
GPU、FPGA和ASIC


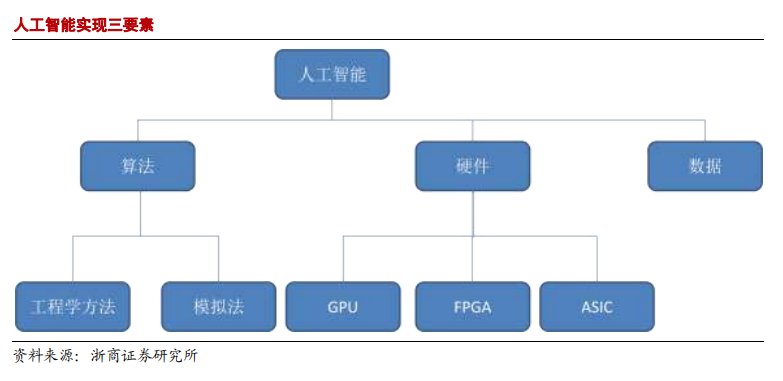
人工智能包括三个要素:算法,计算和数据。对人工智能的实现来说,算法是核心,计算、数据是基础。在算法上来说,主要分为工程学法和模拟法。
下载链接:GPU,FPGA和ASIC

工程学方法是采用传统的编程技术,利用大量数据处理经验改进提升算法性能;模拟法则是模仿人类或其他生物所用的方法或者技能,提升算法性能,例如遗传算法和神经网络。而在计算能力来说,目前主要是使用 GPU 并行计算神经网络,同时,FPGA 和 ASIC 也将是未来异军突起的力量。
随着百度、Google、Facebook、微软等企业开始切入人工智能,人工智能可应用的领域非常广泛。可以看到,未来人工智能的应用将呈几何级数的倍增。应用领域包括互联网,金融,娱乐,政府机关,制造业,汽车,游戏等。从产业结构来讲,人工智能生态分为基础、技术、应用三层。应用层包括人工智能+各行业(领域),技术层包括算法、模型及应用开发,基础层包括数据资源和计算能力。
人工智能将在很多领域得到广泛的应用。目前重点部署的应用有:语音识别,人脸识别,无人机,机器人,无人驾驶等。
人工智能的核心是算法,深度学习是目前最主流的人工智能算法。深度学习在 1958 年就被提出,但直到最近,才真正火起来,主要原因在于:数据量的激增和计算机能力/成本。
深度学习是机器学习领域中对模式(声音、图像等等)进行建模的一种方法,它也是一种基于统计的概率模型。在对各种模式进行建模之后,便可以对各种模式进行识别了,例如待建模的模式是声音的话,那么这种识别便可以理解为语音识别。而类比来理解,如果说将机器学习算法类比为排序算法,那么深度学习算法便是众多排序算法当中的一种,这种算法在某些应用场景中,会具有一定的优势。
深度学习的学名又叫深层神经网络(Deep Neural Networks ),是从很久以前的人工神经网络(Artificial Neural Networks)模型发展而来。这种模型一般采用计算机科学中的图模型来直观的表达,而深度学习的“深度”便指的是图模型的层数以及每一层的节点数量,相对于之前的神经网络而言,有了很大程度的提升。
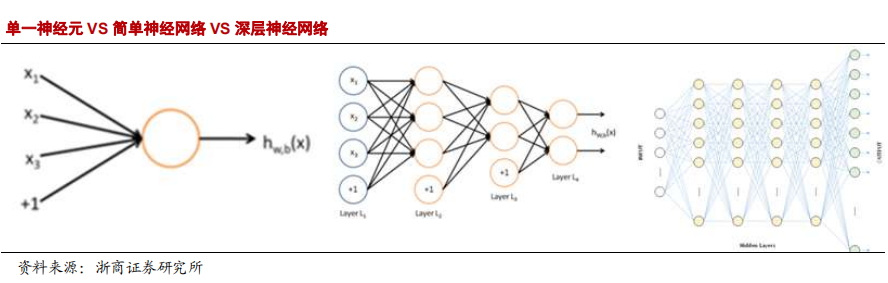
从单一的神经元,再到简单的神经网络,到一个用于语音识别的深层神经网络。层次间的复杂度呈几何倍数的递增。
以图像识别为例,图像的原始输入是像素,相邻像素组成线条,多个线条组成纹理,进一步形成图案,图案构成了物体的局部,直至整个物体的样子。不难发现,可以找到原始输入和浅层特征之间的联系,再通过中层特征,一步一步获得和高层特征的联系。想要从原始输入直接跨越到高层特征,无疑是困难的。而整个识别过程,所需要的数据量和运算量是十分巨大的。
深度学习之所以能够在今天得到重要的突破,原因在于:
1、海量的数据训练
2、高性能的计算能力(CPU,GPU,FPGA,ASIC),两者缺一不可。
衡量芯片计算性能的重要指标称为算力。通常而言,将每秒所执行的浮点运算次数(亦称每秒峰值速度)作为指标来衡量算力,简称为 FLOPS。现有的主流芯片运算能力达到了 TFLOPS 级别。一个 TFLOPS(teraFLOPS)等於每秒万亿(=10^12)次的浮点运算。增加深度学习算力需要多个维度的齐头并进的提升:
1、系统并行程度
2、时钟的速度
3、内存的大小(包括register、cache、memory);
4、内存带宽(memory bandwidth)
5、计算芯片同 CPU 之间的带宽
6、还有各种微妙的硬件里的算法改进。
我们这篇报告将主要关注人工智能的芯片领域,着重讨论 GPU,FPGA,ASIC 等几种类型的芯片在人工智能领域的应用和未来的发展。
GPU,又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上图像运算工作的微处理器,与 CPU 类似,只不过 GPU 是专为执行复杂的数学和几何计算而设计的,这些计算是图形渲染所必需的。随着人工智能的发展,如今的 GPU 已经不再局限于 3D 图形处理了,GPU 通用计算技术发展已经引起业界不少的关注,事实也证明在浮点运算、并行计算等部分计算方面,GPU 可以提供数十倍乃至于上百倍于 CPU 的性能。
GPU 的特点是有大量的核(多达几千个核)和大量的高速内存,最初被设计用于游戏,计算机图像处理等。GPU主要擅长做类似图像处理的并行计算,所谓的“粗粒度并行(coarse-grain parallelism)”。这个对于图像处理很适用,因为像素与像素之间相对独立,GPU 提供大量的核,可以同时对很多像素进行并行处理。但这并不能带来延迟的提升(而仅仅是处理吞吐量的提升)。
比如,当一个消息到达时,虽然 GPU 有很多的核,但只能有其中一个核被用来处理当前这个消息,而且 GPU 核通常被设计为支持与图像处理相关的运算,不如 CPU 通用。GPU 主要适用于在数据层呈现很高的并行特性(data-parallelism)的应用,比如 GPU 比较适合用于类似蒙特卡罗模拟这样的并行运算。
CPU 和 GPU 本身架构方式和运算目的不同导致了 CPU 和 GPU 之间的不同,主要不同点列举如下。
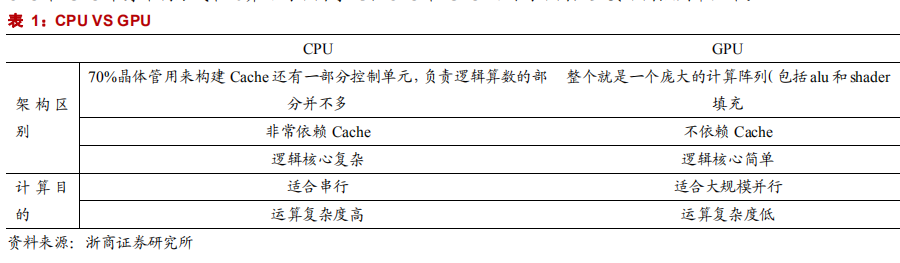
正是因为 GPU 的特点特别适合于大规模并行运算,GPU 在 “深度学习”领域发挥着巨大的作用,因为 GPU 可以平行处理大量琐碎信息。深度学习所依赖的是神经系统网络——与人类大脑神经高度相似的网络——而这种网络出现的目的,就是要在高速的状态下分析海量的数据。例如,如果你想要教会这种网络如何识别出猫的模样,你就要给它提供无数多的猫的图片。而这种工作,正是 GPU 芯片所擅长的事情。而且相比于 CPU,GPU 的另一大优势,就是它对能源的需求远远低于 CPU。GPU 擅长的是海量数据的快速处理。
