
深入理解CPU和异构计算芯片GPU/FPGA/ASIC


王玉伟,腾讯TEG架构平台部平台开发中心基础研发组,组长为专家工程师Austingao,专注于为数据中心提供高效的异构加速云解决方案。目前,FPGA已在腾讯海量图片处理以及检测领域已规模上线。
1 异构计算:WHY

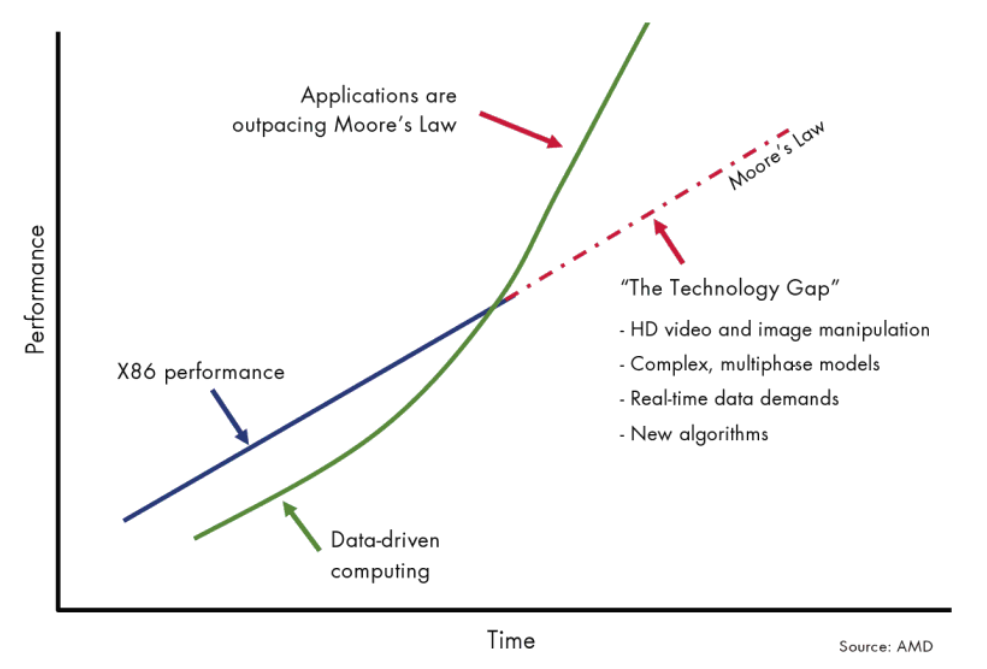
2 异构计算:STANDARDS
3.2 芯片计算性能
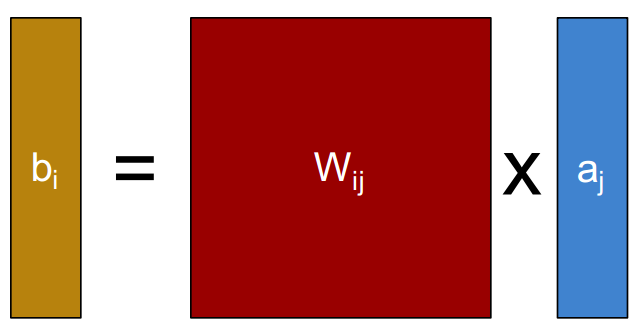
3.2.1 CPU计算能力分析
这里 CPU 计算能力用 Intel 的 Haswell 架构进行分析,Haswell架构上计算单元有2个FMA(fused multiply-add),每个FMA可以对256bit数据在一个时钟周期中做一次乘运算和一次加运算,所以对应32bit单精度浮点计算能力为:(256bit/32bit) 2(FMA) 2(乘和加) = 32 SP FLOPs/cycle,即每个时钟周期可以做32个单精度浮点计算。
CPU峰值浮点计算性能 = CPU核数 CPU频率 每周期执行的浮点操作数。已Intel的CPU型号E5-2620V3来计算峰值计算能力为 = 6(CPU核数) 2.4GHz(CPU频率) 32 SP FLOPs/cycle = 460.8 GFLOPs/s 即每秒460G峰值浮点计算能力。
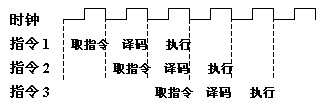
CPU芯片结构是否可以充分发挥浮点计算能力?CPU的指令执行过程是:取指令 ->指令译码 ->指令执行,只有在指令执行的时候,计算单元才发挥作用,这样取指令和指令译码的两段时间,计算单元是不在工作的,如图4所示。

CPU为了提高指令执行的效率,在当前指令执行过程的时候,预先读取后面几条指令,使得指令流水处理,提高指令执行效率,如图5所示。指令预先读取并流水执行的前提是指令之间不具有相关性,不能一个指令的如何执行需要等到前面一个指令执行完的结果才可以获知。
CPU作为通用处理器,兼顾计算和控制,70%晶体管用来构建Cache 还有一部分控制单元,用来处理复杂逻辑和提高指令的执行效率,如图6所示,所以导致计算通用性强,可以处理计算复杂度高,但计算性能一般。
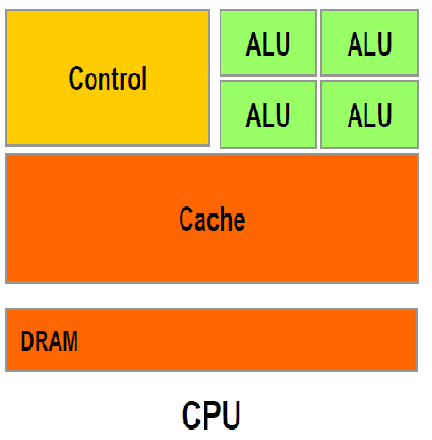
通过CPU计算性能分析,直接提高计算性能方向为:增加CPU核数、提高CPU频率、修改CPU架构增加计算单元FMA(fused multiply-add)个数。这3个方向中,直接增加CPU核数对于计算能力提升最高,但是带来芯片功耗和价格的增加,因为每个物理核中只有30%的晶体管是计算单元。提高CPU频率,提升的空间有限,而且CPU频率太高会导致芯片出现功耗过大和过热的问题,因此英特尔等芯片制造商目前走多核化的路线,即限制单个微处理器的主频,通过集成多个处理器内核来提高处理性能。修改CPU架构增加计算单元FMA个数,目前英特尔按照“Tick-Tock”二年一个周期进行CPU架构调整,从2016年开始放缓至三年,更新迭代周期较长。
