
四种计算文本相似度的方法对比
共 3391字,需浏览 7分钟
·
2022-02-09 17:36
编译:Bing
编者按:本文作者为Yves Peirsman,是NLP领域的专家。在这篇博文中,作者比较了各种计算句子相似度的方法,并了解它们是如何操作的。词嵌入(word embeddings)已经在自然语言处理领域广泛使用,它可以让我们轻易地计算两个词语之间的语义相似性,或者找出与目标词语最相似的词语。然而,人们关注更多的是两个句子或者短文之间的相似度。如果你对代码感兴趣,文中附有讲解细节的Jupyter Notebook地址。以下是论智的编译。
许多NLP应用需要计算两段短文之间的相似性。例如,搜索引擎需要建模,估计一份文本与提问问题之间的关联度,其中涉及到的并不只是看文字是否有重叠。与之相似的,类似Quora之类的问答网站也有这项需求,他们需要判断某一问题是否之前已出现过。要判断这类的文本相似性,首先要对两个短文本进行embedding,然后计算二者之间的余弦相似度(cosine similarity)。尽管word2vec和GloVe等词嵌入已经成为寻找单词间语义相似度的标准方法,但是对于句子嵌入应如何倍计算仍存在不同的声音。接下来,我们将回顾一下几种最常用的方法,并比较它们之间的性能。
