
不容错过的12个深度学习面试问题
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自 | AI公园

这12个问题是当前面试中最热门的问题,既是非常基础的问题,也能看出面试者的水平,具有区分度。无论是面试官还是求职者都可以看看。

这些是我在面试人工智能工程师职位时经常问的问题。事实上,并不是所有的面试都需要使用所有这些问题,因为这取决于应聘者以前的经验和项目。通过大量的面试,特别是与学生的面试,我收集了 12 个在深度学习中最热门的面试问题,今天将在这篇文章中与大家分享。我希望能收到你的许多意见。好了,别再啰嗦了,我们开始吧。
这是一个非常好的问题,因为它涵盖了候选人在使用神经网络模型时需要知道的大部分知识。你可以用不同的方式回答,但需要阐明以下主要观点:

Batch Normalization 是训练神经网络模型的一种有效方法。该方法的目标是将特征(每层激活后的输出)归一化为均值为 0,标准差为 1。所以问题在于非零的均值是如何影响模型训练的:
首先,可以理解为非零均值是指数据不围绕 0 值分布,但数据中大多数值大于零或小于零。结合高方差问题,数据变得非常大或非常小。这个问题在训练层数很多的神经网络时很常见。特征没有在稳定区间内分布(由小到大),这将影响网络的优化过程。众所周知,优化神经网络需要使用导数计算。假设一个简单的层计算公式是 y = (Wx + b), y 对 w 的导数是:dy = dWx。因此,x 的取值直接影响导数的取值(当然,神经网络模型中梯度的概念并不是那么简单,但从理论上讲,x 会影响导数)。因此,如果 x 带来不稳定的变化,其导数可能太大,也可能太小,导致学习模型不稳定。这也意味着当使用 Batch Normalization 时我们可以在训练中使用更高的学习率。
Batch Normalization 可以避免 x 值经过非线性激活函数后趋于饱和的现象。因此,它确保激活值不会过高或过低。这有助于权重的学习,当不使用时有些权重可能永远无法进行学习,而用了之后,基本上都可以学习到。这有助于我们减少对参数初始值的依赖。
Batch Normalization 也是一种正则化形式,有助于最小化过拟合。使用 Batch Normalization,我们不需要使用太多的 dropput,这是有意义的,因为我们不需要担心丢失太多的信息,当我们实际使用的时候,仍然建议结合使用这两种技术。
