
PAN++:精确高效的任意形状文本端到端检测与识别(附源码)|[TPAMI 2021]
共 3820字,需浏览 8分钟
·
2021-05-30 04:51

本文简要介绍了TPAMI2021录用论文“PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text”。该论文展示了一种基于文本内核(即中心区域)的任意形状文本的表示方法,可以较好地区分相邻文本,且对实时的应用场景非常友好。在此基础上,作者建立了一个高效的端到端框架PAN++,可以有效地检测和识别自然场景中任意形状的文本,并且同时做到了高推理速度和高精度。论文代码地址:https://github.com/whai362/pan_pp.pytorch。

一、研究背景
二、原理简述
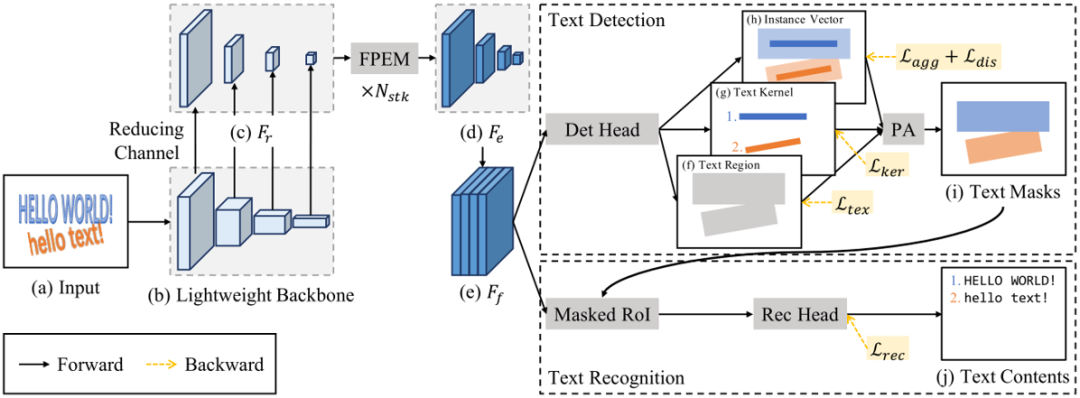
图2 PAN++总体架构
PAN++的整体架构如图2所示。为了提高推理速度,作者主要采用了轻量级的ResNet18[3]作为骨干网络。但是,轻量级网络具有感受野小和表征能力弱的缺点,针对这一问题,本文提出使用堆叠的特征金字塔增强模块(FPEM)来增强提取到的特征。

图3 特征金字塔增强模块(FPEM)实现细节
如图3所示,FPEM是基于可分离卷积构建的U形模块,可以以较小的计算开销增强骨干网络提取的多尺度特征。另外,FPEM是可堆叠的,随着堆叠层数的增加,网络的感受野也将增大。
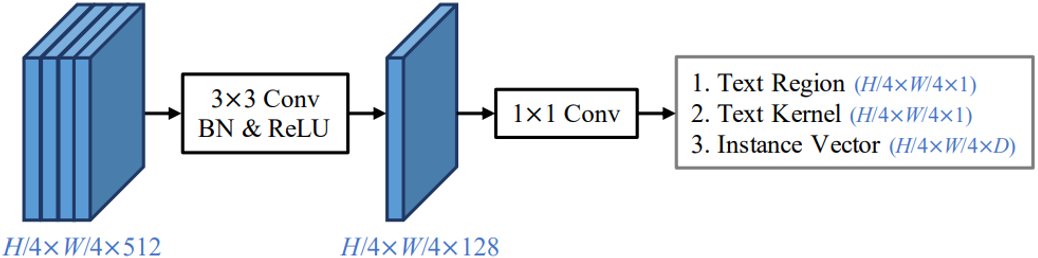
图4 检测头实现细节
对于文本检测任务,本文提出了一个仅包含两层卷积的轻量级检测头,如图4所示。该检测头同时预测生成文本区域、文本内核以及实例向量,再通过PA算法融合得到最终的检测结果。
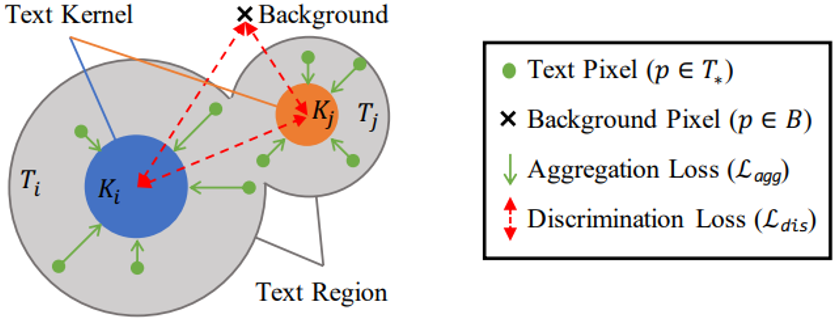
图5 PA算法说明
PA的设计借用了聚类的思想,如图5所示。如果把不同的文本看作不同的簇,则文本内核就是簇的中心,文本区域内的像素就是待聚类的样本。
对于文本识别任务,作者提出了一个不规则文字特征提取器Masked RoI和一个基于注意力机制的轻量级识别头。Masked RoI是一个用于为任意形状的文本提取固定大小的特征块的RoI提取器,而轻量级识别头仅包含两层LSTM和两层多头注意力,如图6所示。