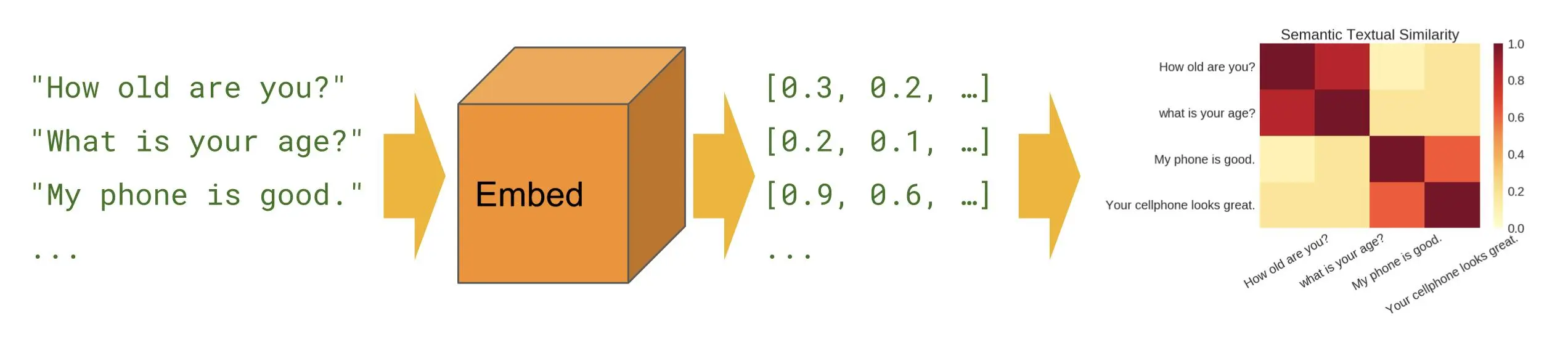
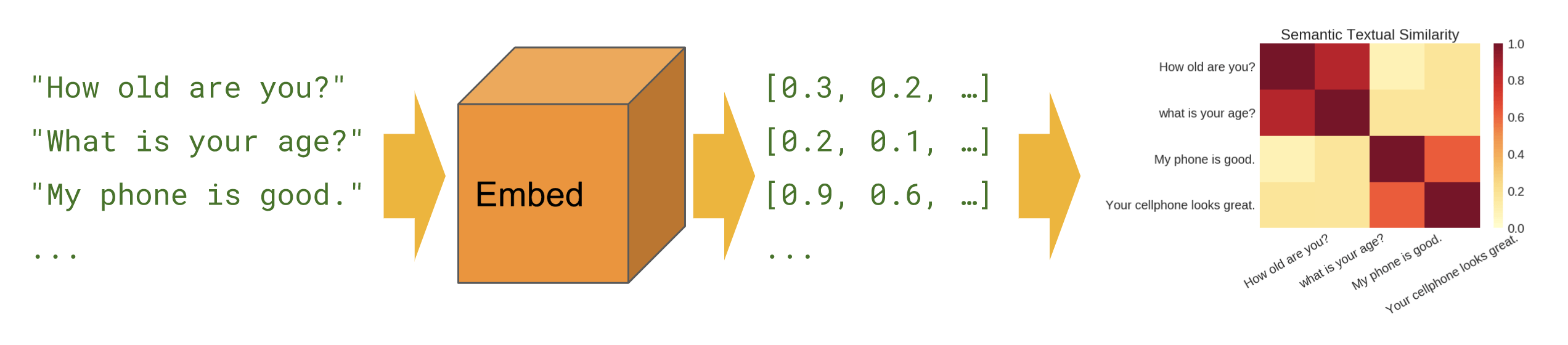
数据
我们将在两个被广泛使用的数据集上测试所有相似度计算方法,同时还与人类的判断作对比。两个数据集分别是:
- STS基准收集了2012年至2017年国际语义评测SemEval中所有的英语数据
- SICK数据库包含了10000对英语句子,其中的标签说明了它们之间的语义关联和逻辑关系
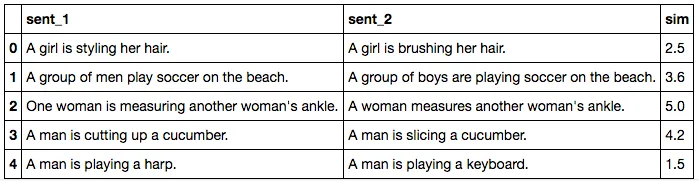
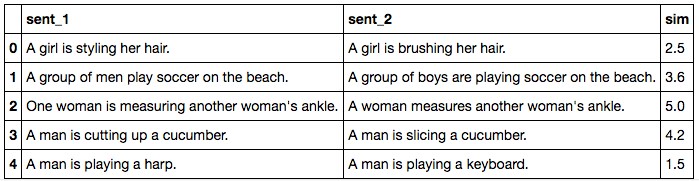
下面的表格是STS数据集中的几个例子。可以看到,两句话之间的语义关系通常非常微小。例如第四个例子:
A man is playing a harp.
A man is playing a keyboard.
通过判断,两句话之间“非常不相似”,尽管它们的句法结构相同,并且其中的词嵌入也类似。
