
这就是深度学习如此强大的原因

深度学习:神经网络和函数
层的效果
深度学习作为插值
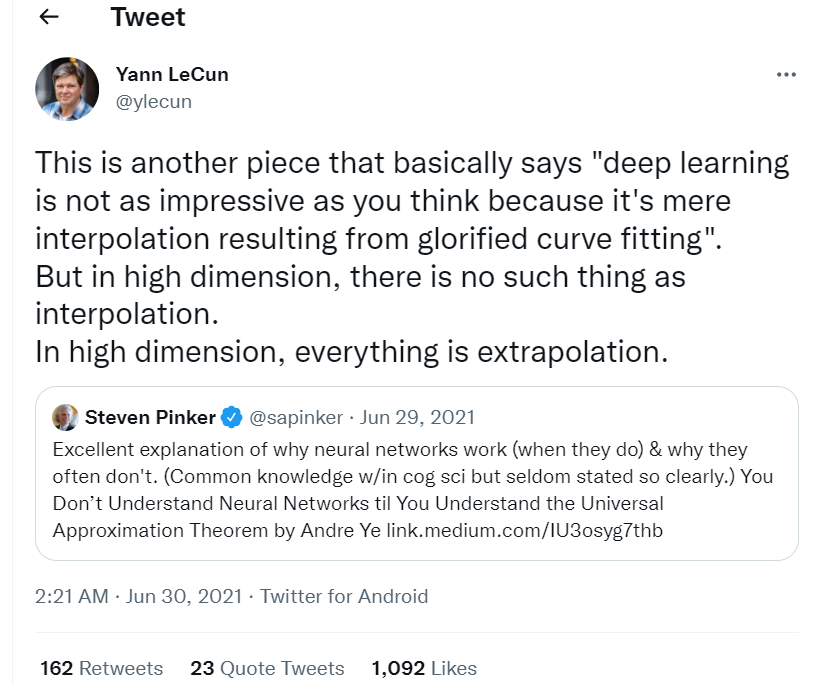
学习方面
确保模型学习通用函数,而不仅仅适合训练数据;这是通过使用正则化处理的;
根据手头的问题,选择损失函数;松散地说,损失函数是我们想要的(真实值)和我们当前拥有的(当前预测)之间的误差函数;
梯度下降是用于收敛到最优函数的算法;决定学习率变得具有挑战性,因为当我们远离最优时,我们想要更快地走向最优,而当我们接近最优时,我们想要慢一些,以确保我们收敛到最优和全局最小值;
大量隐藏层需要处理梯度消失问题;跳过连接和适当的非线性激活函数等架构变化,有助于解决这个问题。
计算挑战
要学习一个复杂的函数,我们需要大量的数据; 为了处理大数据,我们需要快速的计算环境; 我们需要一个支持这种环境的基础设施。

——The End——

分享
收藏
点赞
在看
评论