
顶刊TPAMI 2021!PAN++:精确高效的任意形状文本检测与识别
共 3903字,需浏览 8分钟
·
2022-02-09 17:36
作者建立了一个高效的端到端框架PAN++,可以有效地检测和识别自然场景中任意形状的文本,并且同时做到了高推理速度和高精度,代码现已开源!
来源:CSIG文档图像分析与识别专委会
原文链接:PAN++:精确高效的任意形状文本端到端检测与识别(有源码)


本文简要介绍了TPAMI2021录用论文“PAN++: Towards Efficient and Accurate End-to-End Spotting of Arbitrarily-Shaped Text”。该论文展示了一种基于文本内核(即中心区域)的任意形状文本的表示方法,可以较好地区分相邻文本,且对实时的应用场景非常友好。在此基础上,作者建立了一个高效的端到端框架PAN++,可以有效地检测和识别自然场景中任意形状的文本,并且同时做到了高推理速度和高精度。
原文作者:Wenhai Wang, Enze Xie, Xiang Li, Xuebo Liu, Ding Liang, Zhibo Yang, Tong Lu*, Chunhua Shen
论文:https://arxiv.org/abs/2105.00405
代码:https://github.com/whai362/pan_pp.pytorch
撰稿:陈喆、王文海 编排:高 学 审校:连宙辉 发布:金连文


一、研究背景
自然场景文本检测与识别是文本检索、自动化办公、可视化问答等众多应用的一项基本任务。近些年,场景文本检测与识别取得了瞩目的进展,但这些方法仍存在三个主要局限性,限制了其在实际应用中的部署。首先,大多数现有的工作将文本检测和识别作为独立的任务进行处理,很少有方法探讨这两项任务之间的互补性。第二,大多数现有的端到端文本检测与识别方法通常针对水平或定向文本设计,然而除了直线型文本外,不规则形状的文本在自然场景也极为常见。最后,现有方法的效率仍不能满足实际应用需求。最近的一些方法[1-2]致力于提高端到端任意形状文本检测与识别的精度,但是由于模型参数过多或算法流程复杂,导致其推理速度较低。因此,如何为任意形状的文本设计一个高效且精确的端到端检测与识别框架仍然是一个亟待解决的问题。
二、原理简述

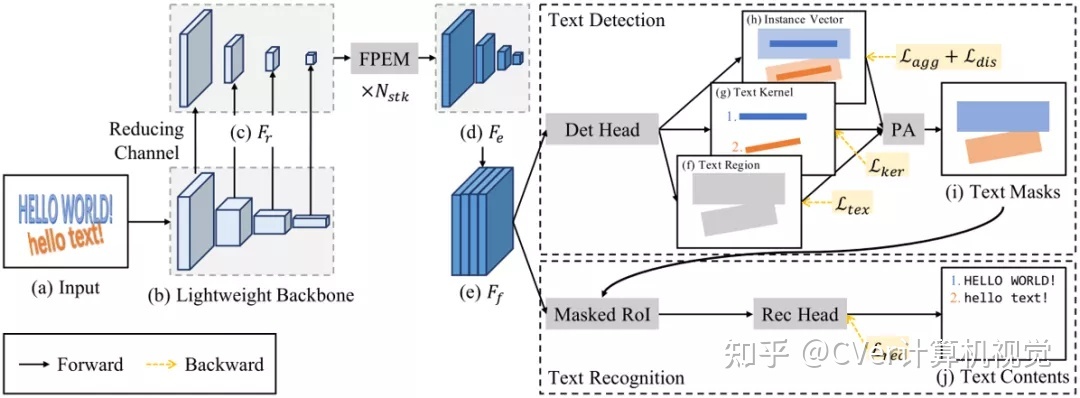
PAN++的整体架构如图2所示。为了提高推理速度,作者主要采用了轻量级的ResNet18[3]作为骨干网络。但是,轻量级网络具有感受野小和表征能力弱的缺点,针对这一问题,本文提出使用堆叠的特征金字塔增强模块(FPEM)来增强提取到的特征。