相似度检测方法
用于计算两句子间语义相似度的方法非常广泛,下面是常见的几种方法。
基准方法
估计两句子间语义相似度最简单的方法就是求句子中所有单词词嵌入的平均值,然后计算两句子词嵌入之间的余弦相似性。很显然,这种简单的基准方法会带来很多变数。我们将研究,如果忽略终止词并用TF-IDF计算平均权重会带来怎样的影响。
词移距离
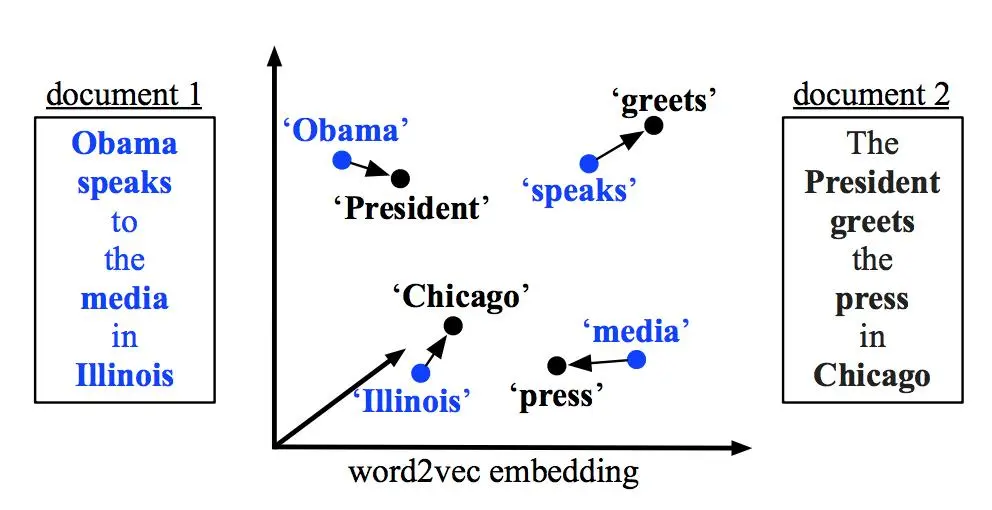
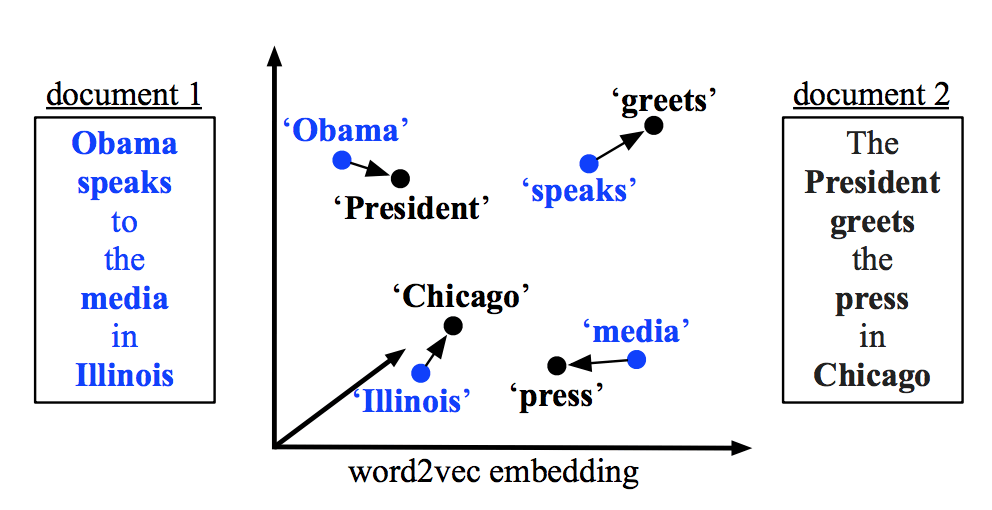
替代上述基准方法的其中一种有趣方法就是词移距离(Word Mover’s Distance)。词移距离使用两文本间的词嵌入,测量其中一文本中的单词在语义空间中移动到另一文本单词所需要的最短距离。
Smooth Inverse Frequency
从语义上来讲,求一句话中词嵌入的平均值似乎给与不相关的单词太多权重了。而Smooth Inverse Frequency试着用两种方法解决这一问题:
- 加权:就像上文用的TF-IDF,SIF取句中词嵌入的平均权重。每个词嵌入都由a/(a + p(w))进行加权,其中a的值经常被设置为0.01,而p(w)是词语在语料中预计出现的频率。