3.2.2 GPU计算能力分析
GPU主要擅长做类似图像处理的并行计算,所谓的“粗粒度并行(coarse-grain parallelism)”。图形处理计算的特征表现为高密度的计算而计算需要的数据之间较少存在相关性,GPU 提供大量的计算单元(多达几千个计算单元)和大量的高速内存,可以同时对很多像素进行并行处理。
图7是GPU的设计结构。GPU的设计出发点在于GPU更适用于计算强度高、多并行的计算。因此,GPU把晶体管更多用于计算单元,而不像CPU用于数据Cache和流程控制器。这样的设计是因为并行计算时每个数据单元执行相同程序,不需要繁琐的流程控制而更需要高计算能力,因此也不需要大的cache容量。

GPU中一个逻辑控制单元对应多个计算单元,同时要想计算单元充分并行起来,逻辑控制必然不会太复杂,太复杂的逻辑控制无法发挥计算单元的并行度,例如过多的if…else if…else if… 分支计算就无法提高计算单元的并行度,所以在GPU中逻辑控制单元也就不需要能够快速处理复杂控制。
这里GPU计算能力用Nvidia的Tesla K40进行分析,K40包含2880个流处理器(Stream Processor),流处理器就是GPU的计算单元。每个流处理器包含一个32bit单精度浮点乘和加单元,即每个时钟周期可以做2个单精度浮点计算。GPU峰值浮点计算性能 = 流处理器个数 GPU频率 每周期执行的浮点操作数。以K40为例,K40峰值浮点计算性能= 2880(流处理器) 745MHz 2(乘和加) = 4.29T FLOPs/s即每秒4.29T峰值浮点计算能力。
GPU芯片结构是否可以充分发挥浮点计算能力?GPU同CPU一样也是指令执行过程:取指令 ->指令译码 ->指令执行,只有在指令执行的时候,计算单元才发挥作用。GPU的逻辑控制单元相比CPU简单,所以要想做到指令流水处理,提高指令执行效率,必然要求处理的算法本身复杂度低,处理的数据之间相互独立,所以算法本身的串行处理会导致GPU浮点计算能力的显著降低。
3.2.3 FPGA计算能力分析
FPGA作为一种高性能、低功耗的可编程芯片,可以根据客户定制来做针对性的算法设计。所以在处理海量数据的时候,FPGA 相比于CPU 和GPU,优势在于:FPGA计算效率更高,FPGA更接近IO。
FPGA不采用指令和软件,是软硬件合一的器件。对FPGA进行编程要使用硬件描述语言,硬件描述语言描述的逻辑可以直接被编译为晶体管电路的组合。所以FPGA实际上直接用晶体管电路实现用户的算法,没有通过指令系统的翻译。