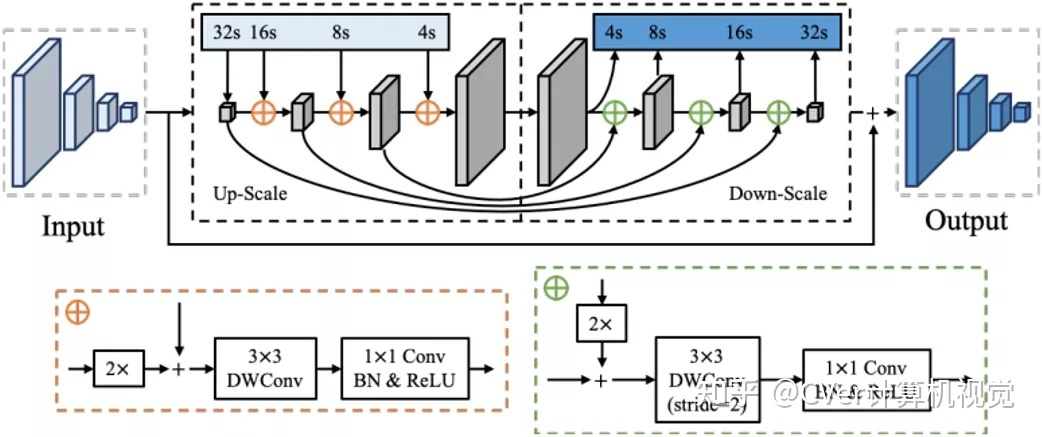
如图3所示,FPEM是基于可分离卷积构建的U形模块,可以以较小的计算开销增强骨干网络提取的多尺度特征。另外,FPEM是可堆叠的,随着堆叠层数的增加,网络的感受野也将增大。

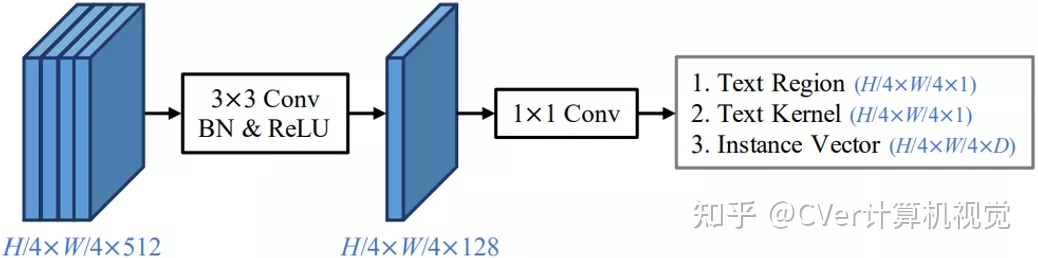
对于文本检测任务,本文提出了一个仅包含两层卷积的轻量级检测头,如图4所示。该检测头同时预测生成文本区域、文本内核以及实例向量,再通过PA算法融合得到最终的检测结果。

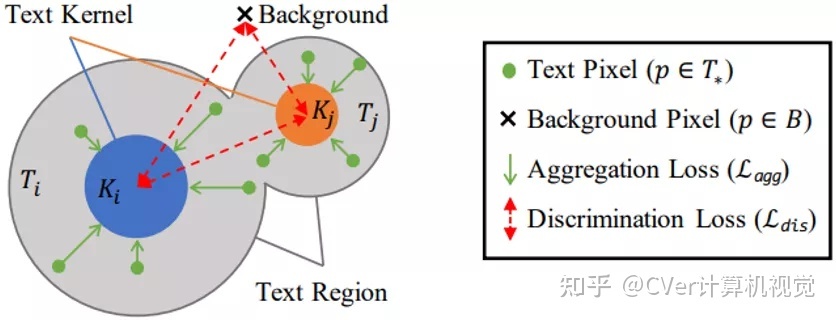
PA的设计借用了聚类的思想,如图5所示。如果把不同的文本看作不同的簇,则文本内核就是簇的中心,文本区域内的像素就是待聚类的样本。
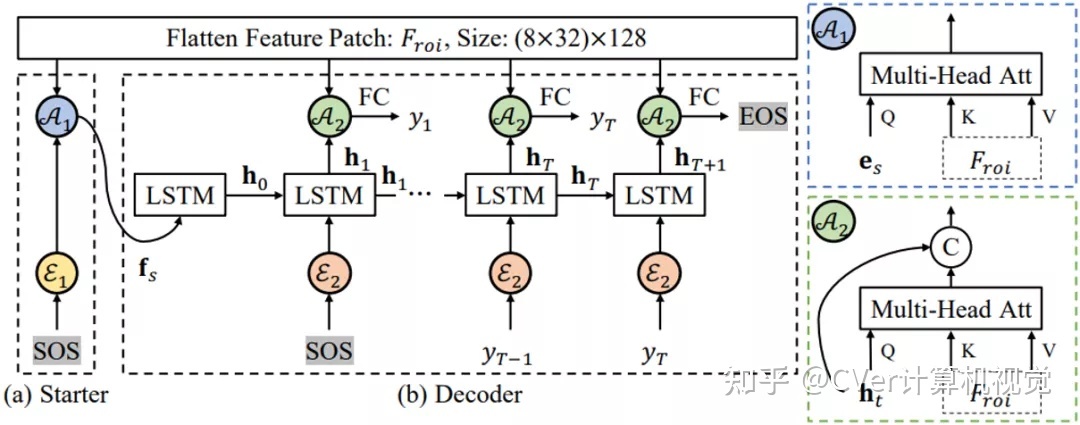
对于文本识别任务,作者提出了一个不规则文字特征提取器Masked RoI和一个基于注意力机制的轻量级识别头。Masked RoI是一个用于为任意形状的文本提取固定大小的特征块的RoI提取器,而轻量级识别头仅包含两层LSTM和两层多头注意力,如图6所示。