- 常见元素删除:接下来,SIF计算了句子的嵌入中最重要的元素。然后它减去这些句子嵌入中的主要成分。这就可以删除与频率和句法有关的变量,他们和语义的联系不大。
最后,SIF使一些不重要的词语的权重下降,例如but、just等,同时保留对语义贡献较大的信息。
预训练编码器
上述两种方法都有两个重要的特征。首先,作为简单的词袋方法,它们并不考虑单词的顺序。其次,它们使用的词嵌入是在一种无监督方法中学习到的。这两种特点都有潜在的威胁。由于不同的词语顺序会有不同的意思(例如“the dog bites the man”和“the man bites the dog”),我们想让句子的嵌入对这一变化有所反馈。另外,监督训练可以更直接地帮助句子嵌入学习到句意。
于是就出现了预训练编码器。预训练的句子编码器的目的是充当word2vec和GloVe的作用,但是对于句子嵌入来说:它们生成的嵌入可以用在多种应用中,例如文本分类、近似文本检测等等。一般来说,编码器在许多监督和非监督的任务中训练,目的就是能尽量多地获取通用语义信息。目前已经有好几款这样的编码器了,我们以InferSent和谷歌语句编码器为例。
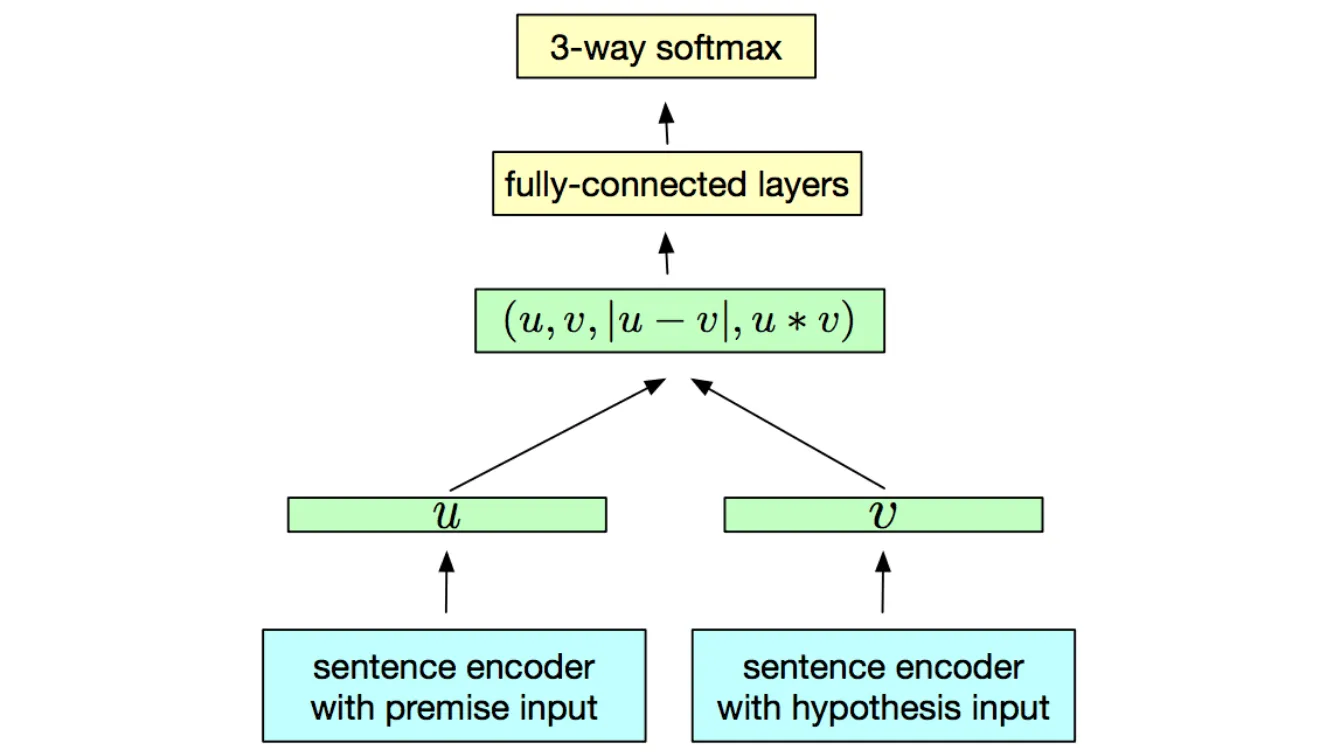
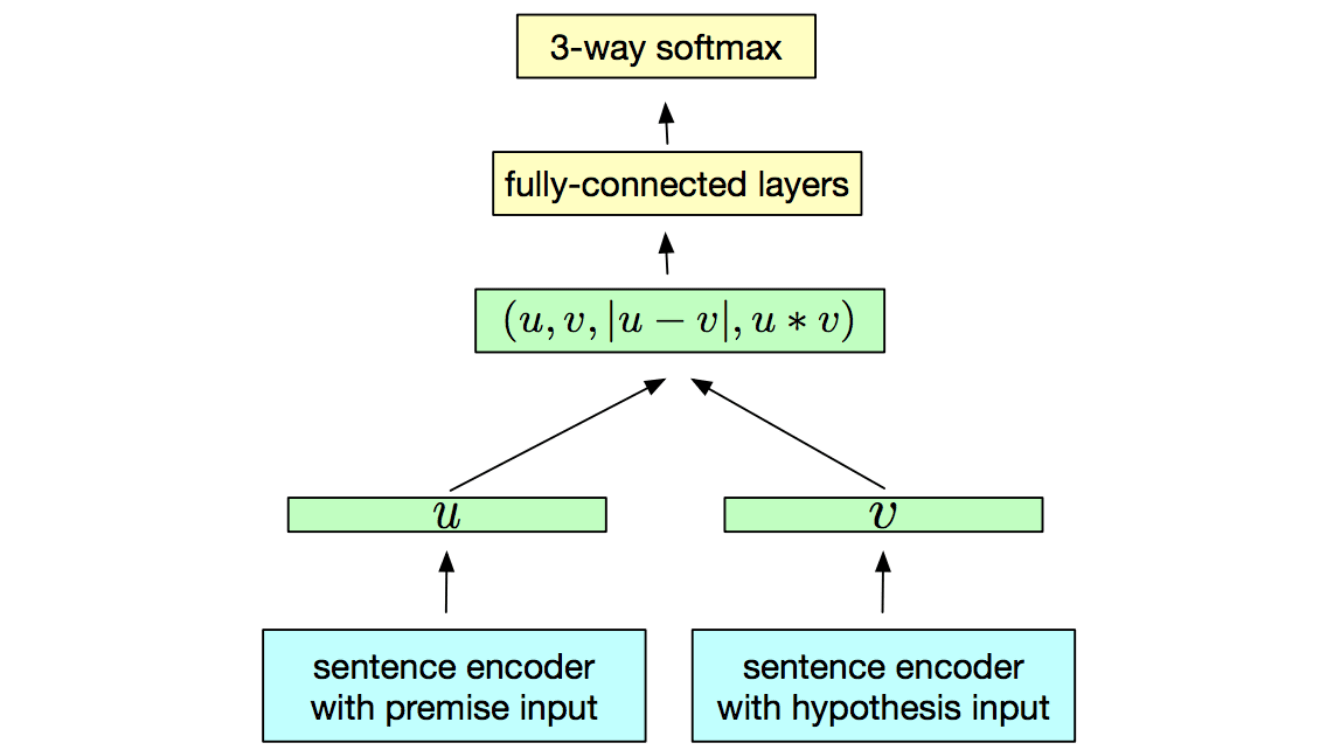
InferSent是由Facebook研发的预训练编码器,它是一个拥有最大池化的BiLSTM,在SNLI数据集上训练,该数据集含有57万英语句子对,所有句子都属于三个类别的其中一种:推导关系、矛盾关系、中立关系。
为了与Facebook竞争,谷歌也推出了自己的语句编码器,它有两种形式:
- 其中一种高级模型,采用的是变换过的模型编码子图生成的语境感知词所表示的元素总和。
- 另一种是简单一些的深度平均网络(DAN),其中输入的单词和双字符的嵌入相加求平均数,并经过一个前馈深层神经网络。
基于变换的模型的结果更好,但是在书写的时候,只有基于DAN的编码器可用。与InferSent不同,谷歌的橘子编码器是在监督数据和非监督数据上共同训练的。
结果
我们在SICK和STS数据集上测试了上述所有方法,得出句子对之间的相似度,并与人类判断相比较。
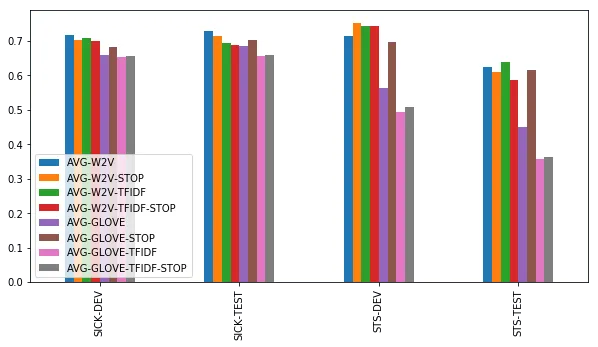
