据报道称,由于采用基于云的技术和在大数据中使用深度学习系统,深度学习的使用在过去十年中迅速增长,预计到 2028 年,深度学习的市场规模将达到 930 亿美元。
深度学习是机器学习的一个子集,它使用神经网络来执行学习和预测。深度学习在各种任务中都表现出了惊人的表现,无论是文本、时间序列还是计算机视觉。深度学习的成功主要来自大数据的可用性和计算能力。然而,不仅如此,这使得深度学习远远优于任何经典的机器学习算法。
深度学习:神经网络和函数
神经网络是一个相互连接的神经元网络,每个神经元都是一个有限函数逼近器。这样,神经网络被视为通用函数逼近器。如果你还记得高中的数学,函数就是从输入空间到输出空间的映射。一个简单的 sin(x) 函数是从角空间(-180° 到 180° 或 0° 到 360°)映射到实数空间(-1 到 1)。
让我们看看为什么神经网络被认为是通用函数逼近器。每个神经元学习一个有限的函数:f(.) = g(W*X) 其中 W 是要学习的权重向量,X 是输入向量,g(.) 是非线性变换。W*X 可以可视化为高维空间(超平面)中的一条线(正在学习),而 g(.) 可以是任何非线性可微函数,如 sigmoid、tanh、ReLU 等(常用于深度学习领域)。在神经网络中学习无非就是找到最佳权重向量 W。例如,在 y = mx+c 中,我们有 2 个权重:m 和 c。现在,根据 2D 空间中点的分布,我们找到满足某些标准的 m & c 的最佳值:对于所有数据点,预测 y 和实际点之间的差异最小。
层的效果
现在每个神经元都是一个非线性函数,我们将几个这样的神经元堆叠在一个「层」中,每个神经元接收相同的一组输入但学习不同的权重 W。因此,每一层都有一组学习函数:[f1, f2, …, fn],称为隐藏层值。这些值再次组合,在下一层:h(f1, f2, ..., fn) 等等。这样,每一层都由前一层的函数组成(类似于 h(f(g(x))))。已经表明,通过这种组合,我们可以学习任何非线性复函数。
深度学习是具有许多隐藏层(通常 > 2 个隐藏层)的神经网络。但实际上,深度学习是从层到层的函数的复杂组合,从而找到定义从输入到输出的映射的函数。例如,如果输入是狮子的图像,输出是图像属于狮子类的图像分类,那么深度学习就是学习将图像向量映射到类的函数。类似地,输入是单词序列,输出是输入句子是否具有正面/中性/负面情绪。因此,深度学习是学习从输入文本到输出类的映射:中性或正面或负面。
深度学习作为插值
从生物学的解释来看,人类通过逐层解释图像来处理世界的图像,从边缘和轮廓等低级特征到对象和场景等高级特征。神经网络中的函数组合与此一致,其中每个函数组合都在学习关于图像的复杂特征。用于图像的最常见的神经网络架构是卷积神经网络 (CNN),它以分层方式学习这些特征,然后一个完全连接的神经网络将图像特征分类为不同的类别。
