
用 Python 展示全国高校的分布情况
在公众号后台回复:JGNB,可获取杰哥原创的 PDF 手册。
文末获取本文完整数据
6月是毕业季,高考生正在准备填志愿。本文用Python展示了全国高校的分布情况,全国的高校哪些地方多,哪些地方少,可以一目了然地看到。
数据获取
要展示高校的分布情况,就得先获取全国高校的位置数据。本文的数据来源于掌上高考网(https://www.gaokao.cn/school/search)。
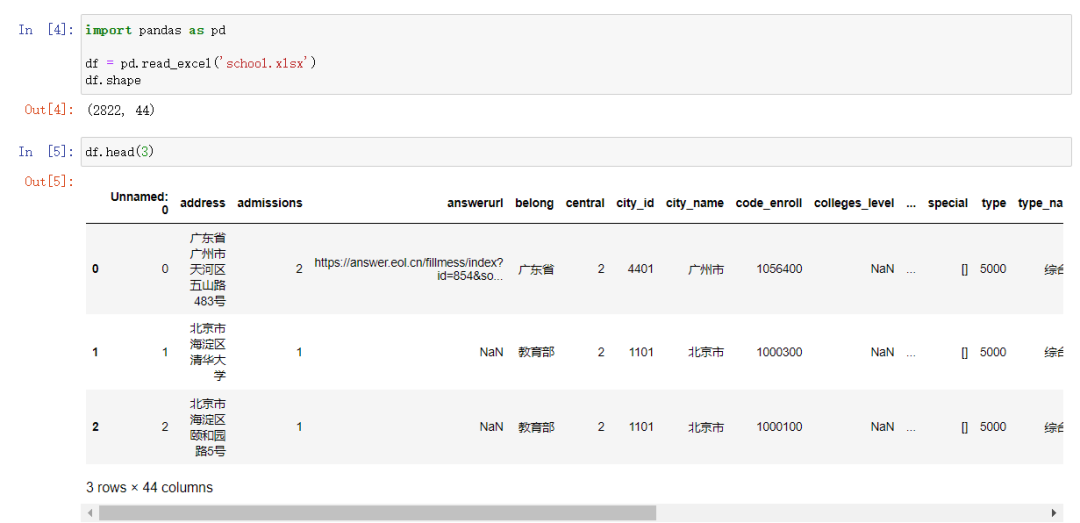
在2022年6月写本文时,共获取到了2822所高校的信息。检查了数据,除了极个别空值外,整份数据是非常完整的,不影响使用。数据一共有44个字段,本文只会用几个字段,可以不做处理,使用时按需获取即可。
数据获取方法介绍(基础爬虫知识):
1.注册登录掌上高考网。在<查学校>页面选择全部学校。
2.按F12键,点击到 Network > Fetch/XHR,然后点击几次<查学校>页面的<上一页>、<下一页>按钮,在XHR的页面会显示访问的API等信息。
3.将每次翻页时的API复制出来进行对比,发现翻页时变化的参数有两个:page和signsafe,page为当前访问的页数,signsafe是一个md5值,没法反解,但可以把前面几次的值保存下来,后面随机变化使用。有了这个信息,不断改变访问的页数和signsafe值,就可以获取到所有的学校数据。
Response中的numFound参数值是学校总数,除以每页显示的学校个数可以得到总页数,也可以直接点击页面的<尾页>查看总页数,这样就确定了访问的次数。
4.因为网站需要登录才能使用,所以还要获取访问时的Headers,如Request Method(此次用POST)、User-Agent等。
5.有了上面的信息,循环拼接出所有页面的url,用requests发送请求即可获取到所有高校的数据,然后用pandas将数据写到excel中。
温馨提示:获取数据时需遵守网站的相关声明,爬虫代码尽量设置一定的时间间隔,不要在访问高峰期运行爬虫代码。
补充说明:
人民网最新公布:全国的普通高校数是2759所,与本文从掌上高考网获取的2822所相差63所,主要是部分学校的分校统计方式不同造成的差异。本文所展示的是分布情况,这个差异的影响不大。

经纬度获取
掌上高考网是为高考填志愿服务的网站,虽然获取的数据有44个字段,但里面并没有学校的经纬度。为了更好地在地图上展示高校位置, 需要根据学校的地址获取对应的经纬度。
本文使用百度地图开放平台:
https://lbsyun.baidu.com/apiconsole/center#/home,可以用百度地图的开放接口获取地理位置的经纬度。