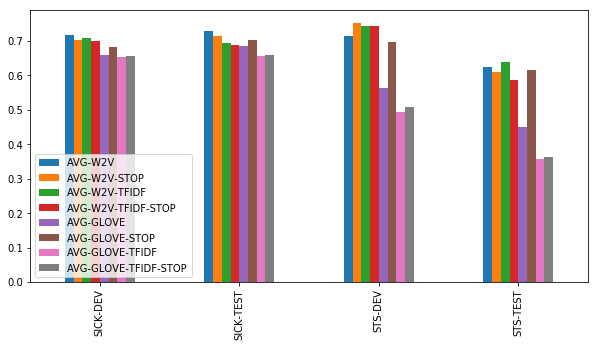
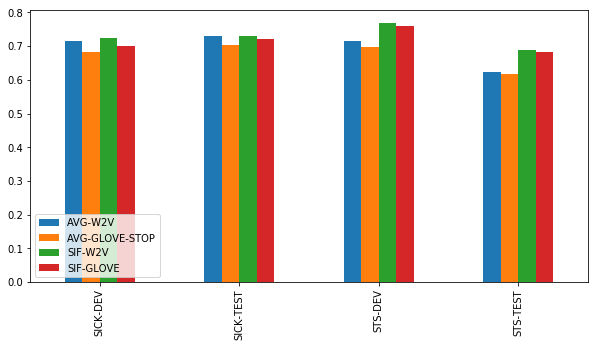
基准方法
尽管他们很简洁,在平均词嵌入之间求余弦相似性的基准方法表现得非常好。但是,前提仍要满足一些条件:
- 简单word2vec嵌入比GloVe嵌入表现的好
- 在用word2vec时,尚不清楚使用停用词表或TF-IDF加权是否更有帮助。在STS上,有时有用;在SICK上没用。仅计算未加权的所有word2vec嵌入平均值表现得很好。
- 在使用GloVe时,停用词列表对于达到好的效果非常重要。利用TF-IDF加权没有帮助。
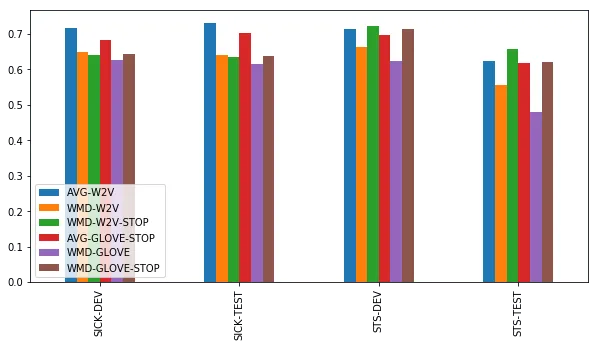
词移距离
基于我们的结果,好像没有什么使用词移距离的必要了,因为上述方法表现得已经很好了。只有在STS-TEST上,而且只有在有停止词列表的情况下,词移距离才能和简单基准方法一较高下。
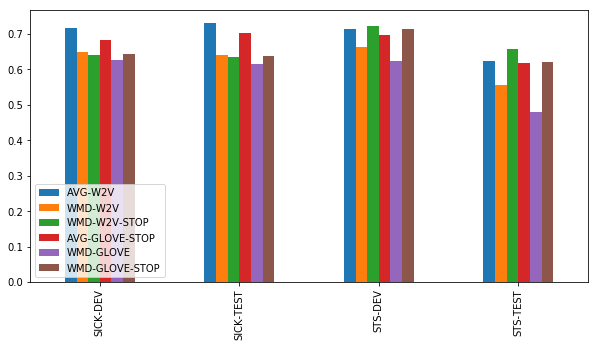
Smooth Inverse Frequency