对于检测部分,本文使用的损失函数为:

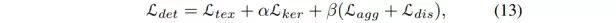
对于识别部分,本文使用的损失函数为:


得益于上述设计,PAN++在保持精度具有竞争力的同时,实现了较高的推理速度。PAN++与其它方法的性能对比如图7所示。

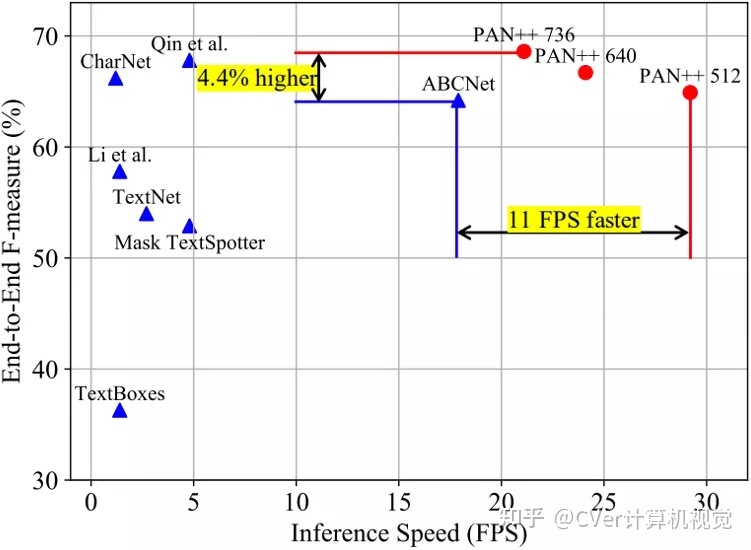
图7 PAN++与其它方法在Total-Text数据集上的性能对比
三、实验结果与分析
表1 在Total-Text和CTW1500数据集上的文本检测结果

