点击关注公众号,Java干货及时送达
在本文中,您将了解在 Kubernetes 上运行 Java 应用程序的最佳实践。大多数这些建议也适用于其他语言。但是,我正在考虑 Java 特性范围内的所有规则,并且还展示了可用于基于 JVM 的应用程序的解决方案和工具。当使用最流行的 Java 框架(如 Spring Boot 或 Quarkus)时,这些 Kubernetes 建议中的一些是设计强制的。我将向您展示如何有效地利用它们来简化开发人员的生活。
1、不要将 Limit 设置得太低
我们是否应该为 Kubernetes 上的 Java 应用设置 limit ?答案似乎显而易见。有许多工具可以验证您的 Kubernetes YAML 清单,如果您没有设置 CPU 或内存 limit ,它们肯定会打印警告。不过,社区对此也有一些“热议”。这是一篇有趣的文章,不建议设置任何 CPU limit 。这是另一篇文章,作为对上一篇文章的对比,他们考虑 CPU limit 。但我们也可以针对内存 limit 开始类似的讨论。特别是在 Java 应用程序的上下文中。然而,对于内存管理,这个命题似乎大不相同。让我们阅读另一篇文章——这次是关于内存 limit 和 request 的。简而言之,它建议始终设置内存 limit。此外,限制应与 request 相同。在 Java 应用程序的上下文中,我们可以使用 -Xmx 、 -XX:MaxMetaspaceSize 或 -XX:ReservedCodeCacheSize 等 JVM 参数限制内存也很重要。无论如何,从 Kubernetes 的角度来看,pod 接收它 request 的资源。Limit 与它无关。这一切让我得出了今天的第一个建议—A—不要将你的 limit 设置得太低。即使您设置了 CPU limit ,也不应该影响您的应用程序。例如,您可能知道,即使您的 Java 应用程序在正常工作中不会消耗太多 CPU,但它需要大量 CPU 才能快速启动。对于我在 Kubernetes 上连接 MongoDB 的简单 Spring Boot 应用程序,无限制和甚至 0.5 核之间的差异是显着的。通常它在 10 秒以下开始:将 CPU limit 设置为 500 millicores ,它开始大约 30 秒:当然,我们可以找到一些例子。但我们也会在下一节中讨论它们。2、首先考虑内存使用
让我们只关注内存 limit 。如果您在 Kubernetes 上运行 Java 应用程序,则有两个级别的最大使用 limit :容器和 JVM。但是,如果您没有为 JVM 指定任何设置,也有一些默认值。如果您不设置 -Xmx 参数,JVM 会将其最大堆大小设置为可用 RAM 的大约 25%。该值是根据容器内可见的内存计算的。一旦您不在容器级别设置 limit ,JVM 将看到节点的整个内存。在 Kubernetes 上运行应用程序之前,您至少应该测量它在预期负载下消耗了多少内存。幸运的是,有一些工具可以优化在容器中运行的 Java 应用程序的内存配置。例如,Paketo Buildpacks 带有内置内存计算器,它使用公式 Heap = 总容器内存 - Non-Heap - Headroom 计算 JVM 的 -Xmx 参数。另一方面,非堆值是使用以下公式计算的:Non-Heap = Direct Memory + Metaspace + Reserved Code Cache + (Thread Stack * Thread Count) 。Paketo Buildpacks 目前是构建 Spring Boot 应用程序的默认选项(使用 mvn spring-boot:build-image 命令)。让我们为我们的示例应用程序尝试一下。假设我们将内存限制设置为 512M,它将在 130M 的级别计算 -Xmx 。我的应用程序可以吗?我至少应该执行一些负载测试来验证我的应用程序在高流量下的性能。但再一次 - 不要将 limit 设置得太低。例如,对于 1024M 限制, -Xmx 等于 650M。如您所见,我们使用 JVM 参数处理内存使用情况。它可以防止我们在第一节提到的文章中描述的 OOM kills 。因此,将 request 设置为与 limit 相同的级别并没有太大意义。我建议将其设置为比正常使用高一点——比方说多 20%。3、适当的 liveness 和 readiness 探针
3.1 介绍
了解 Kubernetes 中的 liveness 和 readiness 探针之间的区别至关重要。如果这两个探针都没有仔细实施,它们可能会降低服务的整体运行,例如导致不必要的重启。第三种类型的探针,启动探针,是 Kubernetes 中一个相对较新的特性。它允许我们避免在 liveness 或 readiness 探针上设置 initialDelaySeconds ,因此如果您的应用程序启动需要很长时间,它特别有用。有关 Kubernetes 探针的一般和最佳实践的更多详细信息,我可以推荐那篇非常有趣的文章。Liveness 探针用于决定是否重启容器。如果应用程序因任何原因不可用,有时重启容器是有意义的。另一方面,readiness 探针用于确定容器是否可以处理传入流量。如果一个 pod 被识别为未就绪,它将被从负载平衡中移除。readiness 探针失败不会导致 pod 重启。Web 应用程序最典型的 liveness 或 readiness 探针是通过 HTTP 端点实现的。由于 liveness 探针的后续失败会导致 pod 重新启动,因此它不应检查您的应用程序集成的可用性。这些事情应该由 readiness 验证。3.2 配置详情