SIF是在测试中表现最稳定的方法。在SICK数据集上,它的表现和简单基准方法差不多,但是在STS数据集上明显超过了它们。注意,在带有word2vec词嵌入的SIF和带有GloVe词嵌入的SIF之间有一些差别,这种差别很显著,它显示了SIF的加权和去除常用元素后减少的非信息噪音。

预训练编码器
预训练编码器的情况比较复杂。但是我们的结果显示编码器还不能完全利用训练的成果。谷歌的句子编码器看起来要比InferSent好一些,但是皮尔森相关系数的结果与SIF的差别不大。
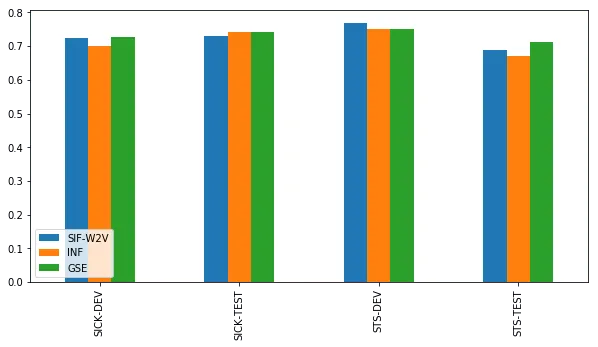
而斯皮尔曼相关系数的效果更直接。这也许表明,谷歌的句子编码器更能了解到句子的正确顺序,但是无法分辨其中的差别。
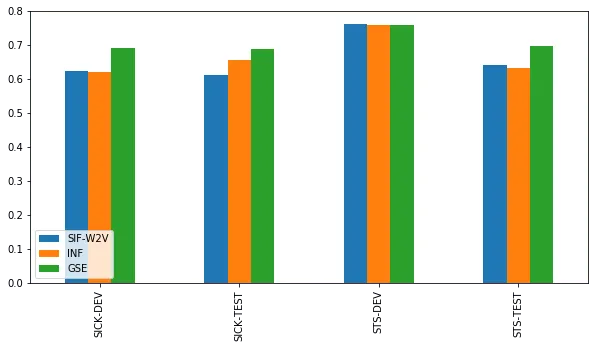
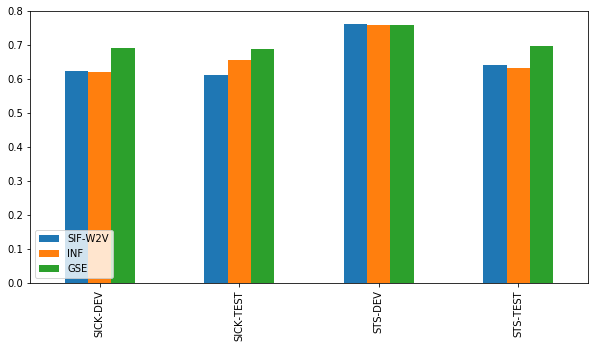
结论
语句相似度是一个复杂现象,一句话的含义并不仅仅取决于当中的词语,而且还依赖于它们的组合方式。正如开头我们举的那个例子(harp和keyboard),语义相似度有好几种维度,句子可能在其中一种维度上相似,而在其他维度上有差异。