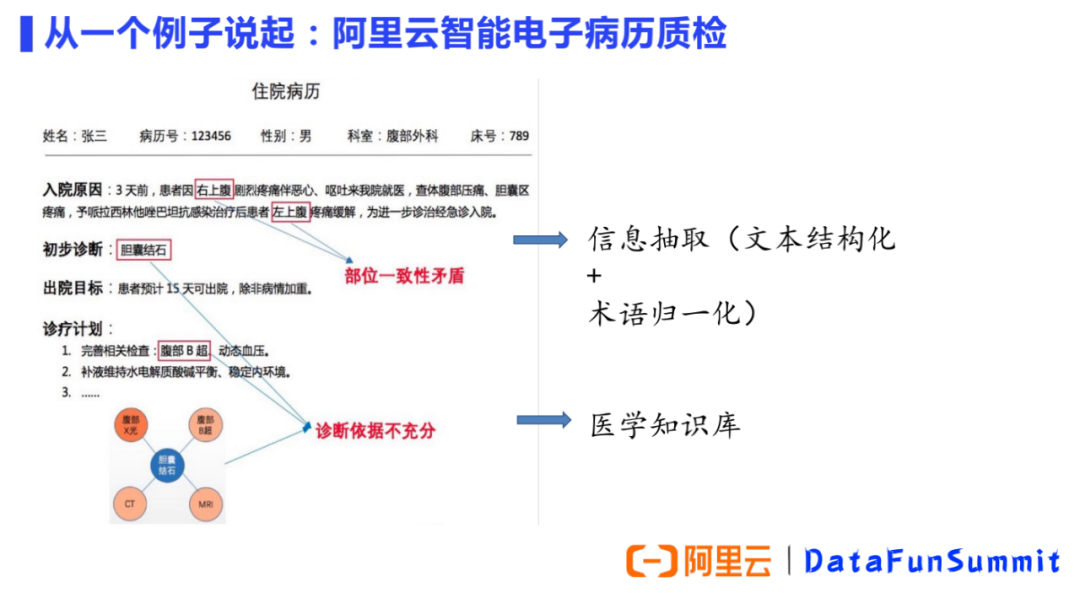
一致性矛盾:患者一开始疼痛的部位是“右”上腹,后来经过治疗“左”上腹疼痛缓解。我们的产品准确的捕捉到患者初始症状出现的部位以及治疗改善的部位不一致。 诊断依据不充分:住院病历中的初步诊断写的是胆囊结石,但是下一步诊疗计划里却出现了腹部B超,可见该患者尚不能明确诊断为胆囊结石。如果临床高度怀疑胆囊结石,初步诊断可写“腹痛待查,胆囊结石?”,而不能只写“胆囊结石”。我们的产品准确的捕捉了诊断依据的不充分。