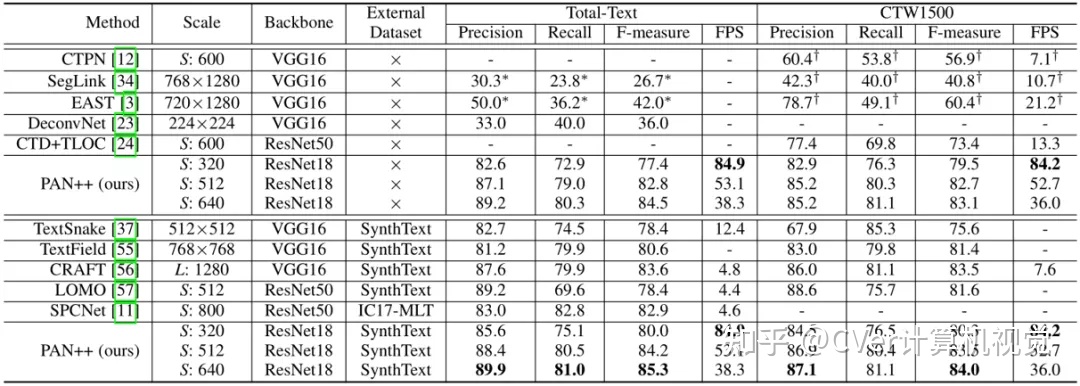
表2 在Total-Text数据集上的端到端文本识别结果

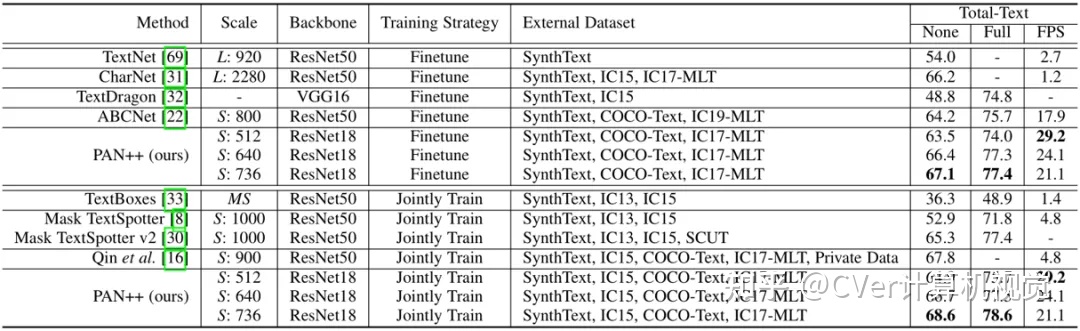
如表1和表2所示,在没有使用额外数据集预训练的情况下,PAN ++在Total-Text[4]和CTW1500[5]上取得了具有竞争力的结果。在使用SynthText[6]数据集预训练后,PAN++的精度进一步提高并取得了SOTA的效果。在短边为320像素的输入下,PAN++实现了超过84FPS的推理速度,超过了其它具有相似精度的方法。
表2展示了PAN++在Total-Text数据集上的端到端文本识别结果。这些结果表明,PAN++在文本识别任务中取得了SOTA的性能,并且在推理速度上显著优于现有方法。
四、总结
在本文中,作者提出了对任意形状文本友好的内核表示,并在此基础上开发了一个端到端的文本检测与识别框架PAN++,通过设计一系列轻量级模块,实现了高效且精确的任意形状文本检测与识别。与其它现有方法相比,PAN++在精度和推理速度上都具有显著优势。
参考文献
[1]Lyu, P., Liao, M., Yao, C., Wu, W., & Bai, X. (2018). Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 67-83).
[2]Qin, S., Bissacco, A., Raptis, M., Fujii, Y., & Xiao, Y. (2019). Towards unconstrained end-to-end text spotting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4704-4714).
[3]He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
[4]Ch'ng, C. K., & Chan, C. S. (2017, November). Total-text: A comprehensive dataset for scene text detection and recognition. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) (Vol. 1, pp. 935-942). IEEE.
[5]Yuliang, L., Lianwen, J., Shuaitao, Z., & Sheng, Z. (2017). Detecting curve text in the wild: New dataset and new solution. arXiv preprint arXiv:1712.02170.
[6]Gupta, A., Vedaldi, A., & Zisserman, A. (2016). Synthetic data for text localisation in natural images. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2315-2324).
CVer-视觉Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号:CVer9999。加的时候备注一下:Transformer+学校+昵称,即可。然后就可以拉你进群了。
CVer-目标检测交流群
建了CVer-目标检测交流群!想要进目标检测学习交流群的同学,可以直接加微信号:CVer9999。加的时候备注一下:目标检测+学校+昵称,即可。然后就可以拉你进群了。
强烈推荐大家关注CVer知乎账号和CVer微信公众号,可以快速了解到最新优质的CV论文。
推荐阅读
Transformer再下一城!TransVOD:基于时空Transformer的端到端视频目标检测
Swin-Unet:Unet形状的纯Transformer的医学图像分割
AI圈真魔幻!谷歌最新研究表明卷积在NLP预训练上竟优于Transformer?LeCun暧昧表态
CV圈杀疯了!继谷歌之后,清华、牛津等学者又发表三篇MLP相关论文,LeCun也在发声!