
对稀有飞机数据集进行多属性物体检测:使用YOLOv5的实验过程
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

如何使用物体的多个特征来提升物体检测的能力,使用YOLOv5进行多属性物体检测的实验。

我们发布了RarePlanes数据集和基线实验的结果。今天,我们试图进一步展示数据集的多特征以及它独特的用途。我们训练了一个目标检测模型,不仅可以识别飞机,还可以识别它们的特征,如引擎的数量、机翼形状等,并且建立了一个教程,所以你可以自己做这个实验。
在本系列教程中,我们将从头到尾介绍在RarePlanes数据集上训练YOLOv5模型的整个机器学习流程。
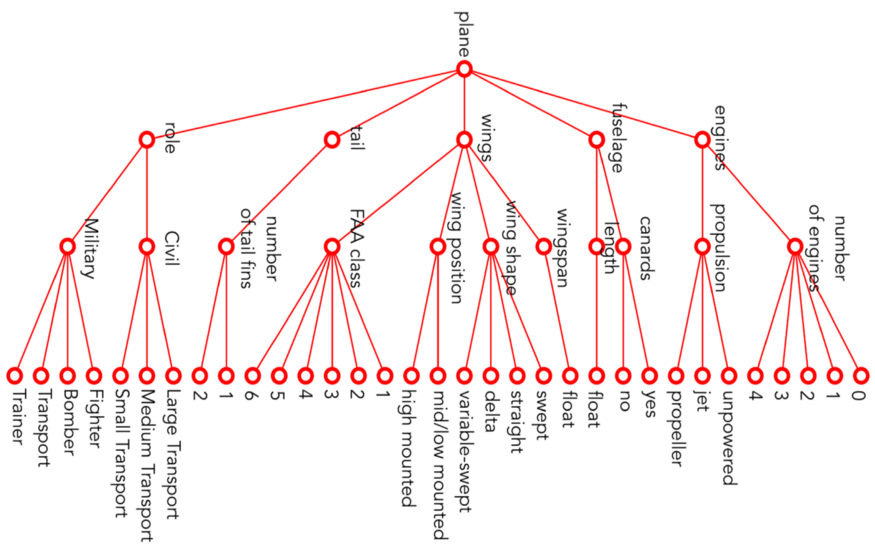
快速回顾:RarePlanes数据集是由CosmiQ Works和AI.Reverie通过将主要是机场的遥感数据与综合生成的数据相结合创建的。然后将这些图像按照5个特征、10个属性和33个子属性进行分类。每架飞机都通过从机头到翼尖再到尾部的菱形来标注,以保持宽度和长度的比例,然后,不同的飞机特征被标注在每个标注上。
下面是数据集中使用的飞机分类树。
在我们开始之前,先介绍一下背景。我们尝试了语义分割方法和物体检测方法。最终,我们决定使用YOLOv5进行物体检测,事后看来,这是对的,分割方法很难分离靠的很近的相似物体。
YOLO网络在各种任务上都显示了优良的性能。
You Only Look Once version 5 (YOLOv5),就像它的前身一样,它是一个物体检测网络。它将输入图像分割成一个个网格,然后输出每个网格框的包围框置信度和类概率矩阵。然后对这些输出进行过滤,从最终的预测中去除重叠和低置信的检测。这些包围框然后被输送到一个神经网络中进行检测。使用YOLO的网格建议方法(而不是R-CNN风格的网络中使用的更大的区域建议网络),预测的速度要快得多,允许YOLOv5实时工作。我们选择使用Ultralytics的YOLOv5实现,因为它非常简单,使用该模型创建管道比使用类似方法要简单得多。
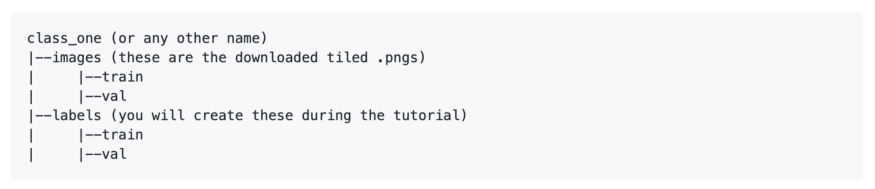
RarePlanes数据集包含了tiled图像,这些tiled图像是在PS-RGB_tiled目录下找到的实例周围进行局部选取的。我们建议首先对这些图像进行训练,因为它们可以提高训练速度。下载好了图片,必须按照下面的结构进行组织:
使用RarePlanes数据集,你可以为你想要检测的特性提供许多选项。例如,你可以检测飞机的位置、飞机的单个属性或属性的唯一组合。如果我们想检测属性的唯一组合,预处理中的第一步是创建自定义类。“role”,“num_engines”,“propulsion”,“canards”,“num_tail_fins”,“wing_position”,“wing_type”,“faa_wingspan_class”的任何组合都可以用来创建一个自定义类。在本教程中,我们选择在自定义类中组合“num_engines”和“propulsion”,因为我们希望通过强制模型尝试识别这两个相关属性来促进对这两个类的模型推断。
然后必须将这些自定义类的列表添加到YOLO特定的data .yaml文件中,该文件包括到训练和测试映像的文件路径、类的数量和类列表。
最后一步是从平片图像中创建YOLO标签,这些图像是由空格分隔的文本文件,包含每个框的类类型、位置和大小。为每个图像创建这些标签,在每个目标周围创建边框,用于训练和模型评估。
在这里有用于训练和运行推理的pipeline的基础实现。它告诉脚本在哪里找到我们上面创建的图像和训练标签。
训练
使用下面的命令,使用2个NVIDIA Titan XP GPUs训练大约需要4-5个小时。