使用步骤为:
1.注册登录百度账号,这个账号可以是整个百度生态通用的账号(如网盘、文库等的账号是通用的)。
2.登录到百度地图开放平台,点击进入<控制台>,然后在<应用管理>中点击<我的应用>,再点击<创建应用>创建一个应用。应用名称自定义,其他信息按提示和要求填写完整,并进行实名认证,成为个人开发者。
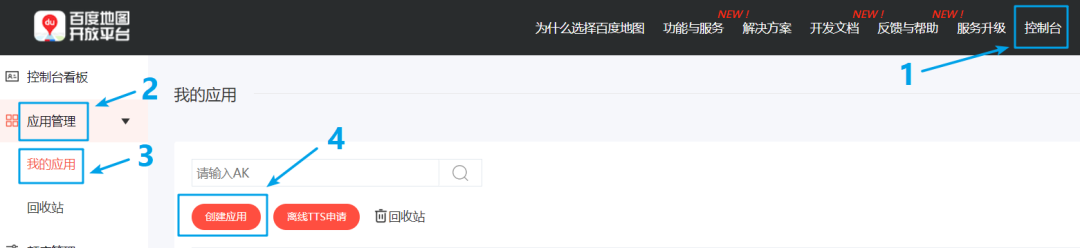
3.创建应用完成后,会获得一个应用的<访问应用(AK)>,用这个AK值可以调用百度的API,参考代码如下。
import requests
def baidu_api(addr):
url = "http://api.map.baidu.com/geocoding/v3/?"
params = {
"address": addr,
"output": "json",
"ak": "复制你创建的应用AK到此"
}
req = requests.get(url, params)
res = req.json()
if len(res["result"]) > 0:
loc = res["result"]["location"]
return loc
else:
print("获取{}经纬度失败".format(addr))
return {'lng': '', 'lat': ''}
4.成功调用百度地图API后,读取所有高校的位置,依次调用上面的函数,获取所有高校的经纬度,重新写入excel中。
import pandas as pd
import numpy as np
def get_lng_lat():
df = pd.read_excel('school.xlsx')
lng_lat = []
for row_index, row_data in df.iterrows():
addr = row_data['address']
if addr is np.nan:
addr = row_data['city_name'] + row_data['county_name']
# print(addr)
loc = baidu_api(addr.split(',')[0])
lng_lat.append(loc)
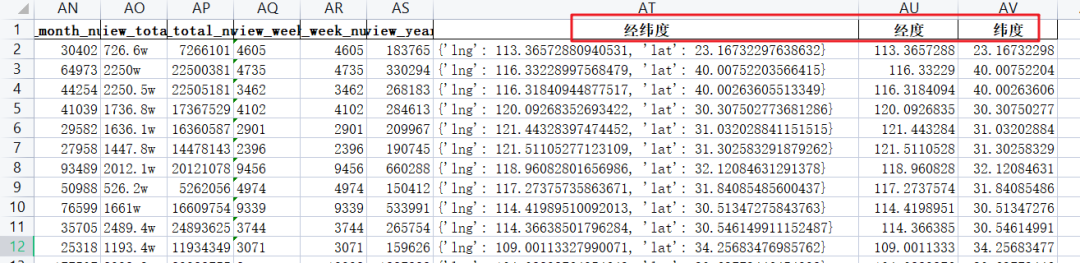
df['经纬度'] = lng_lat
df['经度'] = df['经纬度'].apply(lambda x: x['lng'])
df['纬度'] = df['经纬度'].apply(lambda x: x['lat'])
df.to_excel('school_lng_lat.xlsx')
最终数据结果如下图:
