
SpringCloud 应用在 Kubernetes 上的最佳实践 — 线上发布(可监控)
共 2856字,需浏览 6分钟
·
2020-09-06 15:33
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 阿里云云栖社区
来源 | urlify.cn/ANzUFv
简介: 本篇是“SpringCloud 应用在 Kubernetes 上的最佳实践”系列文章的第六篇,主要介绍了如何保障生产环境服务稳定,做到随时发布,从而加快业务的迭代和上线速度。
前言
在应用发布上线的时候我们最担心的莫过于因为代码的bug引发业务的问题,虽然我们可以通过灰度的方式分批发布减小影响范围,但是如果能够在发布的过程中从实时监控中快速的发现问题进行回滚,那么就能缩短业务受影响的时间。因此我们可以看到灰度、监控、回滚是整个发布过程中不可或缺的三大利器,有了这三大利器后,我们能够做到随时发布,从而加快业务的迭代和上线速度。而监控作为基础设施的一个重要环节,是保障生产环境服务稳定不可或缺的一部分,目前EDAS提供了非常丰富的监控能力,下面我们从不同的场景来详细介绍一下这些监控能力。
体系化监控能力搭建
监控体系,最怕的就是有覆盖不到的地方,一个覆盖全面的监控应该是从基础设施到上层应用均有对应的手段去覆盖:
首先,如果故障产生时,最先感知到的其实是业务的受损,如交易量下跌、登陆的 UV 下跌等等。
而如果继续往下钻,如果业务集群很大的时候,我们最先需要定位到某一个服务或者某一台机器,这个过程如果没有相应的工具相佐犹如大海捞针,所以一个分布式链路级别的应用监控会是建设 Spring Cloud 应用的很好的配搭。
等到我们找到了相应的服务要开始进行定位分析的时候,根据问题类型(是错是慢?)接下来需要开始分析 JVM、内存、CPU 等维度的指标。
最后我们可能会发现这个问题是由于业务代码引起,也有可能由于基础设施引起,而在 K8S 中,Prometheus 目前是属于容器领域基础监控最厉害的军刀。

如上图所示,目前 EDAS 结合阿里云上的某些云产品,完全能够满足日常的运维的需要并帮忙业务开发的同学快速的定位线上问题。
EDAS常规监控能力
系统监控
应用实例的基础监控信息:
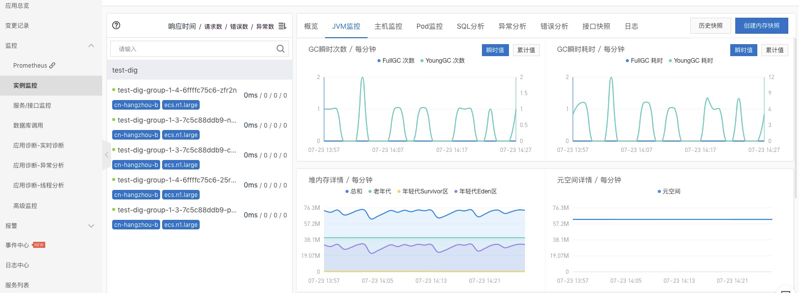
上图功能提供了以应用实例的维度来查看每个实例的监控信息,提供的JVM/CPU/Load/内存等的监控信息也是我们经常需要关注的,当发现内存占用高,并且有频繁的FullGCC的情况时,我们可以通过创建内存快照进行分析来快速定位问题。SQL分析的能力也能快速帮助我们定位到慢查询用来排查问题。
应用服务监控
应用服务接口监控信息:
这里提供了以接口维度的监控信息,可以详细的看到接口在最近一段时间的请求信息,这里重点介绍一下接口快照功能,通过接口快照我们可以看到该接口的请求耗时,以及请求的TraceId,根据这个TraceId我们可以详细的看到本次请求的调用链以及调用的方法栈。
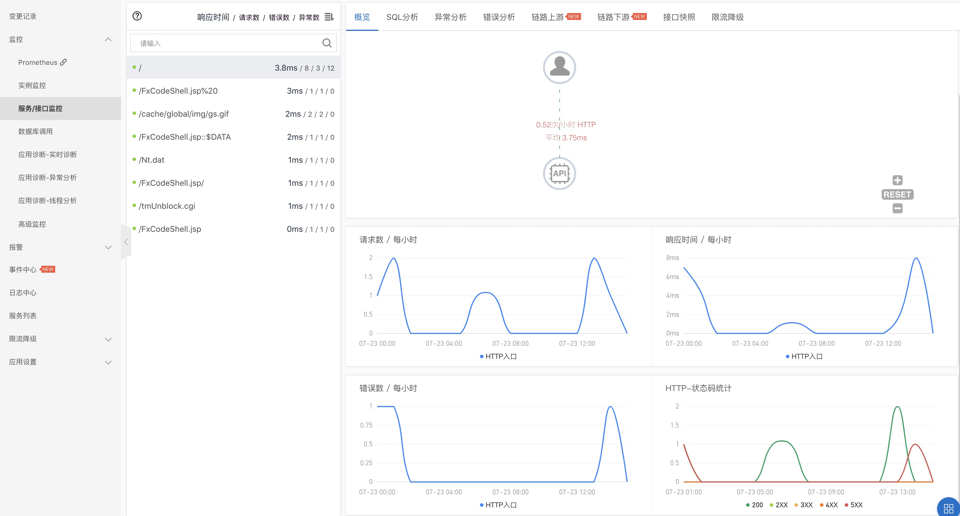
这里提供了以接口维度的监控信息,可以详细的看到接口在最近一段时间的请求信息,这里重点介绍一下接口快照功能,通过接口快照我们可以看到该接口的请求耗时,以及请求的TraceId,根据这个TraceId我们可以详细的看到本次请求的调用链以及调用的方法栈。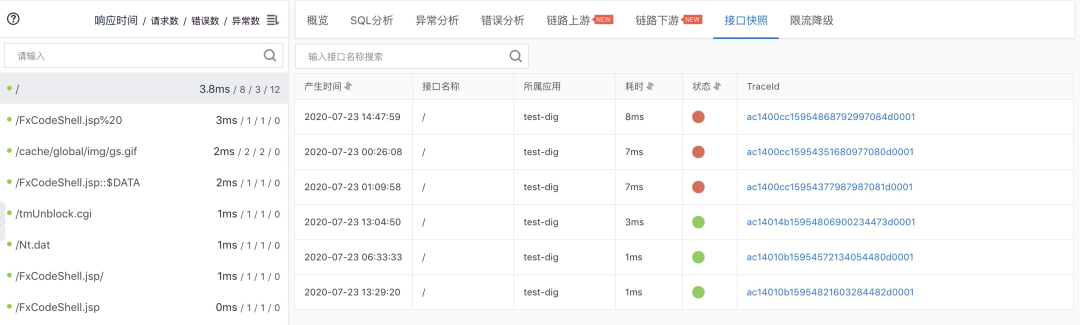

调用链路的追踪在分布式系统下是一个必不可少的工具,尤其是在排查上下游依赖中究竟是哪个系统拖慢了整个请求非常有用,在调用的方法栈中可以直观的追踪到调用出错的地方。
应用业务监控
在EDAS中我们支持应用自定义业务监控,这需要我们开启高级监控的能力。从业务的视角来衡量应用的性能和稳定性,可以通过自定义来采集业务信息,来实时展现业务指标,帮助业务进一步完善监控信息。详细的监控配置可以参考ARMS业务监控。
Prometheus监控
监控产品的历史由来已久,但是随着云原生技术的持续火热,Prometheus 作为新生代的开源监控系统,慢慢成为了云原生体系的事实标准。而在EDAS中的高级监控产品ARMS已经全面对接开源Prometheus生态,支持类型丰富的组件监控,提供多种开箱即用的预置监控大盘,且提供全面托管的Prometheus服务,更多的详细内容可以参考ARMS Prometheus
通过以上这些监控能力,可以大大缩短线上问题从发现到定位再到解决的时间,提高开发和运维人员排查和解决问题的效率。
EDAS应用发布场景中的监控