好消息是,最流行的 Java 框架(如 Spring Boot 或 Quarkus)提供了两种 Kubernetes 探针的自动配置实现。他们遵循最佳实践,因此我们通常不必了解基础知识。但是,在 Spring Boot 中,除了包含 Actuator 模块之外,您还需要使用以下属性启用它们:management: endpoint: health: probes: enabled: true
由于 Spring Boot Actuator 提供了多个端点(例如 metric、 trace),因此最好将其公开在与默认端口不同的端口(通常为 8080 )。当然,同样的规则也适用于其他流行的 Java 框架。另一方面,一个好的做法是检查您的主要应用程序端口——尤其是在 readiness 探针中。因为它定义了我们的应用程序是否准备好处理传入的请求,所以它也应该在主端口上监听。它与 liveness probe 看起来正好相反。如果整个工作线程池都很忙,我不想重新启动我的应用程序。我只是不想在一段时间内收到传入流量。我们还可以自定义 Kubernetes 探针的其他方面。假设我们的应用程序连接到外部系统,但我们没有在我们的 readiness 探针中验证该集成。它并不重要,不会对我们的运营状态产生直接影响。这是一个配置,它允许我们在探针中仅包含选定的集成集 (1),并在主服务器端口上公开 readiness 情况 (2) 。spring: application: name: sample-spring-boot-on-kubernetes data: mongodb: host: ${MONGO_URL} port: 27017 username: ${MONGO_USERNAME} password: ${MONGO_PASSWORD} database: ${MONGO_DATABASE} authentication-database: admin
management: endpoint.health: show-details: always group: readiness: include: mongo # (1) additional-path: server:/readiness # (2) probes: enabled: true server: port: 8081
几乎没有任何应用可以不依赖外部解决方案(如数据库、消息代理或其他应用程序)。在配置 readiness 探针时,我们应该仔细考虑到该系统的连接设置。首先你应该考虑外部服务不可用的情况。你将如何处理?我建议将这些超时减少到较低的值,如下所示。spring: application: name: sample-spring-kotlin-microservice datasource: url: jdbc:postgresql://postgres:5432/postgres username: postgres password: postgres123 hikari: connection-timeout: 2000 initialization-fail-timeout: 0 jpa: database-platform: org.hibernate.dialect.PostgreSQLDialect rabbitmq: host: rabbitmq port: 5672 connection-timeout: 2000
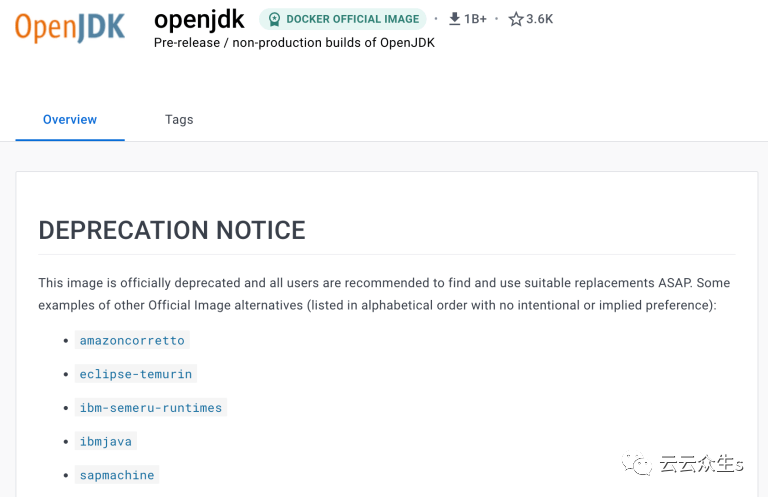
4、选择合适的 JDK
如果您已经使用 Dockerfile 构建了镜像,那么您可能使用的是来自 Docker Hub 的官方 OpenJDK 基础镜像。然而,目前,镜像网站上的公告称它已被正式弃用,所有用户都应该找到合适的替代品。我想这可能会让人很困惑,所以你会在这里找到对原因的详细解释。好吧,让我们考虑一下我们应该选择哪个备选方案。不同的供应商提供多种替代品。如果您正在寻找它们之间的详细比较,您应该访问以下站点。17版本推荐使用 Eclipse Temurin。另一方面,Jib 或 Cloud Native Buildpacks 等最流行的镜像构建工具会自动为您选择供应商。默认情况下,Jib 使用 Eclipse Temurin,而 Paketo Buildpacks 使用 Bellsoft Liberica 实现。当然,您可以轻松地覆盖这些设置。我认为,例如,如果您在与 JDK 提供程序(如 AWS 和 Amazon Corretto)匹配的环境中运行您的应用程序,这可能是有意义的。假设我们使用 Paketo Buildpacks 和 Skaffold 在 Kubernetes 上部署 Java 应用程序。为了将默认的 Bellsoft Liberica buildpack 替换为另一个,我们只需要在 buildpacks 部分中逐字设置它。