
⾼维特征的哈希技巧总结
“ 本文首先介绍嵌入技术,引出Hash Trick;其次分析就Hash冲突给出理论和实验证明,给出一个减少冲突的方案;接着就具体的场景给出减少特征Hash冲突或者在有限的参数空间内尽可能地表示高维特征的技巧;最后给出简单结论。”
文章来源:https://zhuanlan.zhihu.com/p/161058660
嵌入与Hash Trick
在嵌入技术(Embedding)被广泛使用前,常用的特征编码方式有One-Hot Encoding和CountVectorizer:
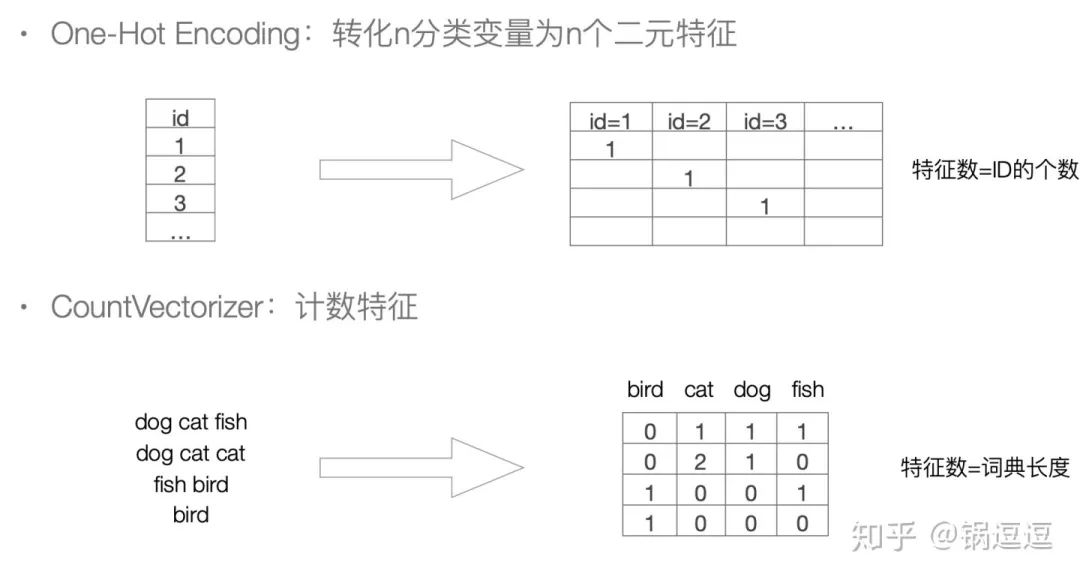
在高维特征情况下(如ID类特征、单词特征、数量可能高达千万级甚至上亿),上述编码方式在接入深度学习网络(如DNN)存下以下问题:
上述编码方式生成的Vector,其长度为总特征数,接入全连接层存在参数爆炸的问题。 通常一个样本对应的特征数量有限,远远小于总特征数。特征稀疏,每次更新只有极极极少数权重更新->网络收敛非常慢,有限样本情况下训练不充分。 上述编码方式,特征之间的关系始终保持独立,“非此即彼”,无法挖掘特征间的相似性。
嵌入技术是将一个数学结构经映射包含到另一个结构中。嵌入技术有以下几点好处:
高维结构,低维表示 蕴含信息丰富 存储较传统编码方式大大减少 可直接对接神经网络训练
特征嵌入技术是将特征用一个低维的向量来表示。对于给定一个特征ID,我们可以通过查表的方式获得这个特征的向量表达。由此构建了一个|V|*dim的Embedding Matrix,|V|表示总特征数,dim表示向量的维度。
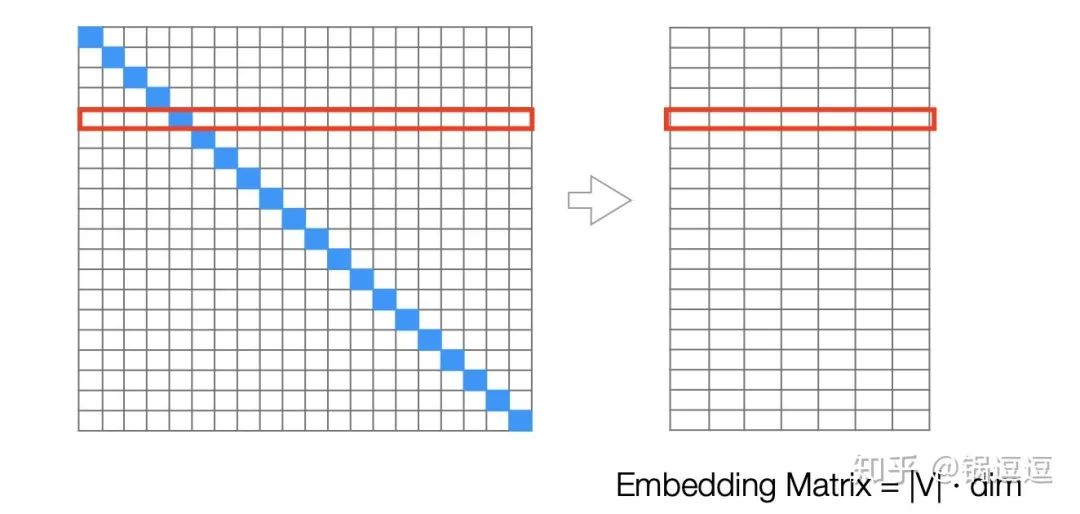
特征数量(词汇、ID)庞⼤导致模型需要训练的参数非常多,通常Embedding参数占据所有参数的90%以上。
为了较少参数量,可以有以下几种方案:
从减少特征维度来讲,通过人工剔除无用特征(如词汇中去除停用词、罕见词),或者根据entropy或topK去词/保留词。这种裁剪的方法效果因人而异,比较繁琐。 从压缩特征来讲,可以用Hash Trick。
Hash Trick是将原始的unique ID映射在一个[0,B]区间的一个数,⽽而B<<|V|从而达到降低计算参数和内存的目的。
对于任意⼀个特征,我们用Hash函数找到对应哈希表的位置,然后将该特征对应的值(为⽅便可以理解为word对应的词频)累加到该哈希表位置。