以阿里巴巴集团的经验举例子,超一半以上的大故障都是在发布过程中产生,EDAS 针对发布这一场景结合 Kubernetes 的能力做了结合,其中的精髓内容总结三个词:先发、再看、再发。通俗的解释就是可以利用 EDAS 中分批(灰度)发布能力,同时在发布视图中,确保相关的指标回归正常之后,再开始下一批发布了。
目前EDAS能够提供在三个维度上的指标监控数据,用来判断发布是否正常,列举如下:
应用业务指标
目前EDAS以接口的维度提供了每个接口在发布前后的总的请求数对比以及请求该比例的图例,并且还能够详细的看到在发布前后该接口的错误数、响应时间以及单机的请求数对比,如下图所示:
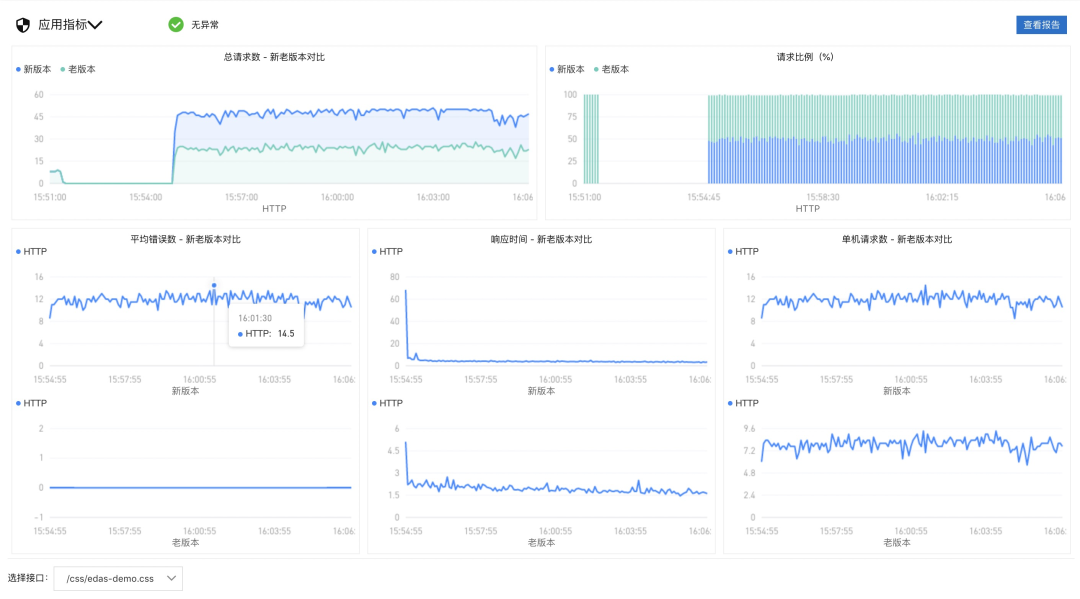
通过上图,我们可以直观的看到,当我们发布后应用的接口请求是否正常,以此来判断是否会对业务产生影响。
应用异常
在发布的过程中,我们也需要时刻的关注在发布中是不是有新的异常产生,我们想要有地方能够看到异常信息,避免直接登录到机器上去看业务日志,我们的发布监控提供了日志聚合分析的能力,可以在发布的过程提供实时的异常日志分析展示,如下图所以:

系统指标
在新的业务功能上线的时候,我们除了对业务本身的一些异常和指标进行关注外,还需要关注系统的指标,这关系到我们需要评估现有的机器是否能够支撑我们的所有流量,是否需要进行水平扩容来更好的支持业务,我们的发布监控系统同样集成了系统的监控的能力,为我们的发布过程来保驾护航,详细的监控如下图所示:
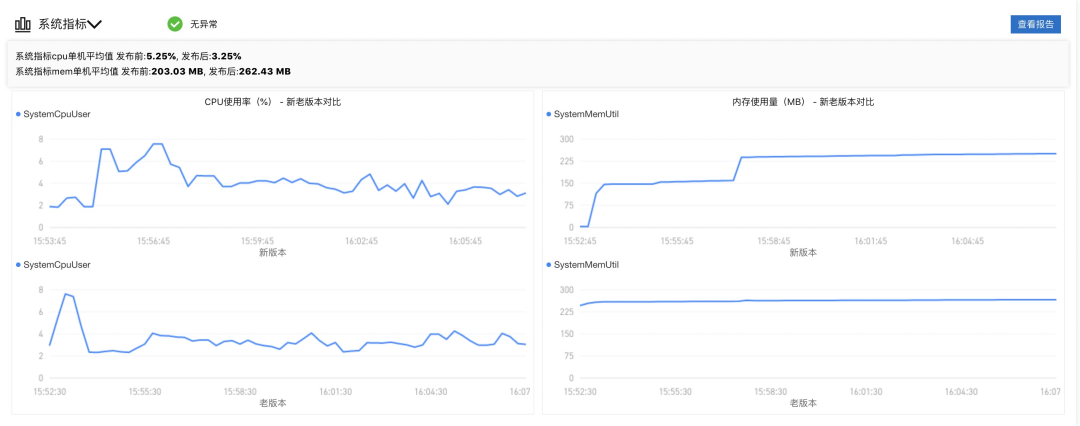
以上内容我们通过三个维度为大家展示了在整个发布的过程中EDAS为我们提供的完备的监控能力,通过这个能力可以让我们的每一次发布都能做到不慌不忙,心中有数,每一次发布都能平滑让业务进行升级。同时我们也提供了查看发布报告的功能,将发布监控信息形成了一份清晰的可视化分析报告供分享他人。
后续及结语
本章我们介绍了EDAS中提供的监控能力以及如何对EDAS Kubernetes集群上的Spring Cloud应用在发布的过程中如何看监控发现异常信息,但是如果出现异常了该怎么办呢?接下来的文章我们将继续介绍,当出现问题后我们如何对已经发布的应用进行快速的回滚。


感谢点赞支持下哈 