
SpringBoot集成ElasticSearch,实现模糊查询,批量CRUD,排序,分...
 程序员的成长之路互联网/程序员/技术/资料共享
关注
程序员的成长之路互联网/程序员/技术/资料共享
关注
阅读本文大概需要 5.5 分钟。
来自:https://blog.csdn.net/qq_52355487/article/details/123805713
# 导入elasticsearch依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
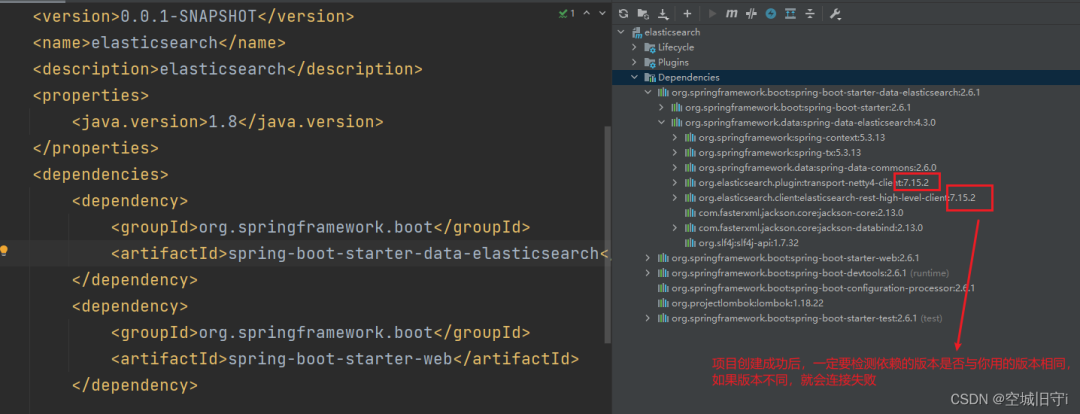
非常重要:检查依赖版本是否与你当前所用的版本是否一致,如果不一致,会连接失败!!!!!!!!
# 创建高级客户端
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig {
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("服务器IP", 9200, "http")));
return client;
}
}
# 基本用法
1.创建、判断存在、删除索引
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class ElasticsearchApplicationTests {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Test
void testCreateIndex() throws IOException {
//1.创建索引请求
CreateIndexRequest request = new CreateIndexRequest("ljx666");
//2.客户端执行请求IndicesClient,执行create方法创建索引,请求后获得响应
CreateIndexResponse response=
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(response);
}
@Test
void testExistIndex() throws IOException {
//1.查询索引请求
GetIndexRequest request=new GetIndexRequest("ljx666");
//2.执行exists方法判断是否存在
boolean exists=restHighLevelClient.indices().exists(request,RequestOptions.DEFAULT);
System.out.println(exists);
}
@Test
void testDeleteIndex() throws IOException {
//1.删除索引请求
DeleteIndexRequest request=new DeleteIndexRequest("ljx666");
//执行delete方法删除指定索引
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
}
2.对文档的CRUD
创建文档: 注意:如果添加时不指定文档ID,他就会随机生成一个ID,ID唯一。 创建文档时若该ID已存在,发送创建文档请求后会更新文档中的数据。
@Test
void testAddUser() throws IOException {
//1.创建对象
User user=new User("Go",21,new String[]{"内卷","吃饭"});
//2.创建请求
IndexRequest request=new IndexRequest("ljx666");
//3.设置规则 PUT /ljx666/_doc/1
//设置文档id=6,设置超时=1s等,不设置会使用默认的
//同时支持链式编程如 request.id("6").timeout("1s");
request.id("6");
request.timeout("1s");
//4.将数据放入请求,要将对象转化为json格式
//XContentType.JSON,告诉它传的数据是JSON类型
request.source(JSONValue.toJSONString(user), XContentType.JSON);
//5.客户端发送请求,获取响应结果
IndexResponse indexResponse=restHighLevelClient.index(request,RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
获取文档中的数据:
@Test
void testGetUser() throws IOException {
//1.创建请求,指定索引、文档id
GetRequest request=new GetRequest("ljx666","1");
GetResponse getResponse=restHighLevelClient.get(request,RequestOptions.DEFAULT);
System.out.println(getResponse);//获取响应结果
//getResponse.getSource() 返回的是Map集合
System.out.println(getResponse.getSourceAsString());//获取响应结果source中内容,转化为字符串
}
更新文档数据:
注意:需要将User对象中的属性全部指定值,不然会被设置为空,如User只设置了名称,那么只有名称会被修改成功,其他会被修改为null。
@Test
void testUpdateUser() throws IOException {
//1.创建请求,指定索引、文档id
UpdateRequest request=new UpdateRequest("ljx666","6");
User user =new User("GoGo",21,new String[]{"内卷","吃饭"});
//将创建的对象放入文档中
request.doc(JSONValue.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse=restHighLevelClient.update(request,RequestOptions.DEFAULT);
System.out.println(updateResponse.status());//更新成功返回OK
}
删除文档:
@Test
void testDeleteUser() throws IOException {