虽然机器学习已经有数十年的历史,但是两个较为新近的趋势促进了机器学习的广泛应用: 海量训练数据的出现以及 GPU 计算所提供的强大而高效的并行计算。人们利用 GPU 来训练这些深度神经网络,所使用的训练集大得多,所耗费的时间大幅缩短,占用的数据中心基础设施也少得多。GPU 还被用于运行这些机器学习训练模型,以便在云端进行分类和预测,从而在耗费功率更低、占用基础设施更少的情况下能够支持远比从前更大的数据量和吞吐量。
将 GPU 加速器用于机器学习的早期用户包括诸多规模的网络和社交媒体公司,另外还有数据科学和机器学习领域中一流的研究机构。与单纯使用 CPU 的做法相比,GPU 具有数以千计的计算核心、可实现 10-100 倍应用吞吐量,因此 GPU 已经成为数据科学家处理大数据的处理器。
综上而言,我们认为人工智能时代的 GPU 已经不再是传统意义上的图形处理器,而更多的应该赋予专用处理器的头衔,具备强大的并行计算能力。
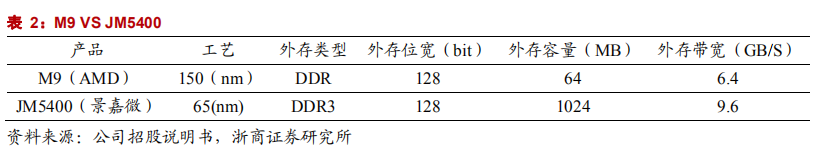
国内在 GPU 芯片设计方面,还处于起步阶段,与国际主流产品尚有一定的差距。不过星星之火,可以燎原。有一些企业,逐渐开始拥有自主研发的能力,比如国内企业景嘉微。景嘉微拥有国内首款自主研发的 GPU 芯片 JM5400,专用于公司的图形显控领域。JM5400 为代表的图形芯片打破外国芯片在我国军用 GPU 领域的垄断,率先实现军用 GPU国产化。GPU JM5400 主要替代 AMD 的 GPU M9,两者在性能上的比较如下。相比而言,公司的 JM5400 具有功耗低,性能优的优势。
FPGA,即现场可编程门阵列,它是在 PAL、GAL、CPLD 等可编程器件的基础上进一步发展的产物。FPGA 芯片主要由 6 部分完成,分别为:可编程输入输出单元、基本可编程逻辑单元、完整的时钟管理、嵌入块式 RAM、丰富的布线资源、内嵌的底层功能单元和内嵌专用硬件模块。
FPGA 还具有静态可重复编程和动态在系统重构的特性,使得硬件的功能可以像软件一样通过编程来修改。FPGA能完成任何数字器件的功能,甚至是高性能 CPU 都可以用 FPGA 来实现。
FPGA 拥有大量的可编程逻辑单元,可以根据客户定制来做针对性的算法设计。除此以外,在处理海量数据的时候,FPGA 相比于 CPU 和 GPU,独到的优势在于:FPGA 更接近 IO。换句话说,FPGA是硬件底层的架构。比如,数据采用 GPU 计算,它先要进入内存,并在 CPU 指令下拷入 GPU 内存,在那边执行结束后再拷到内存被 CPU 继续处理,这过程并没有时间优势;而使用 FPGA 的话,数据 I/O 接口进入 FPGA,在里面解帧后进行数据处理或预处理,然后通过 PCIE 接口送入内存让 CPU 处理,一些很底层的工作已经被 FPGA 处理完毕了(FPGA 扮演协处理器的角色),且积累到一定数量后以 DMA 形式传输到内存,以中断通知 CPU 来处理,这样效率就高得多。