实体属性:如当前疾病是现病史(现在发生的)还是既往史(过去就有的),症状是阳性(肯定)还是阴性(否定)。传统的方法是使用关系抽取模型,但我们的产品为了追求效率没有用关系抽取的方式,而是用了下图中的模型。 嵌套:如图中的症状中就包含了身体部位,医学文本中有大量嵌套类型的实体存在。 非连续:在药品说明书中大量存在。
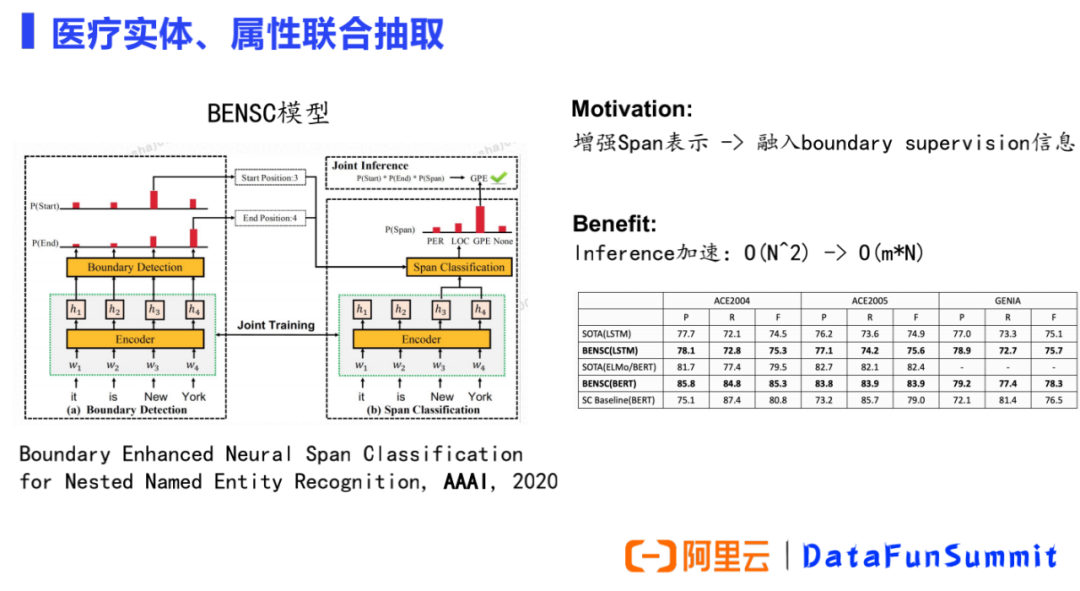
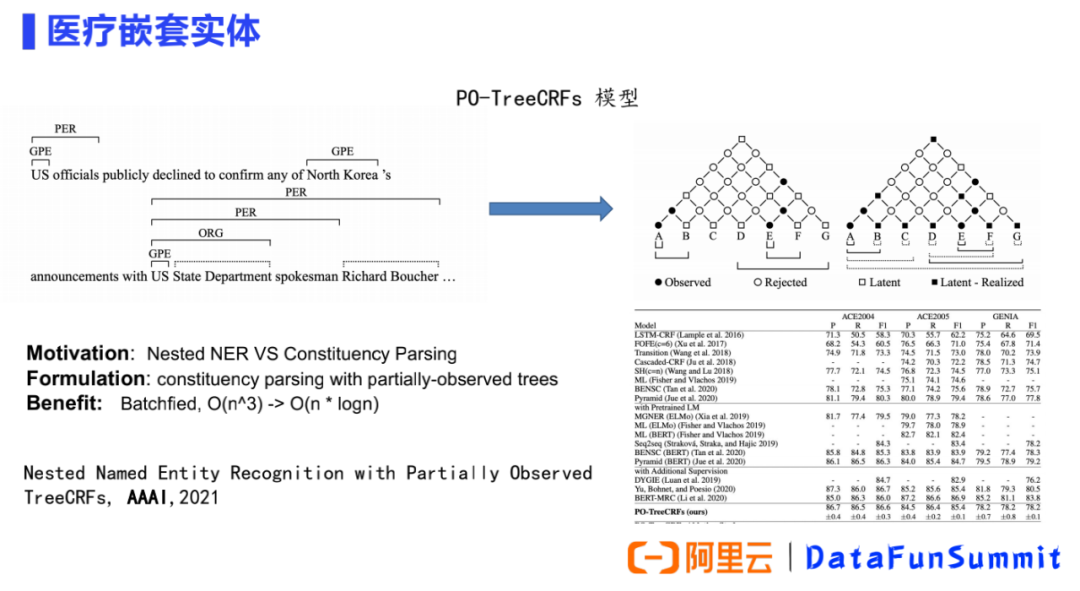
② 基于嵌套实体构建模型:
我们针对医学嵌套实体的特点开展了很多研究的工作,上图是我们发表在AAAI2021的一个工作。我们将嵌套 NER识别问题看作是经典的句法成分分析(constituent parsing)问题, 根据嵌套实体的特点将其视为部分观察(partial observed)到的树,进行选区解析,并使用部分观察到的 TreeCRF 对其进行建模。具体来说,将所有标记的实体span视为选区树中的观察节点(黑点),将其他跨度视为潜在节点(白点)。该模型其中的一个优点是,实现了一种统一的方式来联合建模观察到的和潜在的节点。而另外一个优点是,在进行选区分析时,通过Batchfied将模型复杂度从O(n^3)降为O(nⅹlogn)。

是PTLM应用的另一个场景。例如尽管开塞露的药品说明书的适应症只有便秘,但医生给诊断是肠梗阻的患者使用开塞露也是合理的。这是因为虽然医生的诊断与药品说明书字面上不match,但肠梗阻实际上会导致便秘,所以经过推理医生用药是合理的,而这个推理过程用到的就是医学知识。



CBLUE地址:
https://tianchi.aliyun.com/specials/promotion/2021chinesemedicalnlpleaderboardchallenge

编辑:黄继彦
校对:汪雨晴
评论