FPGA的英文缩写名翻译过来,全称是现场可编程逻辑门阵列,这个名称已经揭示了FPGA的功能,它就是一堆逻辑门电路的组合,可以编程,还可以重复编程。图8展示了可编程FPGA的内部原理图。
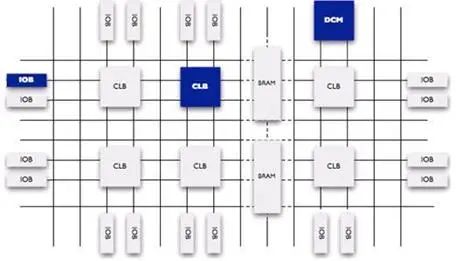
这里FPGA计算能力用Xilinx的V7-690T进行分析,V7-690T包含3600个DSP(Digital Signal Processing),DSP就是FPGA的计算单元。每个DSP可以在每个时钟周期可以做2个单精度浮点计算(乘和加)。FPGA峰值浮点计算性能 = DSP个数 FPGA频率 每周期执行的浮点操作数。V7-690T运行频率已250MHz来计算,V7-690T峰值浮点计算性能 = 3600(DSP个数) 250MHz 2(乘和加)=1.8T FLOPs/s即每秒1.8T峰值浮点计算能力。
FPGA芯片结构是否可以充分发挥浮点计算能力?FPGA由于算法是定制的,所以没有CPU和GPU的取指令和指令译码过程,数据流直接根据定制的算法进行固定操作,计算单元在每个时钟周期上都可以执行,所以可以充分发挥浮点计算能力,计算效率高于CPU和GPU。
3.2.4 ASIC计算能力分析
ASIC是一种专用芯片,与传统的通用芯片有一定的差异。是为了某种特定的需求而专门定制的芯片。ASIC芯片的计算能力和计算效率都可以根据算法需要进行定制,所以ASIC与通用芯片相比,具有以下几个方面的优越性:体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低。但是缺点也很明显:算法是固定的,一旦算法变化就可能无法使用。目前人工智能属于大爆发时期,大量的算法不断涌出,远没有到算法平稳期,ASIC专用芯片如何做到适应各种算法是个最大的问题,如果以目前CPU和GPU架构来适应各种算法,那ASIC专用芯片就变成了同CPU、GPU一样的通用芯片,在性能和功耗上就没有优势了。
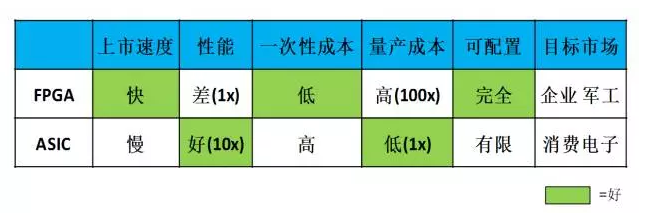
我们来看看FPGA 和 ASIC 的区别。FPGA基本原理是在芯片内集成大量的数字电路基本门电路以及存储器,而用户可以通过烧入 FPGA 配置文件来来定义这些门电路以及存储器之间的连线。这种烧入不是一次性的,即用户今天可以把 FPGA 配置成一个微控制器 MCU,明天可以编辑配置文件把同一个 FPGA 配置成一个音频编解码器。ASIC 则是专用集成电路,一旦设计制造完成后电路就固定了,无法再改变。
比较 FPGA 和 ASIC 就像比较乐高积木和模型。举例来说,如果你发现最近星球大战里面 Yoda 大师很火,想要做一个 Yoda 大师的玩具卖,你要怎么办呢?
