Bengio、Hinton的不懈追求——深度学习算法揭示大脑如何学习

“如果我们能够揭示大脑的某些学习机制或学习方法,那么人工智能将能迎来进一步的发展,”Bengio如是说。
编译 | Don
来源 | AI科技评论


1
使用反向传播进行学习

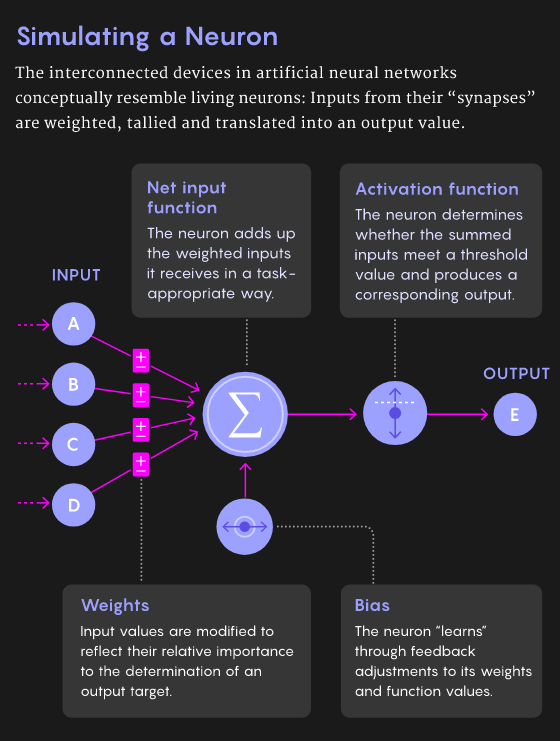
2
人脑不可能使用反向传播机制
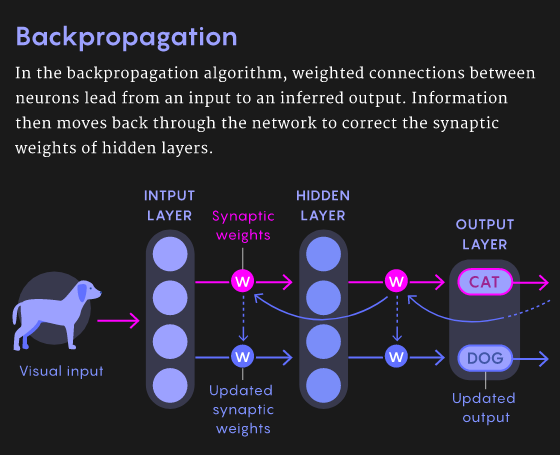
3
更符合生物特性的学习机制
4
预测感知
5
椎体神经元

6
注意力机制


评论

“如果我们能够揭示大脑的某些学习机制或学习方法,那么人工智能将能迎来进一步的发展,”Bengio如是说。
编译 | Don
来源 | AI科技评论
使用反向传播进行学习
人脑不可能使用反向传播机制
更符合生物特性的学习机制
预测感知
椎体神经元
注意力机制