目前的句子嵌入方法也只做到了表面。通常我们在皮尔森相关系数(Pearson correlation)上进行测试,除了有些情况下斯皮尔曼相关系数(Spearman correlation)会有不一样的结果。
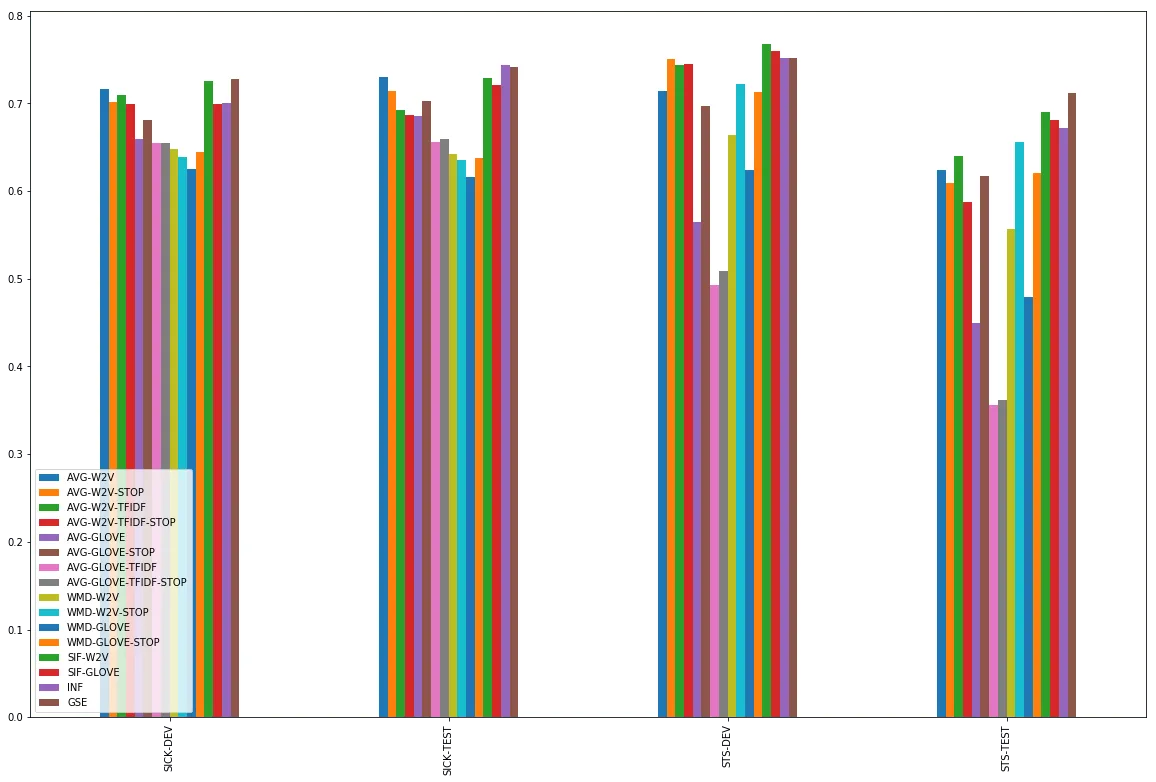
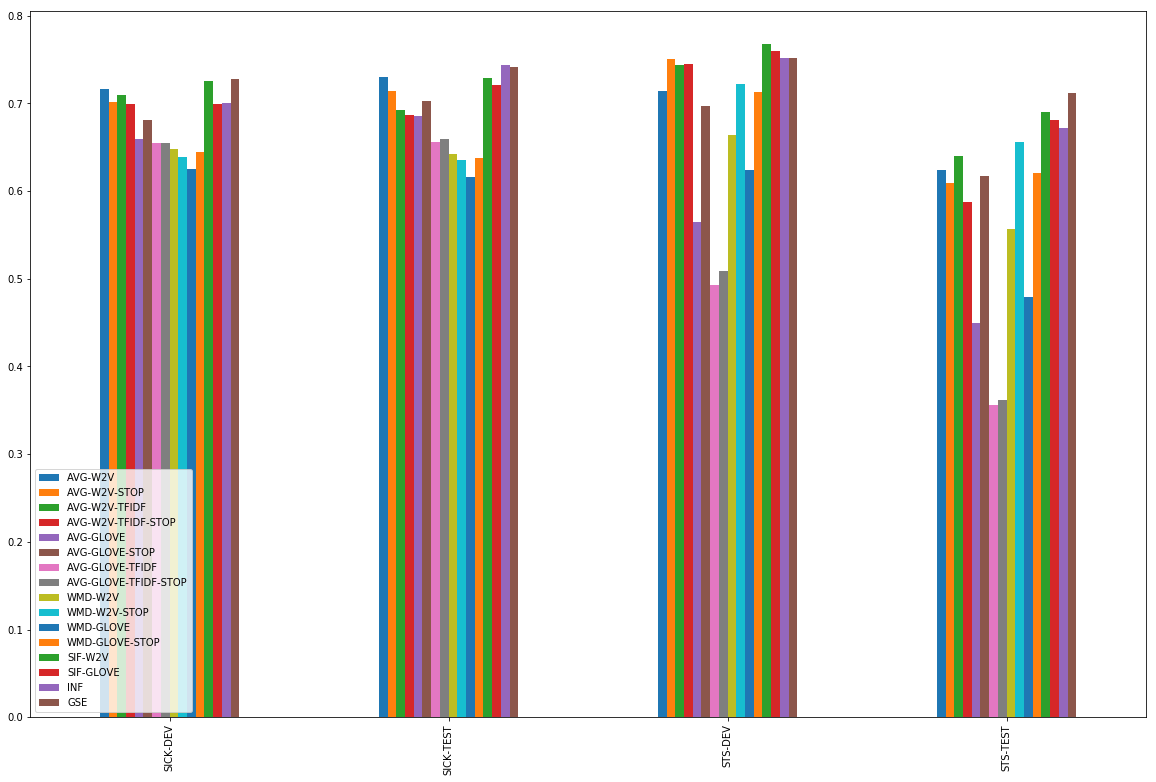
所以,如果你想计算句子相似度,你会选择哪种方法呢?我们的建议如下:
- word2vec比GloVe的选择更保险
- 虽然句子中无加权的平均词嵌入是简单的基准做法,但是Smooth Inverse Frequency是更强有力的选择
- 如果你可以用预训练编码器,选择谷歌的那款吧。但是要记住它的表现可能不会总是那么惊艳。
原文地址:nlp.town/blog/sentence-similarity/
GitHub地址:github.com/nlptown/sentence-similarity/blob/master/Simple%20Sentence%20Similarity.ipynb