有两种办法,一种是用乐高积木搭,还有一种是找工厂开模定制。用乐高积木搭的话,只要设计完玩具外形后去买一套乐高积木即可。而找工厂开模的话在设计完玩具外形外你还需要做很多事情,比如玩具的材质是否会散发气味,玩具在高温下是否会融化等等,所以用乐高积木来做玩具需要的前期工作比起找工厂开模制作来说要少得多,从设计完成到能够上市所需要的时间用乐高也要快很多。
FPGA 和 ASIC 也是一样,使用 FPGA 只要写完 Verilog 代码就可以用 FPGA 厂商提供的工具实现硬件加速器了,而要设计 ASIC 则还需要做很多验证和物理设计 (ESD,Package 等等),需要更多的时间。如果要针对特殊场合(如军事和工业等对于可靠性要求很高的应用),ASIC 则需要更多时间进行特别设计以满足需求,但是用 FPGA 的话可以直接买军工级的高稳定性 FPGA 完全不影响开发时间。但是,虽然设计时间比较短,但是乐高积木做出来的玩具比起工厂定制的玩具要粗糙(性能差)一些(下图),毕竟工厂开模是量身定制。
另外,如果出货量大的话,工厂大规模生产玩具的成本会比用乐高积木做便宜许多。FPGA 和 ASIC 也是如此,在同一时间点上用最好的工艺实现的 ASIC 的加速器的速度会比用同样工艺 FPGA 做的加速器速度快 5-10 倍,而且一旦量产后 ASIC 的成本会远远低于 FPGA 方案。
FPGA 上市速度快, ASIC 上市速度慢,需要大量时间开发,而且一次性成本(光刻掩模制作成本)远高于 FPGA,但是性能高于 FPGA 且量产后平均成本低于 FPGA。目标市场方面,FPGA 成本较高,所以适合对价格不是很敏感的地方,比如企业应用,军事和工业电子等等(在这些领域可重配置真的需要)。而 ASIC 由于低成本则适合消费电子类应用,而且在消费电子中可配置是否是一个伪需求还有待商榷。
我们看到的市场现状也是如此:使用 FPGA 做深度学习加速的多是企业用户,百度、微软、IBM 等公司都有专门做 FPGA 的团队为服务器加速,而做 FPGA 方案的初创公司 Teradeep 的目标市场也是服务器。而 ASIC 则主要瞄准消费电子,如 Movidius。由于移动终端属于消费电子领域,所以未来使用的方案应当是以 ASIC 为主。
3.3平台性能和功耗比较