什么是bias?可以理解,bias是当前模型的平均预测与我们需要预测的实际结果之间的差异。一个高 bias 的模型表明它对训练数据的关注较少。这使得模型过于简单,在训练和测试中都没有达到很好的准确性。这种现象也被称为欠拟合。
Variance 可以简单理解为模型输出在一个数据点上的分布。Variance 越大,模型越有可能密切关注训练数据,而不提供从未遇到过的数据的泛化。因此,该模型在训练数据集上取得了非常好的结果,但是与测试数据集相比,结果非常差,这就是过拟合的现象。
这两个概念之间的关系可以从下图中看出:
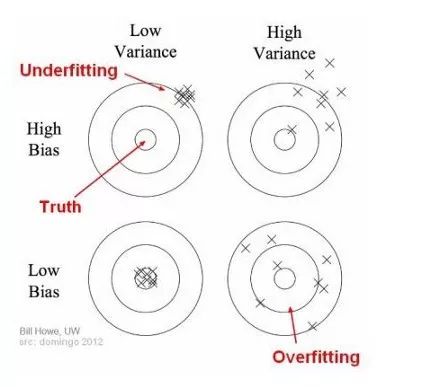
在上图中,圆的中心是一个模型,它完美地预测了精确的值。事实上,你从来没有发现过这么好的模型。当我们离圆的中心越来越远,我们的预测就越来越糟。
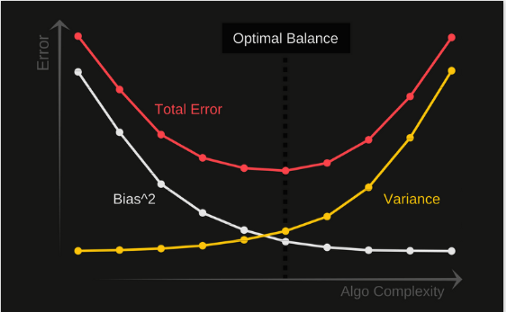
我们可以改变模型,这样我们就可以尽可能地增加落入圆中心的模型猜测的数量。需要在偏差值和方差值之间取得平衡。如果我们的模型过于简单,参数很少,那么它可能有高偏差和低方差。
另一方面,如果我们的模型有大量的参数,那么它就会有高方差和低偏差。这是我们在设计算法时计算模型复杂度的基础。
这个问题是关于深度学习算法在实践中的应用,这个问题的关键是数据的索引方法。这是将 One Shot learning 应用于人脸识别问题的最后一步,但这一步是在实践中进行部署的最重要的一步。
基本上,回答这个问题,你应该先描述一下 One Shot learning 来进行人脸识别的方法一般性方法。它可以简单地理解为将每个人脸转换成一个向量,而新的人脸识别是寻找与输入人脸最接近(最相似)的向量。通常,人们会使用 triplet loss 损失函数的深度学习模型来实现这一点。
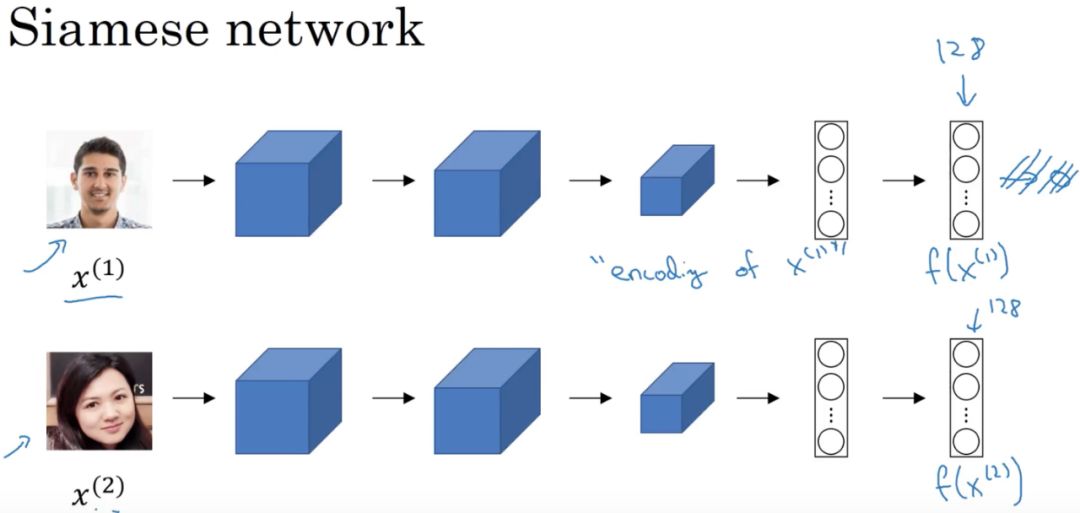
然而,随着图像数量的增加,在每次识别中计算到 1000 万个向量的距离并不是一个明智的解决方案,这使得系统的速度慢了很多。为了使查询更加方便,我们需要考虑在实向量空间上索引数据的方法。
这些方法的主要思想是将数据划分为便于查询新数据的结构(可能类似于树结构)。当有新数据可用时,在树中进行查询有助于快速找到距离最近的向量。

有好几种方法可以用于这种目的,比如Locality Sensitive Hashing—LSH,Approximate Nearest Neighbors — Annoy Indexing等等。