图6 识别头实现细节
对于检测部分,本文使用的损失函数为:

对于识别部分,本文使用的损失函数为:

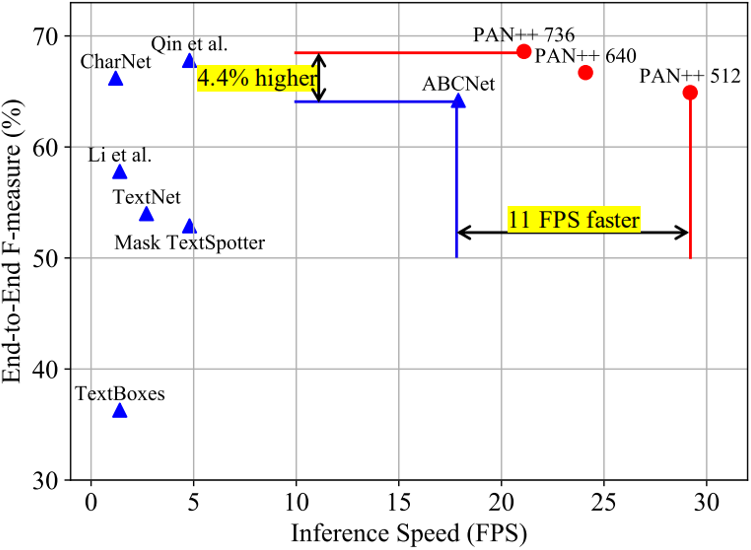
得益于上述设计,PAN++在保持精度具有竞争力的同时,实现了较高的推理速度。PAN++与其它方法的性能对比如图7所示。
三、实验结果与分析
表1 在Total-Text和CTW1500数据集上的文本检测结果
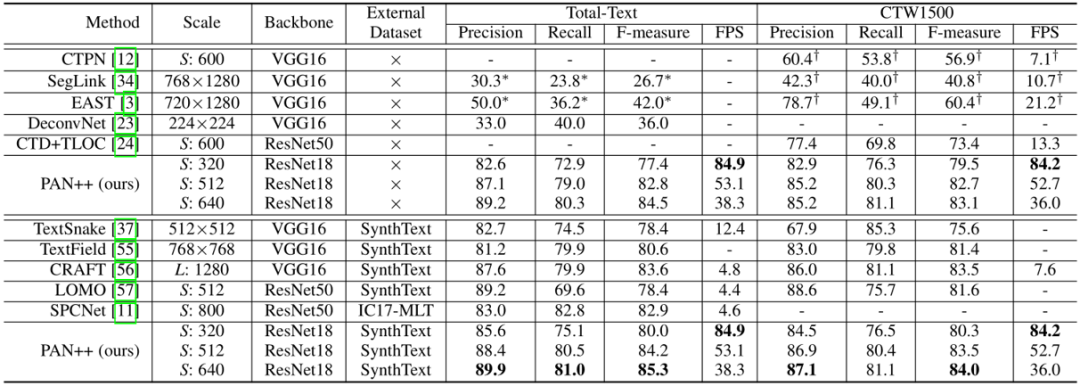
表2 在Total-Text数据集上的端到端文本识别结果

如表1和表2所示,在没有使用额外数据集预训练的情况下,PAN ++在Total-Text[4]和CTW1500[5]上取得了具有竞争力的结果。在使用SynthText[6]数据集预训练后,PAN++的精度进一步提高并取得了SOTA的效果。在短边为320像素的输入下,PAN++实现了超过84FPS的推理速度,超过了其它具有相似精度的方法。
四、总结
五、相关资源
PAN++论文地址:https://arxiv.org/abs/2105.00405
PAN++开源代码:https://github.com/whai362/pan_pp.pytorch
参考文献
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看