由于不同的芯片生产工艺,对芯片的功耗和性能都有影响,这里用相同工艺或者接近工艺下进行对比,ASIC芯片还没有商用的芯片出现,Google的TPU也只是自己使用没有对外提供信息,这里ASIC芯片用在学术论文发表的《DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning》作为代表。
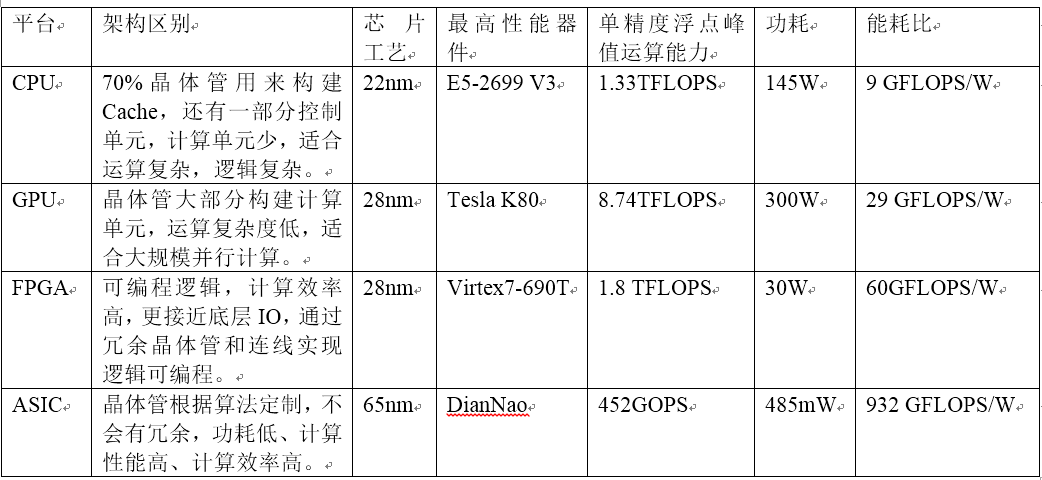
从上面的对比来看,能耗比方面:ASIC > FPGA > GPU > CPU,产生这样结果的根本原因:对于计算密集型算法,数据的搬移和运算效率越高的能耗比就越高。ASIC和FPGA都是更接近底层IO,所以计算效率高和数据搬移高,但是FPGA有冗余晶体管和连线,运行频率低,所以没有ASIC能耗比高。GPU和CPU都是属于通用处理器,都需要进行取指令、指令译码、指令执行的过程,通过这种方式屏蔽了底层IO的处理,使得软硬件解耦,但带来数据的搬移和运算无法达到更高效率,所以没有ASIC、FPGA能耗比高。
GPU和CPU之间的能耗比的差距,主要在于CPU中晶体管有大部分用在cache和控制逻辑单元,所以CPU相比GPU来说,对于计算密集同时计算复杂度低的算法,有冗余的晶体管无法发挥作用,能耗比上CPU低于GPU。
4 总结与展望
处理器芯片各自长期发展的过程中,形成了一些使用和市场上鲜明的特点。CPU&GPU领域存在大量的开源软件和应用软件,任何新的技术首先会用CPU实现算法,因此CPU编程的资源丰富而且容易获得,开发成本低而开发周期。
FPGA的实现采用Verilog/VHDL等底层硬件描述语言实现,需要开发者对FPGA的芯片特性有较为深入的了解,但其高并行性的特性往往可以使业务性能得到量级的提升;同时FPGA是动态可重配的,当在数据中心部署之后,可以根据业务形态来配置不同的逻辑实现不同的硬件加速功能;举例来讲,当前服务器上的FPGA板卡部署的是图片压缩逻辑,服务于QQ业务;而此时广告实时预估需要扩容获得更多的FPGA计算资源,通过简单的FPGA重配流程,FPGA板卡即可以变身成“新”硬件来服务广告实时预估,非常适合批量部署。
ASIC芯片可以获得最优的性能,即面积利用率高、速度快、功耗低;但是AISC开发风险极大,需要有足够大的市场来保证成本价格,而且从研发到市场的时间周期很长,不适合例如深度学习CNN等算法正在快速迭代的领域。
5、业界成功案例
讲了这么多,当遇到业务瓶颈的需要异构计算芯片的时候,你是否能够根据业务特性和芯片特性选择出合适的芯片呢?