对于一个类问题,有许多不同的评估方法。在准确性方面,该公式简单地用正确预测数据点的个数除以总数据。这听起来很合理,但在现实中,对于不平衡的数据问题,这个数量还不够显著。假设我们正在构建一个网络攻击的预测模型(假设攻击请求占请求总数的 1/100000)。
如果模型预测所有请求都是正常的,那么准确率也达到 99.9999%,而这个数字在分类模型中通常是不可靠的。上面的精度计算通常向我们展示了有多少百分比的数据是正确预测的,但并没有详细说明如何对每个类进行分类。相反,我们可以使用混淆矩阵。基本上,混淆矩阵显示了有多少数据点实际上属于一个类,并且被预测属于一个类。其形式如下:
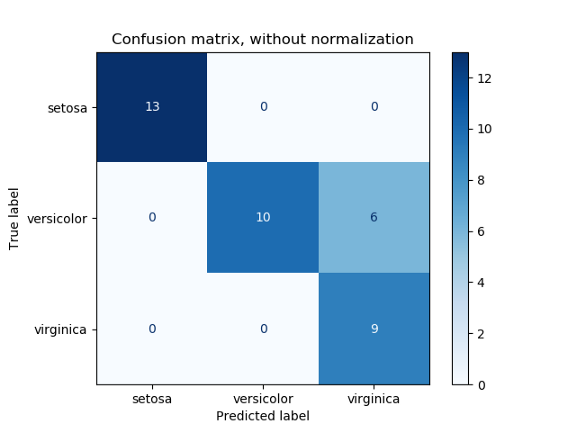
除了表示真阳性和假阳性指标对应于定义分类的每个阈值的变化外,我们还有一个 ROC 图。根据 ROC 曲线,我们可以知道模型是否有效。
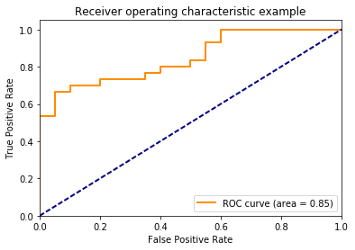
理想的 ROC 曲线是最接近左上角的橙色线。真阳性比较高,假阳性比较低。
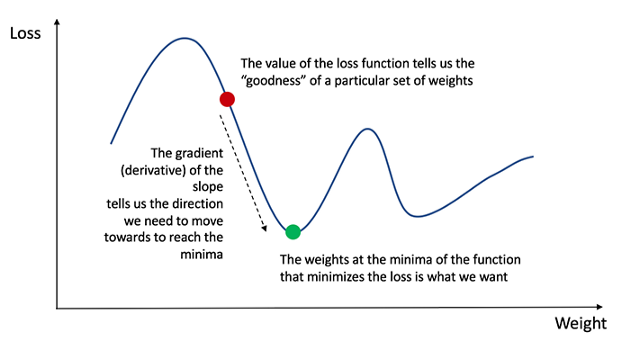
这个问题旨在检测你对于神经网络如何工作的知识。你需要讲清楚以下几点:
前向过程(前向计算)是一个帮助模型计算每一层权重的过程,其结果计算将产生一个yp结果。此时将计算损失函数的值,损失函数的值将显示模型的好坏。如果损失函数不够好,我们需要找到一种方法来降低损失函数的值。训练神经网络本质上是最小化损失函数。损失函数 L (yp, yt)表示yp模型的输出值与yt数据标签的实际值的差别程度。 为了降低损失函数的值,我们需要使用导数。反向传播帮助我们计算网络每一层的导数。根据每个层上的导数值,优化器(Adam、SGD、AdaDelta…)应用梯度下降更新网络的权重。 反向传播使用链式规则或导数函数计算每一层从最后一层到第一层的梯度值。
激活函数的意义
激活函数的产生是为了打破神经网络的线性特性。这些函数可以简单地理解为用一个滤波器来决定信息是否通过神经元。在神经网络训练中,激活函数在调节导数斜率中起着重要的作用。一些激活函数,如 sigmoid、fishy 或 ReLU,将在下面几节中进一步讨论。
然而,我们需要理解的是,这些非线性函数的性质使得神经网络能够学习比仅仅使用线性函数更复杂的函数的表示。大多数激活函数是连续可微函数。