Hash冲突理论
有损压缩必存在特征冲突。所谓特征hash冲突,即两个不同的特征经映射后得相同的特征id,进而得到相同的嵌入向量。
接下来给出哈希冲突理论和实验以及对应结论。
Hash冲突理论
定义哈希函数
碰撞概率 表示一个待哈希对象经过哈希之后与其他对象发生碰撞的概率
对于大的压缩值B,我们可以做以下的近似
则发生碰撞的个数理论值为
当使用 个不同的哈希函数,则多哈希映射会扩大
,则碰撞概率变为Hash冲突简单实验
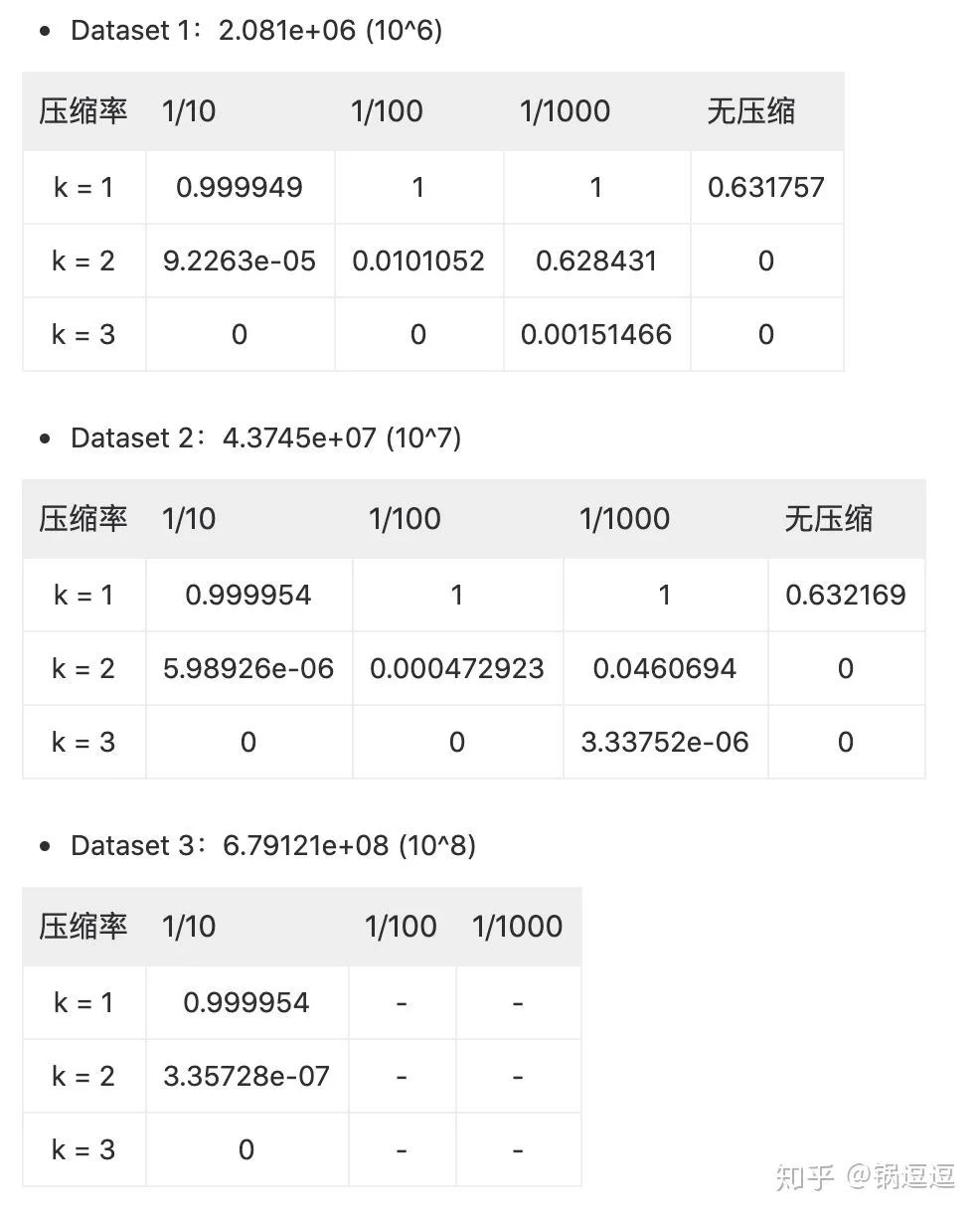
数据集是利用Xorshift伪随机算法生成reps个uint64位随机数,再通过比特位翻转构造随机数据,构造三个不同量级的数据集,简单实验后结果如下:
Hash冲突结论
无压缩情况下,碰撞概率值均在0.63左右,这与理论值相当。
为了降低碰撞冲突,有两种解决方法,一种是增大B,还有一种是增大k。
但因内存受限,不能一味增加B,且后续embedding matrix 的大小 为 ,即网络需要训练 个参数;
增加k会大幅度减小碰撞概率,可以看到当k=3时压缩10倍、压缩100倍在10^6 以上量级中实验不存在碰撞情况(理论值也巨小)。但是k的增加使得网络参数计算速度变慢。
结论1:采用2个哈希函数就可以大幅度地减小碰撞;
结论2:特征空间的大小在一定程度上可以指导B的选取,(如百万量级特征中,100倍压缩的碰撞率在1%左右,而千万量级中,100倍压缩碰撞率为0.04%)。
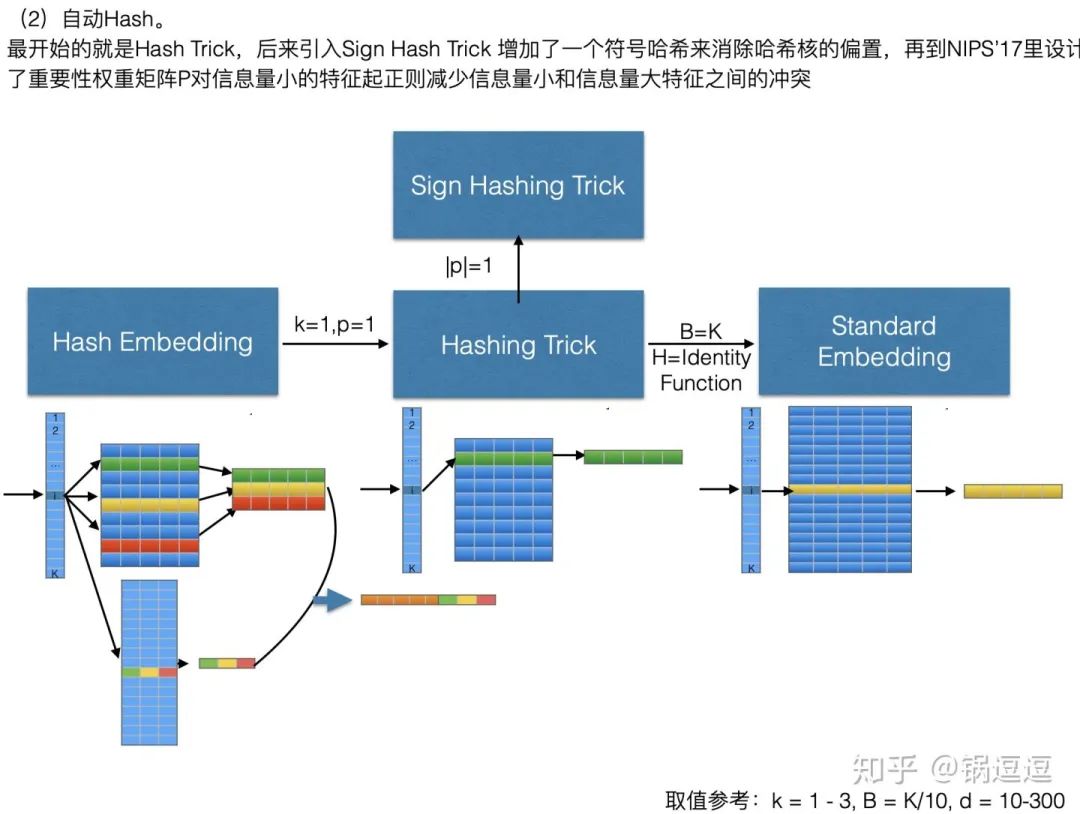