个人开发者使用百度地图开放平台时需注意,每天有额度限制,所以调试代码时先不要用所有数据,先用demo跑通,否则得等一天或购买额度。
高校位置展示
数据准备好了,接下来将他们展示到地图上。
本文使用百度开源的数据可视化工具Echarts,Echarts为Python语言提供了pyecharts库,使用很方便。
安装命令:
pip install pyecharts
1.标注高校的位置
from pyecharts.charts import Geo
from pyecharts import options as opts
from pyecharts.globals import GeoType
import pandas as pd
def multi_location_mark():
"""批量标注点"""
geo = Geo(init_opts=opts.InitOpts(bg_color='black', width='1600px', height='900px'))
df = pd.read_excel('school_lng_lat.xlsx')
for row_index, row_data in df.iterrows():
geo.add_coordinate(row_data['name'], row_data['经度'], row_data['纬度'])
data_pair = [(name, 2) for name in df['name']]
geo.add_schema(
maptype='china', is_roam=True, itemstyle_opts=opts.ItemStyleOpts(color='#323c48', border_color='#408080')
).add(
'', data_pair=data_pair, type_=GeoType.SCATTER, symbol='pin', symbol_size=16, color='#CC3300'
).set_series_opts(
label_opts=opts.LabelOpts(is_show=False)
).set_global_opts(
title_opts=opts.TitleOpts(title='全国高校位置标注图', pos_left='650', pos_top='20',
title_textstyle_opts=opts.TextStyleOpts(color='white', font_size=16))
).render('high_school_mark.html')
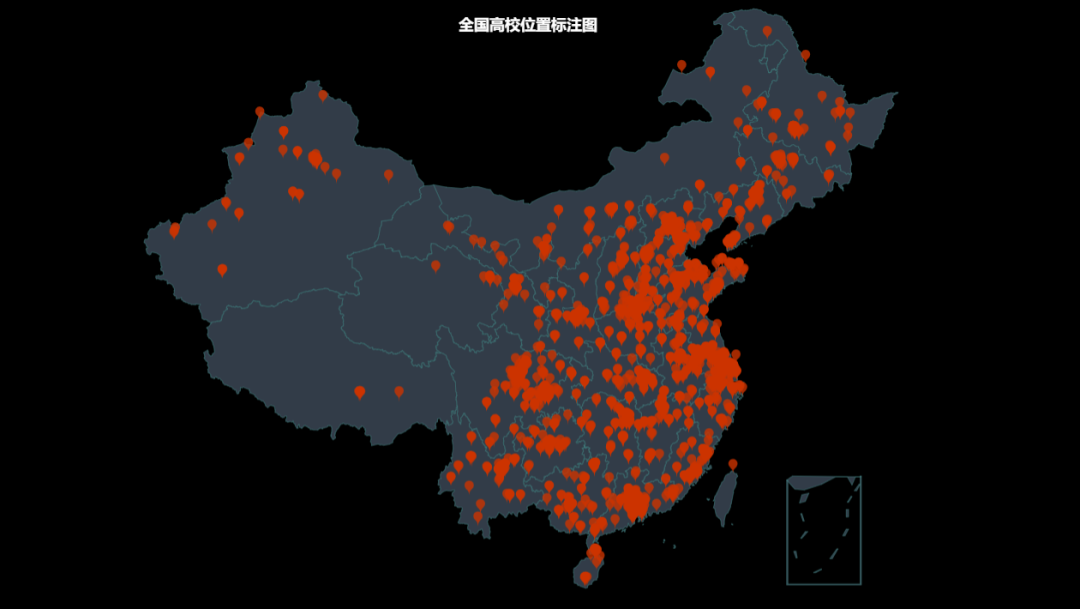