当今的FPGA有很大的性能潜力,支持深度可变的流水线结构,提供大量的并行计算资源,一个时钟周期内就可以完成非常复杂的功能。FPGA的可编程能力保证了这种器件能够满足应用软件的特殊需求,不存在设计定制协处理器的成本或者延迟问题。FPGA是重新可编程的,它可以在一个芯片中为多种应用提供非常灵活的定制协处理功能。拥有了FPGA,业务就拥有无限可能。同样的半导体技术,既能把处理器的性能发挥到极限,也能使FPGA从简单的胶合逻辑控制器,发展到性能很高的可编程架构。FPGA完全能够满足HPC市场的“4P”需求。
FPGA的内置存储器也有很大的性能优势。例如,片内存储器意味着协处理器逻辑的存储器访问带宽不会受到器件I/O引脚数量的限制。而且,存储器和运算逻辑紧密结合,不再需要采用外部高速存储器缓冲。这样,也避免了大功耗的缓冲访问和一致性问题。使用内部存储器还意味着协处理器不需要其他的I/O引脚来提高其可访问存储器容量,从而简化了设计。
很多人由于FPGA的开发难度大以及开发周期较长而对其持有怀疑态度,好消息是HLS以及OpenCL语言越来越完善,很多应用直接使用这两种高级语言就可以取得较大性能提升。
为了更好地满足对计算性能的要求,全球的很多大型IT企业都在FPGA的加速硬件上进行了布局和实践。
Intel:Intel决定以167亿美元收购FPGA生产商Altera。Intel预计到2020年,30%以上的服务器CPU芯片将配备一个FPGA协处理器。
IBM:IBM和Xilinx联合宣布开展一项多年战略协作,在IBM POWER系统上运用Xilinx FPGA加速工作负载处理技术,以打造更高性能、更高能效的数据中心应用。
微软:早在2014年,Microsoft就将Altera FPGA运用在其Bing搜索的业务中,使Bing的搜索处理量提升了一倍,搜索时间缩短了29%。2015年,微软进一步将FPGA运用于深度学习领域。2016年,微软体系结构顶级会议Micro上发表的《A Cloud-Scale Acceleration Architecture》显示了其在数据中心体系架构上的勃勃野心。现在,进入微软数据中心的每一个服务器上均带有一块FPGA板卡,其基本的架构如下:
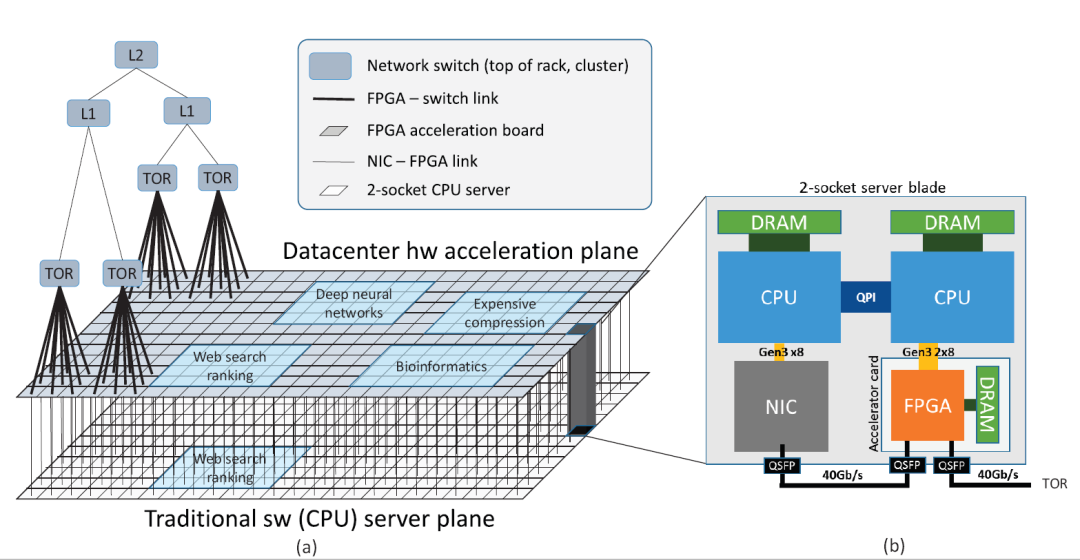
论文中涉及到的应用场景包括:1.网络加速(例如网络数据包加解密);2.本地应用加速(Bing加速、DNN延时敏感性业务加速);3.支持fpga之间通信,fpga计算资源池化,提供Hardware-as-a-Service的概念,将FPGA和服务器解耦。
Facebook:2016年,Facebook也宣称要同Intel合作用Xeon-FPGA平台进行数据中心的建设。
百度:国内百度也推出了FPGA版本的百度大脑,运用到线上服务;FPGA版百度大脑已运用于包括语音识别、广告点击率预估模型、DNA序列检测以及无人车等业务中。据了解,应用了该版本百度大脑后,语音在线服务、广告点击率预估模型等的计算性能皆提升了3~4倍。
来源:
https://cloud.tencent.com/developer/article/1004747
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收188元(原总价290元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