Sign Hash
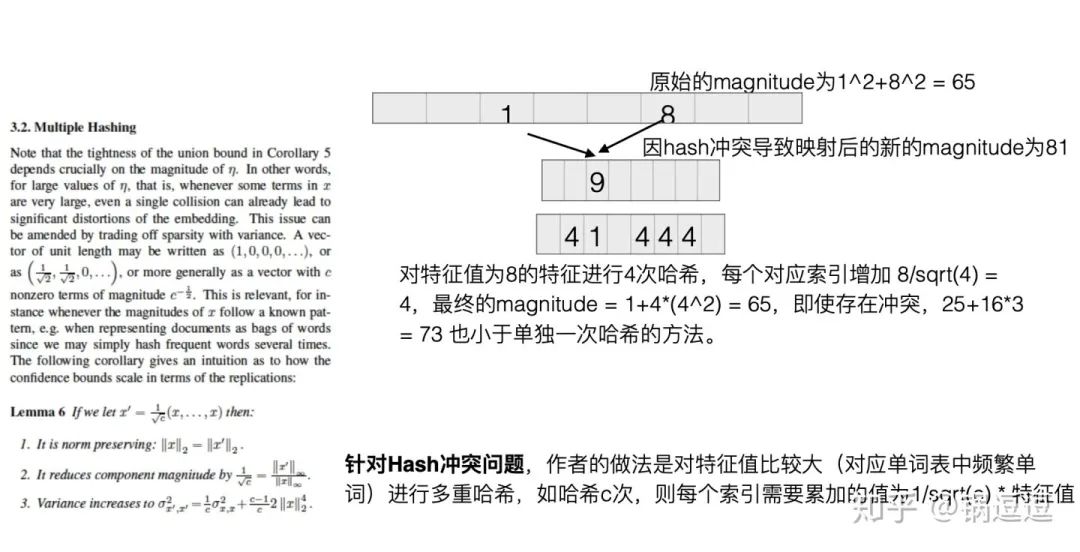
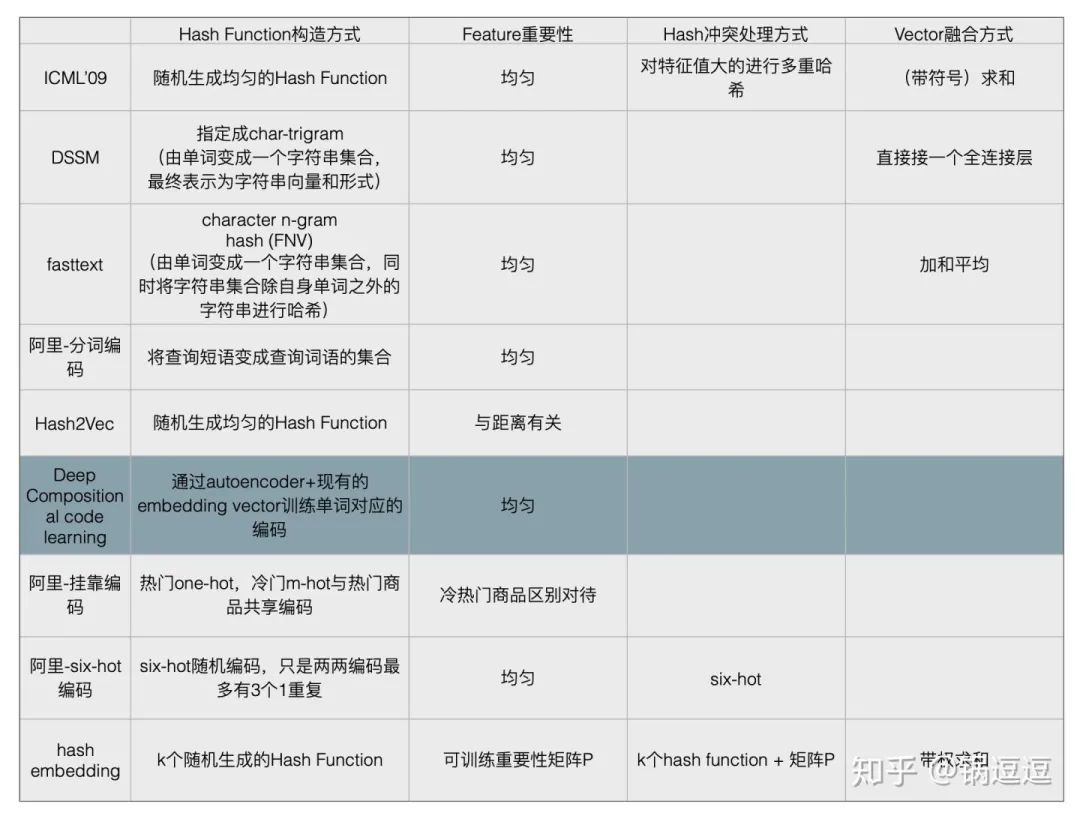
使用原始的Hash Trick存在⼀个问题,有可能两个原始特征的哈希后位置在一起导致词频累加特征值突然变⼤,为解决这个问题,ICML’09 提出hash Trick的变种signed hash trick,即除了原始的均匀哈希函数外,再增加了一个Binary Hash Function,来消除原始hash kernel的偏估计。
https://arxiv.org/pdf/0902.2206.pdf
Word Hash
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf
Char-ngrams + hash
https://arxiv.org/abs/1607.04606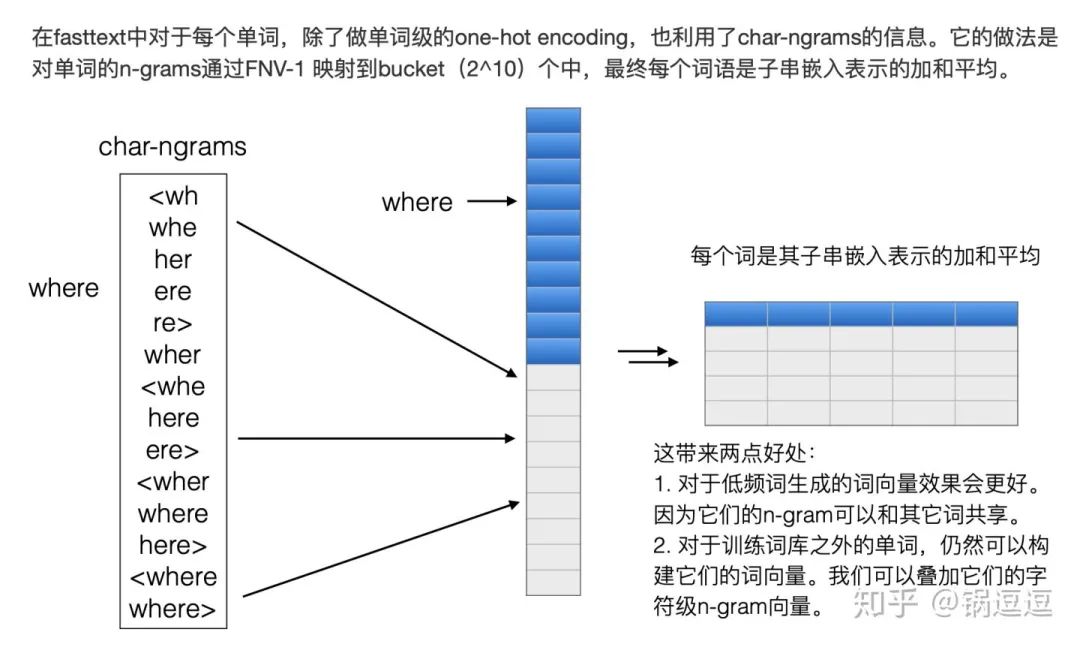
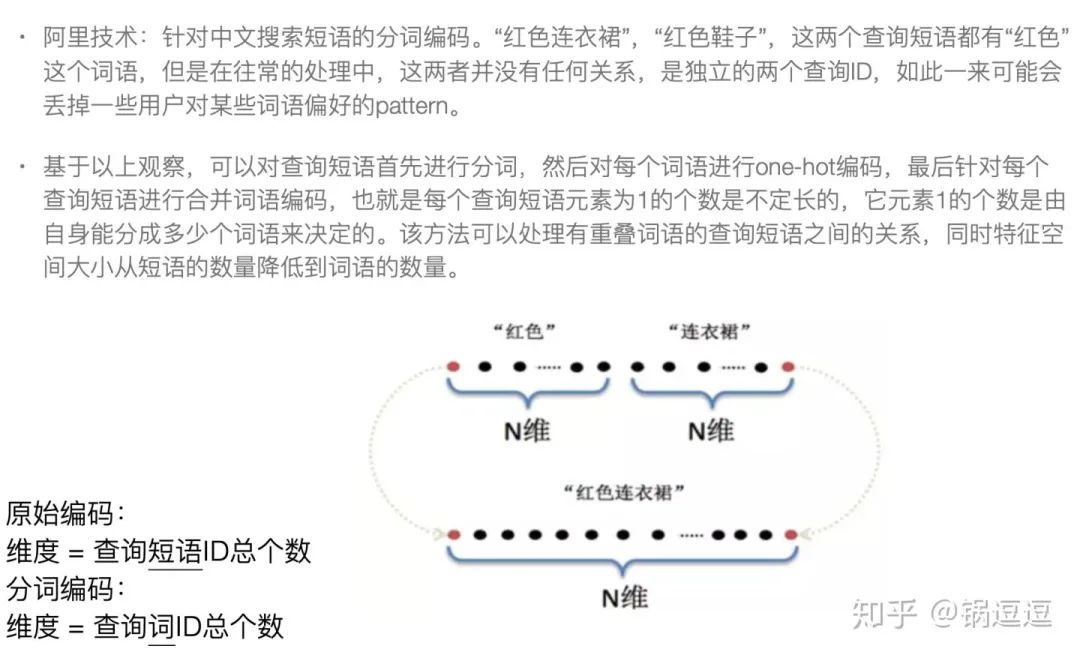
针对中文搜索短语的分词编码
Hash2Vec
https://arxiv.org/abs/1608.08940
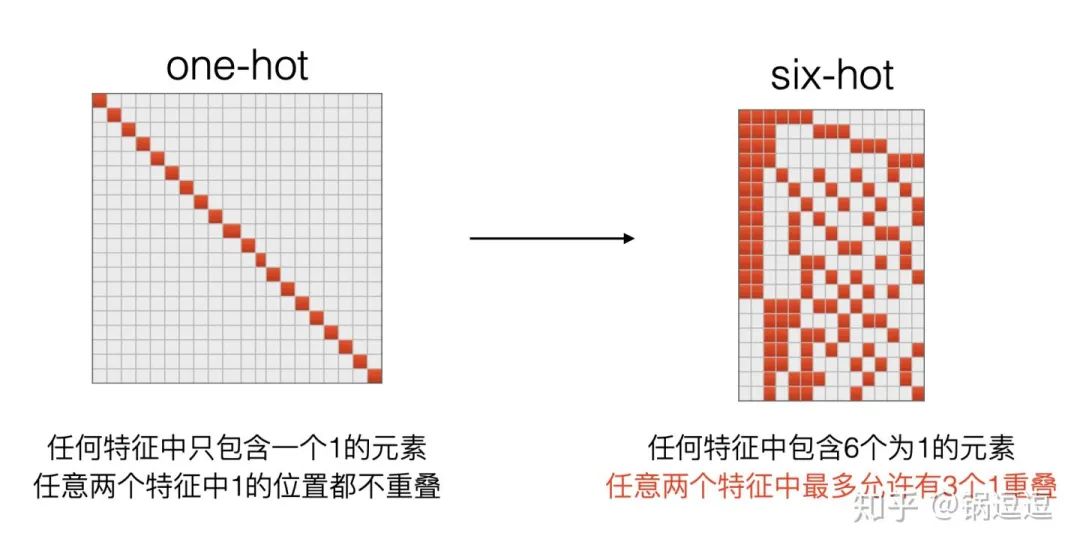
随机编码
原先一个特征只有一个特征id,现在一个特征对应6个特征id,任意两个特征中最多允许有3个1重叠。
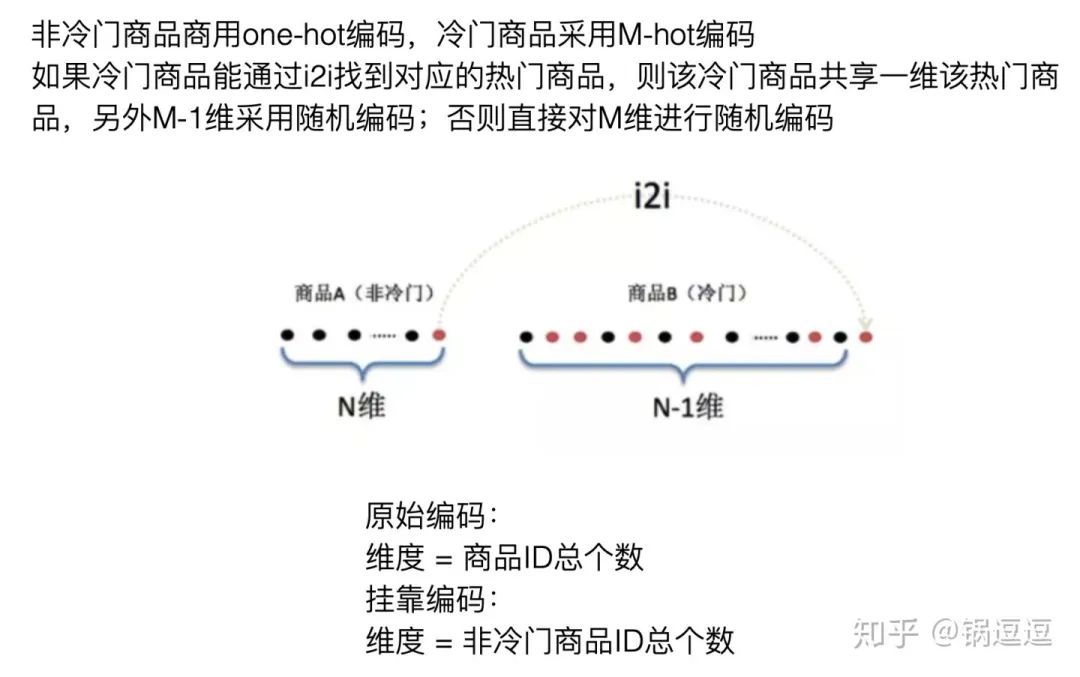