通过再次使用高中数学,给定一组 2D 数据点,我们尝试通过插值拟合曲线,该曲线在某种程度上代表了定义这些数据点的函数。我们拟合的函数越复杂(例如在插值中,通过多项式次数确定),它就越适合数据;但是,它对新数据点的泛化程度越低。这就是深度学习面临挑战的地方,也就是通常所说的过度拟合问题:尽可能地拟合数据,但在泛化方面有所妥协。几乎所有深度学习架构都必须处理这个重要因素,才能学习在看不见的数据上表现同样出色的通用功能。
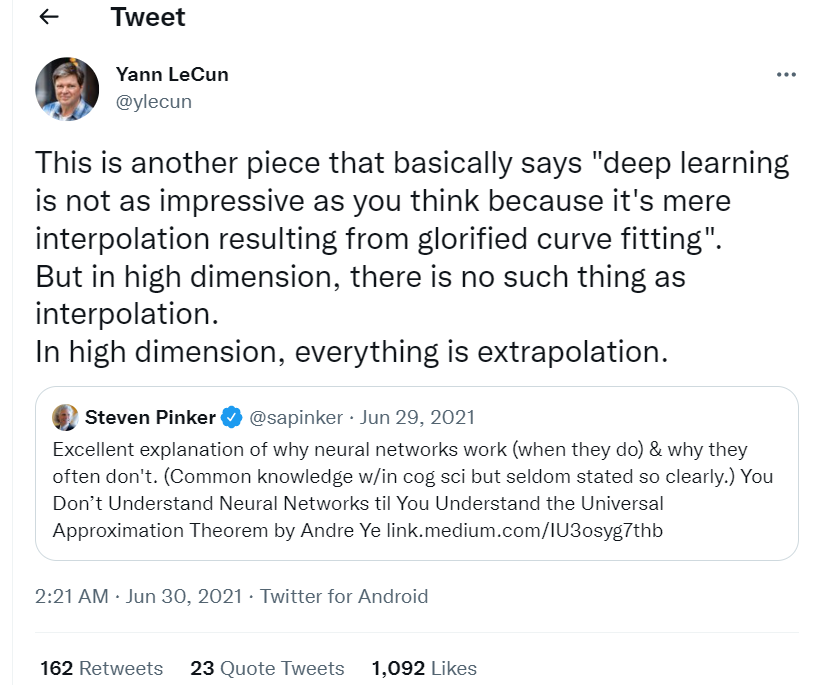
深度学习先驱 Yann LeCun(卷积神经网络的创造者和 ACM 图灵奖获得者)在他的推特上发帖(基于一篇论文):「深度学习并没有你想象的那么令人印象深刻,因为它仅仅是美化曲线拟合的插值。但是在高维中,没有插值之类的东西。在高维空间,一切都是外推。」因此,作为函数学习的一部分,深度学习除了插值,或在某些情况下,外推。就这样!
Twitter 地址:https://twitter.com/ylecun/status/1409940043951742981?lang=en
学习方面
那么,我们如何学习这个复杂的函数呢?这完全取决于手头的问题,而这决定了神经网络架构。如果我们对图像分类感兴趣,那么我们使用 CNN。如果我们对时间相关的预测或文本感兴趣,那么我们使用 RNN 或 Transformer,如果我们有动态环境(如汽车驾驶),那么我们使用强化学习。除此之外,学习还涉及处理不同的挑战:
确保模型学习通用函数,而不仅仅适合训练数据;这是通过使用正则化处理的;
根据手头的问题,选择损失函数;松散地说,损失函数是我们想要的(真实值)和我们当前拥有的(当前预测)之间的误差函数;
梯度下降是用于收敛到最优函数的算法;决定学习率变得具有挑战性,因为当我们远离最优时,我们想要更快地走向最优,而当我们接近最优时,我们想要慢一些,以确保我们收敛到最优和全局最小值;
大量隐藏层需要处理梯度消失问题;跳过连接和适当的非线性激活函数等架构变化,有助于解决这个问题。
计算挑战
现在我们知道深度学习只是一个学习复杂的函数,它带来了其他计算挑战:
使用 CPU 进行并行处理不足以计算数百万或数十亿的权重(也称为 DL 的参数)。神经网络需要学习需要向量(或张量)乘法的权重。这就是 GPU 派上用场的地方,因为它们可以非常快速地进行并行向量乘法。根据深度学习架构、数据大小和手头的任务,我们有时需要 1 个 GPU,有时,数据科学家需要根据已知文献或通过测量 1 个 GPU 的性能来做出决策。
通过使用适当的神经网络架构(层数、神经元数量、非线性函数等)以及足够大的数据,深度学习网络可以学习从一个向量空间到另一个向量空间的任何映射。这就是让深度学习成为任何机器学习任务的强大工具的原因。
参考内容:https://venturebeat.com/2022/03/27/this-is-what-makes-deep-learning-so-powerful/
本文仅做学术分享,如有侵权,请联系删文。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~