从标注结果来看,高校主要分布沿海、中部和东部,西部尤其是高海拔地区分布相对较少。
2.绘制高校分布热力图
from pyecharts.charts import Geo
from pyecharts import options as opts
from pyecharts.globals import ChartType
import pandas as pd
def draw_location_heatmap():
"""绘制热力图"""
geo = Geo(init_opts=opts.InitOpts(bg_color='black', width='1600px', height='900px'))
df = pd.read_excel('school_lng_lat.xlsx')
for row_index, row_data in df.iterrows():
geo.add_coordinate(row_data['name'], row_data['经度'], row_data['纬度'])
data_pair = [(name, 2) for name in df['name']]
geo.add_schema(
maptype='china', is_roam=True, itemstyle_opts=opts.ItemStyleOpts(color='#323c48', border_color='#408080')
).add(
'', data_pair=data_pair, type_=ChartType.HEATMAP
).set_series_opts(
label_opts=opts.LabelOpts(is_show=False)
).set_global_opts(
title_opts=opts.TitleOpts(title='全国高校分布热力图', pos_left='650', pos_top='20',
title_textstyle_opts=opts.TextStyleOpts(color='white', font_size=16)),
visualmap_opts=opts.VisualMapOpts()
).render('high_school_heatmap.html')
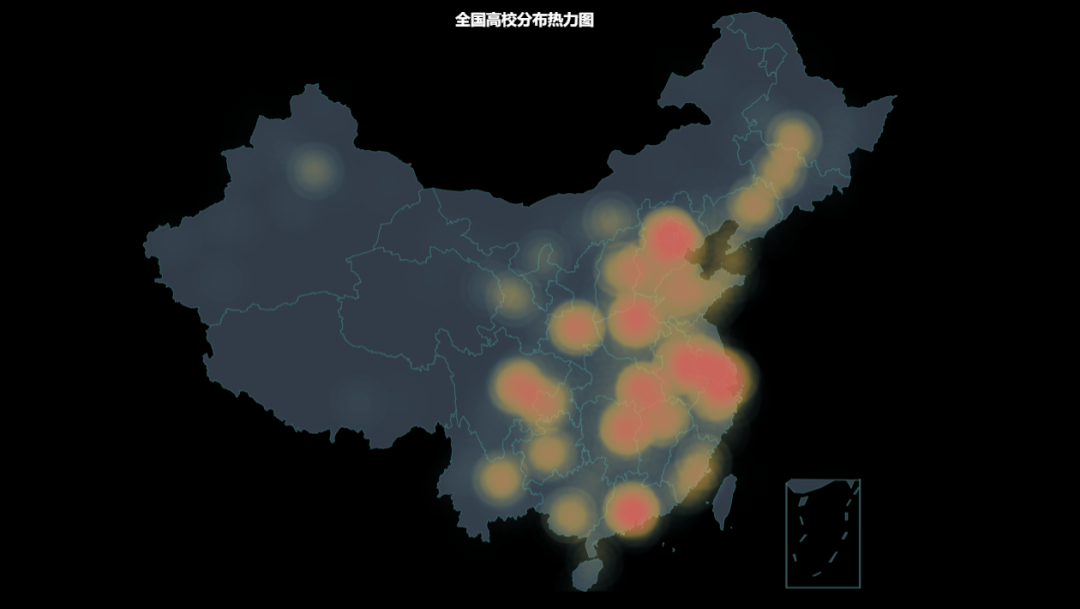
从热力图看,高校分布较集中的地方主要是沿海、北上广、长江黄河流域,西部较多的地方只有川渝。
3.绘制按省划分的分布密度图
from pyecharts.charts import Map
from pyecharts import options as opts
import pandas as pd
def draw_location_density_map():