这些函数是连续函数,也就是说,如果输入的变量很小且可微(在其定义域内的每一点都有导数),那么输出就会有一个小的变化。当然,如上所述,导数的计算是非常重要的,它是决定我们的神经元能否被训练的决定性因素。提几个常用的激活函数,如 Sigmoid, Softmax, ReLU。
激活函数的饱和区间
Tanh、Sigmoid、ReLU 等非线性激活函数都有饱和区间。
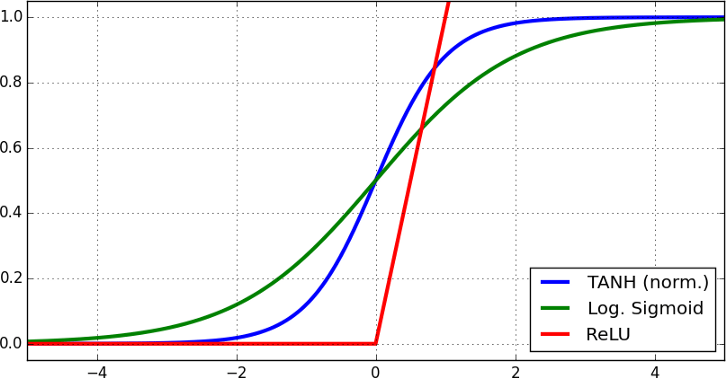
可以很容易理解的是,触发函数的饱和范围是指即使输入值改变,函数的输出值也不改变的区间。变化区间存在两个问题,即在神经网络的正向传播中,该层的数值逐渐落入激活函数的饱和区间,将逐渐出现多个相同的输出。
这将在整个模型中产生相同的数据流。这种现象就是协方差移位现象。第二个问题是,在反向传播中,导数在饱和区域为零,因此网络几乎什么都学不到。这就是我们需要将值范围设置为均值为 0 的原因,如 Batch 归一化一节中所述。
模型的参数是什么?
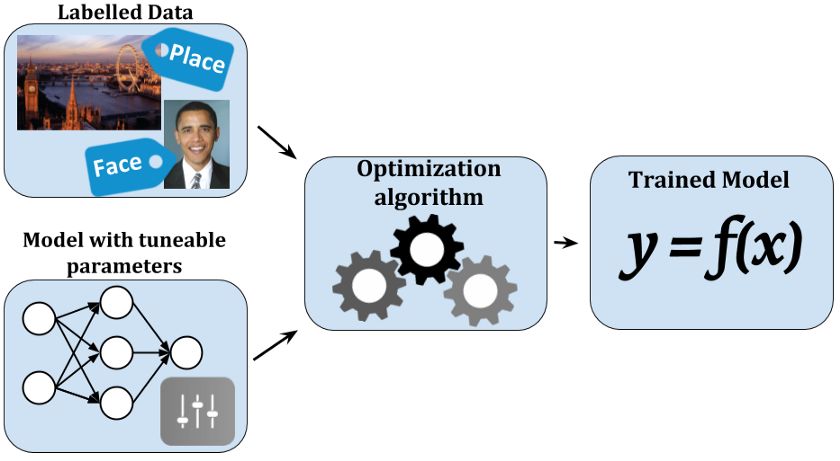
回到机器学习的本质上来,关于机器学习我们需要一个数据集,没有数据我们如何学习?一旦数据可用,机器需要在数据堆中找到输入和输出的联系。
假设我们的数据是温度、湿度、温度等天气信息,要求机器做的是找出上述因素与你老婆是否生气之间的联系。这听起来毫无关联,但机器学习在做的时候是相当愚蠢的。现在假设我们用变量y来表示我们的老婆是否生气了,变量 x1、x2、x3…代表天气元素。我们把求函数 f (x)归结为如下关系:
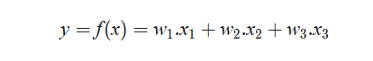
看到系数 w1 w2 w3 了吗。w_1, w_2, w_3 ..w1, w2, w3 ..?这就是我们要求的数据和元素之间的关系,也就是所谓的模型参数。因此,我们可以定义模型参数如下:
模型参数是由训练数据生成的模型值,用于帮助显示数据中数量之间的关系。
因此,当我们说找到问题的最佳模型时,应该意味着我们已经在现有的数据集上找到了最适合问题的模型参数。它具有以下几个特征:
用于预测新数据 它显示了我们使用的模型的能力。通常用准确性来表示,我们称之为准确率。 直接从训练数据集学习 通常不需要人工设置
模型参数有多种形式,如神经网络权值、支持向量机中的支持向量、线性回归或逻辑回归算法中的系数。
什么是模型的超参数?