挂靠编码
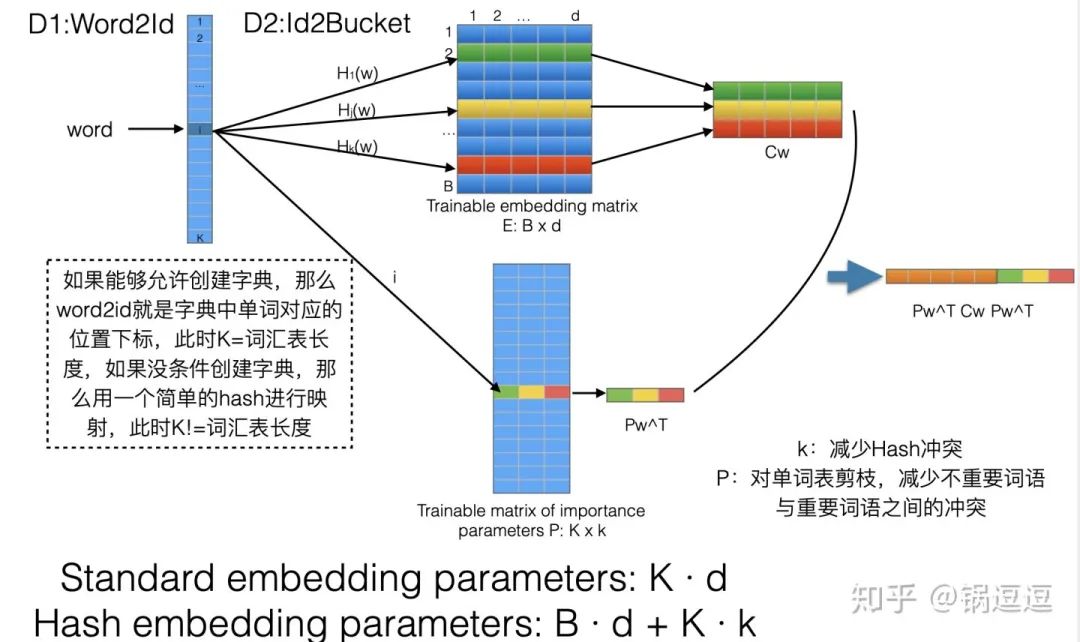
Hash Embedding
一个特征由K个id对应的embedding加权求和表示,具体权重参数是通过神经网络训练得到。
https://github.com/YannDubs/Hash-Embeddingshttps://github.com/dsv77/hashembeddinghttps://papers.nips.cc/paper/7078-hash-embeddings-for-efficient-word-representations.pdf
小结


往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):