下面是一个利用 Amazon Corretto buildpack 的示例。apiVersion: skaffold/v2beta22kind: Configmetadata: name: sample-spring-boot-on-kubernetesbuild: artifacts: - image: piomin/sample-spring-boot-on-kubernetes buildpacks: builder: paketobuildpacks/builder:base buildpacks: - paketo-buildpacks/amazon-corretto - paketo-buildpacks/java env: - BP_JVM_VERSION=17
我们还可以使用不同的 JDK 供应商轻松测试我们的应用程序的性能。如果您正在寻找此类比较的示例,您可以阅读我描述此类测试和结果的文章。我使用几个可用的 Paketo Java 构建包测量了与 Mongo 数据库交互的 Spring Boot 3 应用程序的不同 JDK 性能。5、考虑迁移到原生编译
原生编译是 Java 世界中真正的“游戏规则改变者”。但我敢打赌,你们中没有多少人使用它——尤其是在生产中。当然,在将现有应用程序迁移到本机编译的过程中存在(现在仍然存在)许多挑战。GraalVM 在构建期间执行的静态代码分析可能会导致类似 ClassNotFound 或 MethodNotFound 的错误。为了克服这些挑战,我们需要提供一些提示让 GraalVM 了解代码的动态元素。这些提示的数量通常取决于库的数量和应用程序中使用的语言功能的一般数量。像 Quarkus 或 Micronaut 这样的 Java 框架试图通过设计解决与原生编译相关的挑战。例如,他们尽可能避免使用反射。Spring Boot 还通过 Spring Native 项目大大改进了原生编译支持。因此,我在这方面的建议是,如果您要创建一个新的应用程序,请按照为本机编译做好准备的方式进行准备。例如,使用 Quarkus,您可以简单地生成一个 Maven 配置,其中包含用于构建原生可执行文件的专用配置文件。<profiles> <profile> <id>native</id> <activation> <property> <name>native</name> </property> </activation> <properties> <skipITs>false</skipITs> <quarkus.package.type>native</quarkus.package.type> </properties> </profile></profiles>
$ mvn clean package -Pnative
然后你可以分析在构建过程中是否有任何问题。即使您现在不在生产环境中运行原生应用程序(例如您的组织不批准它),您也应该将 GraalVM 编译作为您接受管道中的一个步骤。您可以使用最流行的框架轻松地为您的应用程序构建 Java 原生镜像。例如,使用 Spring Boot,您只需在 Maven pom.xml 中提供以下配置,如下所示:<plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>build-info</goal> <goal>build-image</goal> </goals> </execution> </executions> <configuration> <image> <builder>paketobuildpacks/builder:tiny</builder> <env> <BP_NATIVE_IMAGE>true</BP_NATIVE_IMAGE> <BP_NATIVE_IMAGE_BUILD_ARGUMENTS> --allow-incomplete-classpath </BP_NATIVE_IMAGE_BUILD_ARGUMENTS> </env> </image> </configuration></plugin>
6、正确配置日志记录
在编写 Java 应用程序时,日志记录可能不是您首先考虑的事情。然而,在全局范围内,它变得非常重要,因为我们需要能够收集、存储数据,并最终快速搜索和呈现特定条目。最佳做法是将应用程序日志写入标准输出 (stdout) 和标准错误 (stderr) 流。Fluentd 是一种流行的开源日志聚合器,它允许您从 Kubernetes 集群收集日志、处理它们,然后将它们发送到您选择的数据存储后端。它与 Kubernetes 部署无缝集成。Fluentd 尝试将数据结构化为 JSON 以统一不同来源和目的地的日志记录。假设那样,最好的方法可能是以这种格式准备日志。使用 JSON 格式,我们还可以轻松地包含用于标记日志的附加字段,然后使用各种条件在可视化工具中轻松搜索它们。为了将我们的日志格式化为 Fluentd 可读的 JSON,我们可以在 Maven 依赖项中包含 Logstash Logback 编码器库。<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>7.2</version></dependency>