虽然 FPGA 的频率一般比 CPU 低,但 CPU 是通用处理器,做某个特定运算(如信号处理,图像处理)可能需要很多个时钟周期,而 FPGA 可以通过编程重组电路,直接生成专用电路,加上电路并行性,可能做这个特定运算只需要一个时钟周期。
比如一般 CPU 每次只能处理 4 到 8 个指令,在 FPGA 上使用数据并行的方法可以每次处理 256 个或者更多的指令,让FPGA可以处理比CPU多很多的数据量。
举个例子,CPU 主频 3GHz,FPGA主频 200MHz,若做某个特定运算 CPU 需要 30 个时钟周期,FPGA 只需一个,则耗时情况:CPU:30/3GHz =10ns;FPGA:1/200MHz =5ns。可以看到,FPGA 做这个特定运算速度比 CPU 块,能帮助加速。
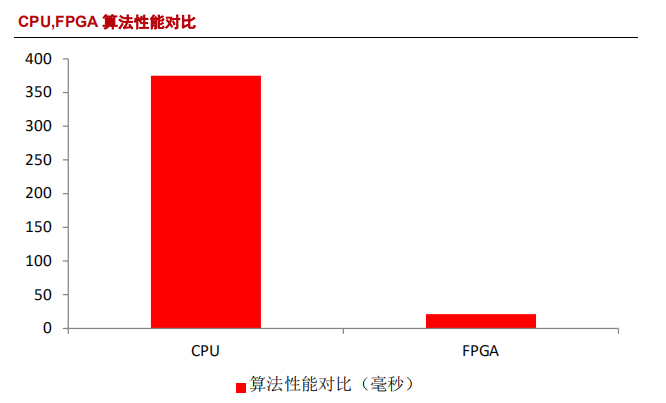
北京大学与加州大学的一个关于 FPGA 加速深度学习算法的合作研究。展示了 FPGA 与 CPU 在执行深度学习算法时的耗时对比。在运行一次迭代时,使用 CPU 耗时 375 毫秒,而使用 FPGA 只耗时 21 毫秒,取得了18倍左右的加速比。
FPGA 相对于 CPU 与 GPU 有明显的能耗优势,主要有两个原因。首先,在 FPGA 中没有取指令与指令译码操作, 在 Intel 的 CPU 里面,由于使用的是 CISC 架构,仅仅译码就占整个芯片能耗的 50%;在 GPU 里面,取指令与译码也消耗了 10%~20%的能耗。其次,FPGA 的主频比 CPU 与 GPU 低很多,通常 CPU 与 GPU 都在 1GHz 到 3GHz 之间,而 FPGA 的主频一般在 500MHz 以下。如此大的频率差使得 FPGA 消耗的能耗远低于 CPU 与 GPU。
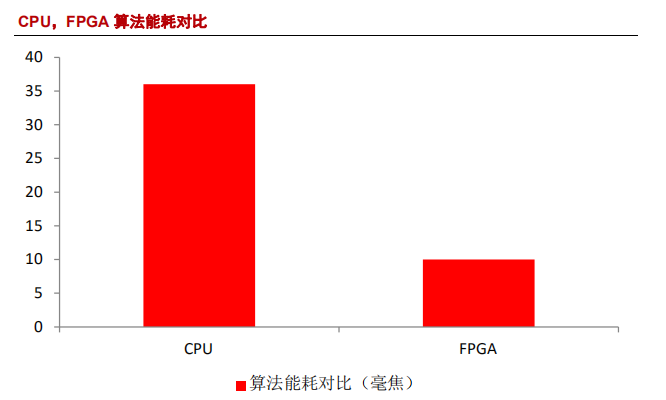
FPGA与CPU在执行深度学习算法时的耗能对比。在执行一次深度学习运算,使用 CPU 耗能 36 焦,而使用 FPGA 只耗能 10 焦,取得了 3.5 倍左右的节能比。通过用 FPGA 加速与节能,让深度学习实时计算更容易在移动端运行。
相比CPU和GPU,FPGA 凭借比特级细粒度定制的结构、流水线并行计算的能力和高效的能耗,在深度学习应用中展现出独特的优势,在大规模服务器部署或资源受限的嵌入式应用方面有巨大潜力。此外,FPGA 架构灵活,使得研究者能够在诸如 GPU 的固定架构之外进行模型优化探究。