推理和评分脚本也预先构建在这个YOLOv5实现中,可以用作性能的初始衡量标准。只需将函数指向训练过的权重,我们就可以在不到两分钟的时间内对所有2700多张图像运行推断。
初步推断:


初步评分:

使用简单的单行bash命令运行这些脚本。然而,这些结果并不是最准确的,因为它们包括重复的预测和部分预测。再运行一轮非极大抑制,去掉重复数据,拼接预测并在tiled的图像上给它们评分。现在,让我们看看我们做得如何。




使用F1度量,IoU为0.5,结果在90年代的飞机数据集上的F1得分非常稳定。值得注意的是,该模型能够识别引擎的位置和数量,而不需要训练数据集为引擎提供特定的标注。引擎的数量与每个飞机实例相关联,而不是引擎本身。
此外,对于不太常见的飞机,结果明显不那么好,这可能是由于缺少模型合适的样本。之前,我们讨论了如何使用合成数据来增强这些稀有类(或稀有飞机),以提高特定类的性能。
鲁棒的机器学习严重依赖于高质量的数据集。虽然随着AlexNet和卷积神经网络的发明,性能得到了显著改善,但预测机制缺乏真正的证明。最终,该模型依赖于“看到”足够多的与测试场景相似的场景,从而做出准确的预测(可以是数百或数千个场景)。有了这些,多样化的、有条理的、标记良好的数据集可以创建有效的模型,但需要注意的是,你不一定需要大量的数据。多样化、高质量的数据通常可以用更少的数据创建类似的性能模型,甚至仅用3%的数据得到2/3的性能模型。
然而,作为一个数据科学家,他的角色不是向模型提供尽可能多的数据,而是生成最准确的预测以解决某些问题。在这种情况下,我们通过创建有意义的自定义类来实现这一点,但在其他情况下,这可能意味着排除不太相关的特征,等等。创建自定义类可以提高性能,因为它迫使模型考虑飞机的特定属性。例如,使用动力类型和引擎数量的组合,我们看到两个属性的分类得到了改进。制造偏见是这个过程的一个固有部分。
总之,像这样的方法可以跨领域应用,从明显的国家安全应用到与健康相关的应用,比如在组织扫描中自动检测特定细胞类型,其准确性与人工计数相似,如果不是更高的话。稀有的飞机类型也可以通过测试合成数据的价值,改进检测技术,或评估零样本或少样本学习,实现计算机视觉领域的重大进步。我们希望引入类似的以应用为中心的研究和教程,以推动该领域向前发展。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~