"""绘制各省高校分布密度图"""
map = Map(init_opts=opts.InitOpts(bg_color='black', width='1200px', height='700px'))
df = pd.read_excel('school_lng_lat.xlsx')
s = df['province_name'].value_counts()
data_pair = [[province, int(s[province])] for province in s.index]
map.add(
'', data_pair=data_pair, maptype="china"
).set_global_opts(
title_opts=opts.TitleOpts(title='全国高校按省分布密度图', pos_left='500', pos_top='70',
title_textstyle_opts=opts.TextStyleOpts(color='white', font_size=16)),
visualmap_opts=opts.VisualMapOpts(max_=200, is_piecewise=True, pos_left='100', pos_bottom='100', textstyle_opts=opts.TextStyleOpts(color='white', font_size=16))
).render("high_school_density.html")
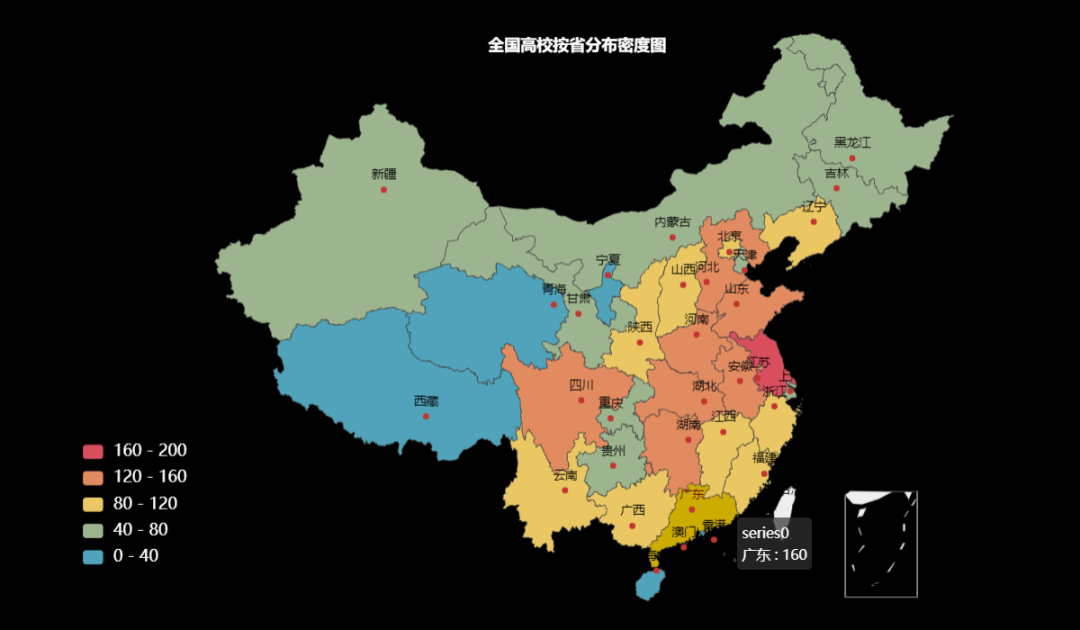
从省级分布密度图可以看出,高校数量多的省份集中在中部和东部,尤其是北京和上海附近的几个省。
4.211和985高校的分布情况
筛选出211和985的高校数据,再绘制一次。(代码不重复粘贴,只需要加一行筛选代码即可)
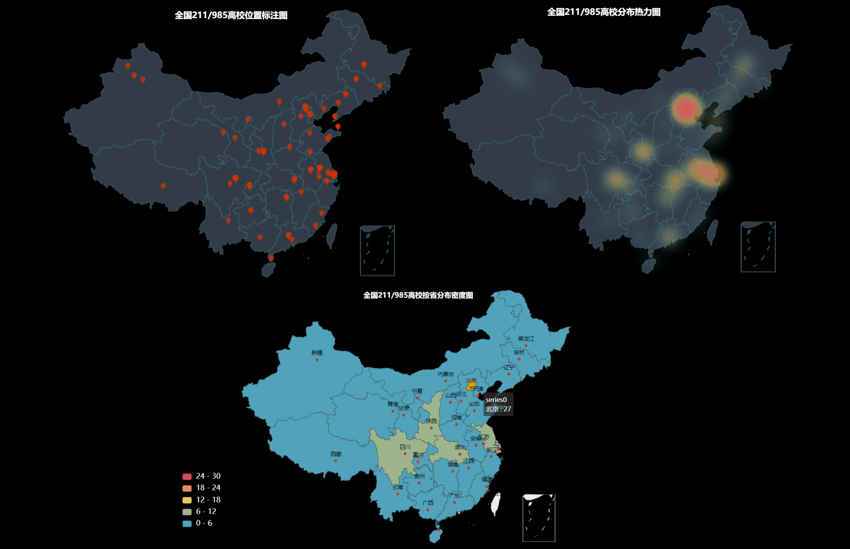
以上就是本文的全部内容,对以上内容有兴趣的话,大家可以多多尝试,也可以联系号主讨论。
参考文档:
1.掌上高考网:https://www.gaokao.cn/school/search
2.pyecharts中文文档:https://pyecharts.org/#/zh-cn/geography_charts
公众号后台回复:「高校数据」,即可获取本文完整数据。
推荐阅读
建议收藏!Python 读取千万级数据自动写入 MySQL 数据库
太酷了!手把手教你用 Python 绘制桑基图!| 用户行为路径分析
用 Python 批量提取 PDF 的图片,并存储到指定文件夹
杰哥私人微信,欢迎添加围观朋友圈。