ASIC(专用集成电路),是指应特定用户要求或特定电子系统的需要而设计、制造的集成电路。严格意义上来讲,ASIC 是一种专用芯片,与传统的通用芯片有一定的差异。是为了某种特定的需求而专门定制的芯片。
ASIC 作为集成电路技术与特定用户的整机或系统技术紧密结合的产物,与通用集成电路相比,具有以下几个方面的优越性:体积更小、功耗更低、可靠性提高、性能提高、保密性增强、成本降低。回到深度学习最重要的指标:算力和功耗。我们对比 NVIDIA 的 GK210 和某 ASIC 芯片规划的指标,如下所示:
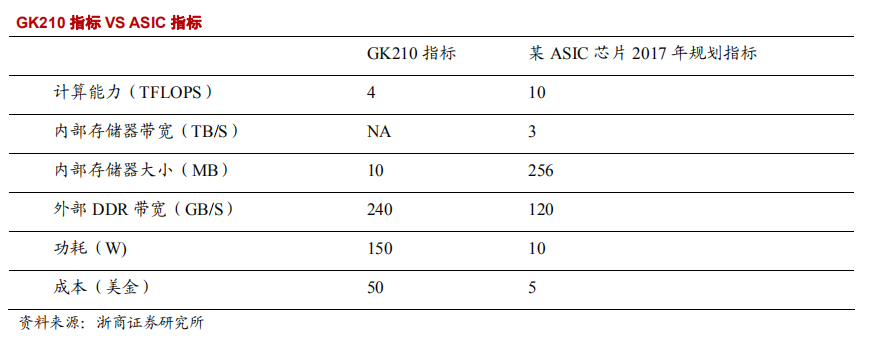
从算力上来说,ASIC 产品的计算能力是 GK210 的 2.5 倍。第二个指标是功耗, 功耗做到了 GK210 的 1/15。第三个指标是内部存储容量的大小及带宽。这个内部 MEMORY 相当于 CPU 上的 CACHE。深度雪地的模型比较大,通常能够到几百 MB 到 1GB 左右,会被频繁的读出来,如果模型放在片外的 DDR 里边,对 DDR 造成的带宽压力通常会到 TB/S 级别。
全定制设计的ASIC,因为其自身的特性,相较于非定制芯片,拥有以下几个优势:
同样工艺,同样功能,第一次采用全定制设计性能提高 7.6 倍
普通设计,全定制和非全定制的差别可能有 1~2 个数量级的差异
采用全定制方法可以超越非全定制 4 个工艺节点(采用 28nm 做的全定制设计,可能比 5nm 做的非全定制设计还要好)我们认为,ASIC 的优势,在人工智能深度学习领域,具有很大的潜力。
ASIC 在人工智能深度学习方面的应用还不多,但是我们可以拿比特币矿机芯片的发展做类似的推理。比特币挖矿和人工智能深度学习有类似之处,都是依赖于底层的芯片进行大规模的并行计算。而 ASIC 在比特币挖矿领域,展现出了得天独厚的优势。

比特币矿机的芯片经历了四个阶段:CPU、GPU、FPGA 和 ASIC。ASIC 芯片是专为挖矿量身定制的芯片,它将 FPGA 芯片中在挖矿时不会使用的功能去掉,与同等工艺的 FPGA 芯片相比执行速度块,大规模生产后的成本也要低于 FPGA 芯片。
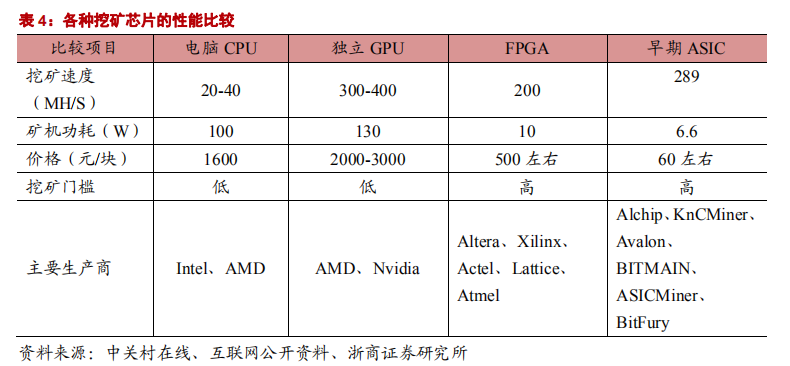
从 ASIC 在比特币挖矿机时代的发展历史,可以看出 ASIC 在专用并行计算领域所具有的得天独厚的优势:算力高,功耗低,价格低,专用性强。谷歌最近曝光的专用于人工智能深度学习计算的TPU、其实也是一款 ASIC。
综上,人工智能时代逐步临近,GPU、FPGA、ASIC这几块传统领域的芯片,将在人工智能时代迎来新的爆发。
2、信创产业研究框架
3、ARM行业研究框架
4、CPU研究框架
5、国产CPU研究框架
6、行业深度报告:GPU研究框架
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