//创建删除请求,指定要删除的索引与文档ID
DeleteRequest request=new DeleteRequest("ljx666","6");
DeleteResponse updateResponse=restHighLevelClient.delete(request,RequestOptions.DEFAULT);
System.out.println(updateResponse.status());//删除成功返回OK,没有找到返回NOT_FOUND
}
3.批量CRUD数据
这里只列出了批量插入数据,其他与此类似。
注意:hasFailures()方法是返回是否失败,即它的值为false时说明上传成功。
@Test
void testBulkAddUser() throws IOException {
BulkRequest bulkRequest=new BulkRequest();
//设置超时
bulkRequest.timeout("10s");
ArrayList<User> list=new ArrayList<>();
list.add(new User("Java",25,new String[]{"内卷"}));
list.add(new User("Go",18,new String[]{"内卷"}));
list.add(new User("C",30,new String[]{"内卷"}));
list.add(new User("C++",26,new String[]{"内卷"}));
list.add(new User("Python",20,new String[]{"内卷"}));
int id=1;
//批量处理请求
for (User u :list){
//不设置id会生成随机id
bulkRequest.add(new IndexRequest("ljx666")
.id(""+(id++))
.source(JSONValue.toJSONString(u),XContentType.JSON));
}
BulkResponse bulkResponse=restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());//是否执行失败,false为执行成功
}
4.查询所有、模糊查询、分页查询、排序、高亮显示
@Test
void testSearch() throws IOException {
SearchRequest searchRequest=new SearchRequest("ljx666");//里面可以放多个索引
SearchSourceBuilder sourceBuilder=new SearchSourceBuilder();//构造搜索条件
//此处可以使用QueryBuilders工具类中的方法
//1.查询所有
sourceBuilder.query(QueryBuilders.matchAllQuery());
//2.查询name中含有Java的
sourceBuilder.query(QueryBuilders.multiMatchQuery("java","name"));
//3.分页查询
sourceBuilder.from(0).size(5);
//4.按照score正序排列
//sourceBuilder.sort(SortBuilders.scoreSort().order(SortOrder.ASC));
//5.按照id倒序排列(score会失效返回NaN)
//sourceBuilder.sort(SortBuilders.fieldSort("_id").order(SortOrder.DESC));
//6.给指定字段加上指定高亮样式
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field("name").preTags("<span style='color:red;'>").postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
searchRequest.source(sourceBuilder);
SearchResponse searchResponse=restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
//获取总条数
System.out.println(searchResponse.getHits().getTotalHits().value);
//输出结果数据(如果不设置返回条数,大于10条默认只返回10条)
SearchHit[] hits=searchResponse.getHits().getHits();
for(SearchHit hit :hits){
System.out.println("分数:"+hit.getScore());
Map<String,Object> source=hit.getSourceAsMap();
System.out.println("index->"+hit.getIndex());
System.out.println("id->"+hit.getId());
for(Map.Entry<String,Object> s:source.entrySet()){
System.out.println(s.getKey()+"--"+s.getValue());
}
}
}
# 总结
1.大致流程
创建对应的请求 --> 设置请求(添加规则,添加数据等) --> 执行对应的方法(传入请求,默认请求选项)–> 接收响应结果(执行方法返回值)–> 输出响应结果中需要的数据(source,status等)
2.注意事项
- 如果不指定id,会自动生成一个随机id
- 正常情况下,不应该这样使用new IndexRequest(“ljx777”),如果索引发生改变了,那么代码都需要修改,可以定义一个枚举类或者一个专门存放常量的类,将变量用final static等进行修饰,并指定索引值。其他地方引用该常量即可,需要修改也只需修改该类即可。
- elasticsearch相关的东西,版本都必须一致,不然会报错
- elasticsearch很消耗内存,建议在内存较大的服务器上运行elasticsearch,否则会因为内存不足导致elasticsearch自动killed
推荐阅读:
互联网初中高级大厂面试题(9个G)
内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper......等技术栈!
⬇戳阅读原文领取!
朕已阅
![]()
评论