我们经常假设模型超参数看起来像一个模型参数,但它不是真的。实际上这两个概念是完全分开的。如果模型参数是由训练数据集本身建模的,则模型超参数是完全不同的。它完全在模型之外,不依赖于训练数据。它的目的是什么?实际上,他们有以下几个任务:
用于训练过程中,帮助模型找到最合适的参数 它通常是由模型训练的参与者手工挑选的 它可以基于几种启发式策略来定义
对于一个特定的问题,我们完全不知道什么是最好的模型超参数。因此,在现实中,我们需要使用一些技术来估计最佳取值范围(例如 k 近邻模型中的k系数),如网格搜索。这里我想举几个模型超参数的例子:
训练人工神经网络时的学习率 训练支持向量机时的C和sigma参数 最近邻模型中的k系数
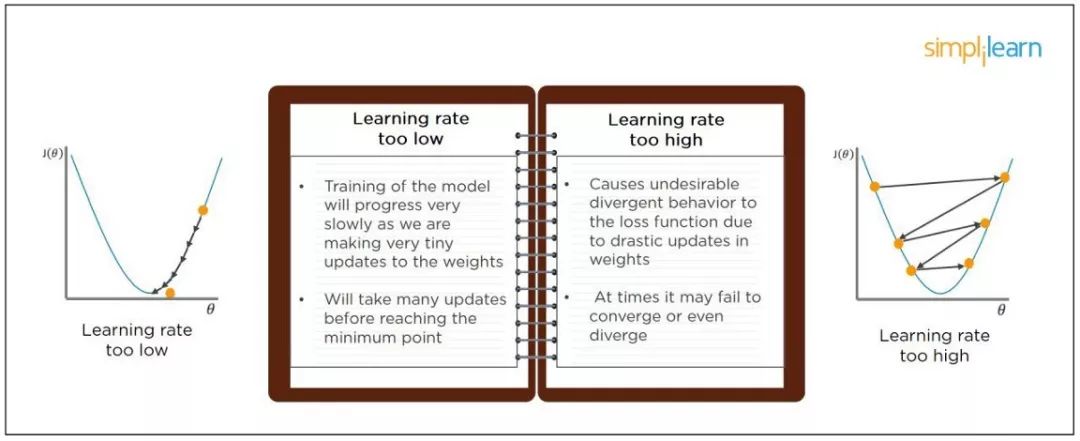
当模型的学习率被设置得太低时,模型训练将会进行得非常慢,因为它对权重进行非常小的更新。在到达局部最优点之前需要多次更新。
如果设定的学习率过高,则由于权值更新过大,模型可能会不收敛。有可能在一个更新权值的步骤中,模型跳出了局部优化,使得模型以后很难更新到最优点,而是在在局部优化点附近跳来跳去。
对于候选人来说,这是一个非常误导人的问题,因为大多数人会把注意力放在 CNN 参数的数量会增加多少倍的问题上。然而,让我们来看看 CNN 的架构:
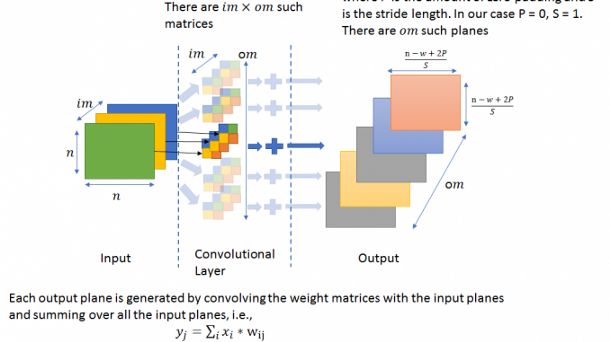
我们可以看到,CNN 模型的参数数量取决于滤波器的数量和大小,而不是输入图像。因此,将图像的大小加倍并不会改变模型的参数数量。
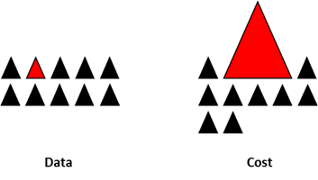
这是一个测试候选人处理真实数据问题的方法的问题。通常,实际数据和标准数据集在数据集的属性和数据量方面差异很大(标准数据集不需要调整)。对于实际的数据集,可能会出现数据不平衡的情况,即类之间的数据不平衡。我们现在可以考虑以下技术:
选择正确的度量来评估模型:对于不平衡的数据集,使用准确性来评估是一项非常危险的工作,如上面几节所述。应选择精度、召回、F1 分数、AUC等合适的评价量。