然后我们只需要在文件 logback-spring.xml 中为我们的 Spring Boot 应用程序设置一个默认的控制台日志 Appender 。<configuration> <appender name="consoleAppender" class="ch.qos.logback.core.ConsoleAppender"> <encoder class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <logger name="jsonLogger" additivity="false" level="DEBUG"> <appender-ref ref="consoleAppender"/> </logger> <root level="INFO"> <appender-ref ref="consoleAppender"/> </root></configuration>
我们是否应该避免使用额外的日志 appenders ,而只是将日志打印到标准输出?根据我的经验,答案是——不。您仍然可以使用其他机制来发送日志。特别是如果您使用不止一种工具来收集组织中的日志——例如 Kubernetes 上的内部堆栈和外部的全局堆栈。就个人而言,我正在使用一种工具来帮助我解决性能问题,例如消息代理作为代理。在 Spring Boot 中,我们可以轻松地使用 RabbitMQ。只需包括以下 starter:<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId></dependency>
然后你需要在 logback-spring.xml 中提供一个类似的 appender 配置:<?xml version="1.0" encoding="UTF-8"?><configuration>
<springProperty name="destination" source="app.amqp.url" />
<appender name="AMQP" class="org.springframework.amqp.rabbit.logback.AmqpAppender"> <layout> <pattern>{ "time": "%date{ISO8601}", "thread": "%thread", "level": "%level", "class": "%logger{36}", "message": "%message"} </pattern> </layout>
<addresses>${destination}</addresses> <applicationId>api-service</applicationId> <routingKeyPattern>logs</routingKeyPattern> <declareExchange>true</declareExchange> <exchangeName>ex_logstash</exchangeName>
</appender>
<root level="INFO"> <appender-ref ref="AMQP" /> </root>
</configuration>
7、创建集成测试
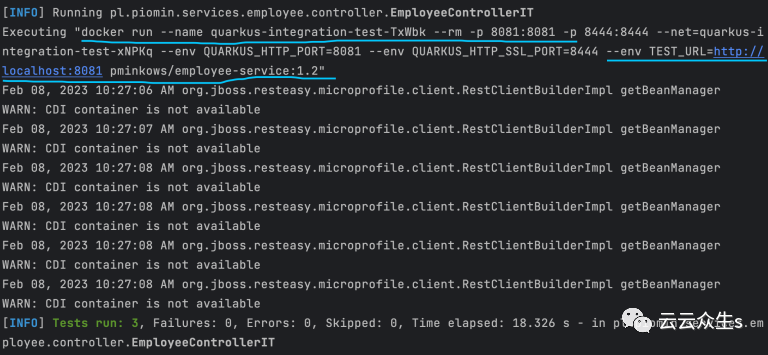
好的,我知道——它与 Kubernetes 没有直接关系。但是由于我们使用 Kubernetes 来管理和编排容器,我们还应该对容器进行集成测试。幸运的是,使用 Java 框架,我们可以大大简化该过程。例如,Quarkus 允许我们用 @QuarkusIntegrationTest 注释测试。结合 Quarkus 容器构建功能,它是一个非常强大的解决方案。我们可以针对包含该应用程序的已构建镜像运行测试。首先,让我们包含 Quarkus Jib 模块:<dependency> <groupId>io.quarkus</groupId> <artifactId>quarkus-container-image-jib</artifactId></dependency>
然后我们必须通过在 application.properties 文件中将 quarkus.container-image.build 属性设置为 true 来启用容器构建。在测试类中,我们可以使用 @TestHTTPResource 和 @TestHTTPEndpoint 注解注入测试服务器 URL。然后我们使用 RestClientBuilder 创建一个客户端并调用在容器上启动的服务。测试类的名字不是偶然的。为了被自动检测为集成测试,它有 IT 后缀。@QuarkusIntegrationTestpublic class EmployeeControllerIT {
@TestHTTPEndpoint(EmployeeController.class) @TestHTTPResource URL url;
@Test void add() { EmployeeService service = RestClientBuilder.newBuilder() .baseUrl(url) .build(EmployeeService.class); Employee employee = new Employee(1L, 1L, "Josh Stevens", 23, "Developer"); employee = service.add(employee); assertNotNull(employee.getId()); }
@Test public void findAll() { EmployeeService service = RestClientBuilder.newBuilder() .baseUrl(url) .build(EmployeeService.class); Set<Employee> employees = service.findAll(); assertTrue(employees.size() >= 3); }
@Test public void findById() { EmployeeService service = RestClientBuilder.newBuilder() .baseUrl(url) .build(EmployeeService.class); Employee employee = service.findById(1L); assertNotNull(employee.getId()); }}
您可以在我之前关于使用 Quarkus 进行高级测试的文章中找到有关该过程的更多详细信息。最终效果如下图所示。当我们在构建期间使用 mvn clean verify 命令运行测试时,我们的测试在构建容器镜像后执行。该 Quarkus 功能基于 Testcontainers 框架。我们还可以将 Testcontainer 与 Spring Boot 一起使用。这是 Spring REST 应用程序及其与 PostgreSQL 数据库集成的示例测试。@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)@Testcontainers@TestMethodOrder(MethodOrderer.OrderAnnotation.class)public class PersonControllerTests {
@Autowired TestRestTemplate restTemplate;
@Container static PostgreSQLContainer<?> postgres = new PostgreSQLContainer<>("postgres:15.1") .withExposedPorts(5432);
@DynamicPropertySource static void registerMySQLProperties(DynamicPropertyRegistry registry) { registry.add("spring.datasource.url", postgres::getJdbcUrl); registry.add("spring.datasource.username", postgres::getUsername); registry.add("spring.datasource.password", postgres::getPassword); }
@Test @Order(1) void add() { Person person = Instancio.of(Person.class) .ignore(Select.field("id")) .create(); person = restTemplate.postForObject("/persons", person, Person.class); Assertions.assertNotNull(person); Assertions.assertNotNull(person.getId()); }
@Test @Order(2) void updateAndGet() { final Integer id = 1; Person person = Instancio.of(Person.class) .set(Select.field("id"), id) .create(); restTemplate.put("/persons", person); Person updated = restTemplate.getForObject("/persons/{id}", Person.class, id); Assertions.assertNotNull(updated); Assertions.assertNotNull(updated.getId()); Assertions.assertEquals(id, updated.getId()); }
}
8、最后的想法
我希望这篇文章能帮助您在 Kubernetes 上运行 Java 应用程序时避免一些常见的陷阱。将其视为我在类似文章中找到的其他人的建议以及我在该领域的个人经验的总结。
转自:云云众生s / 岱军,
英文链接:piotrminkowski.com/2023/02/13/best-practices-for-java-apps-on-kubernetes/