重新采样训练数据集:除了使用不同的评估标准,人们还可以使用一些技术来获得不同的数据集。从一个不平衡的数据集中创建一个平衡的数据集有两种方法,即欠采样和过采样,具体技术包括重复、bootstrapping 或 hits(综合少数过采样技术)等方法。
许多不同模型的集成:通过创建更多的数据来概括模型在实践中并不总是可行的。例如,你有两个层,一个拥有 1000 个数据的罕见类,一个包含 10,000 个数据样本的大型类。因此,我们可以考虑一个 10 个模型的训练解决方案,而不是试图从一个罕见的类中找到 9000 个数据样本来进行模型训练。每个模型由 1000 个稀有类和 1000 个大规模类训练而成。然后使用集成技术获得最佳结果。
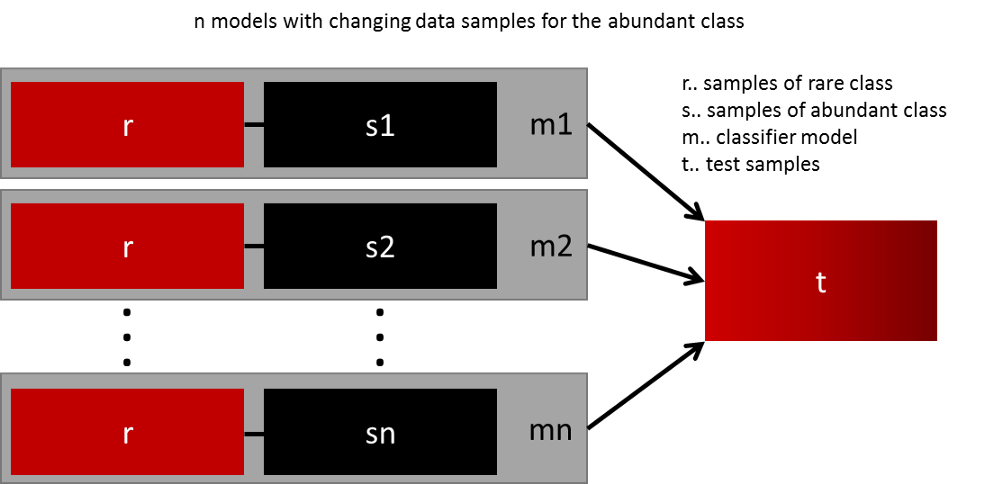
重新设计模型 — 损失函数:使用惩罚技术对代价函数中的多数类进行严厉惩罚,帮助模型本身更好地学习稀有类的数据。这使得损失函数的值在类中更全面。
Epoch:表示整个数据集的迭代(所有内容都包含在训练模型中)。 Batch:是指当我们不能一次将整个数据集放到神经网络中时,我们将数据集分割成几批较小的数据集。 迭代:是运行 epoch 所需的批数。假设有 10,000 个图像作为数据,批处理的大小(batch_size)为 200。然后一个 epoch 将包含 50 个迭代(10,000 除以 200)。
数据生成器在写代码中很重要,数据生成函数帮助我们直接生成数据,然后送到模型中进行每个 batch 的训练。

利用生成函数对训练大数据有很大帮助。因为数据集并不总是需要全部加载到 RAM 中,这是一种内存的浪费,而且如果数据集太大,会导致内存溢出,输入数据的处理时间会变长。
以上是我在面试过程中经常问应聘者的 12 个关于深度学习的面试问题。然而,根据每个候选人的不同,提问的方式也会不同,或者还有一些问题是随机从候选人的问题中提出的。
虽然这篇文章是关于技术问题的,但是与面试相关,并且基于我个人的观点,态度决定了面试成功的 50%。所以,除了积累自己的知识和技能,总是用真诚、进步、谦虚的态度来表达自己,你一定会在任何对话中取得成功。我希望你早日实现你的愿望。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~