
上市公司地址相似度计算&构建关系图谱
AI入门学习
共 12898字,需浏览 26分钟
·
2022-04-30 18:14
作 者: 凌岸 来源1: https://zhuanlan.zhihu.com/p/111203086来源2: https://zhuanlan.zhihu.com/p/459309174文末点击阅读原文跳转知乎,阅读作者更多精彩文章
今天和各位小伙伴分析一个在搭建知识图谱的时候遇到的一个麻烦的问题。在构建知识图谱的图关系,基础的原始数据来自很多不同的数据源。比如在金融风控领域,我们要构建的知识图谱中,包含地址、公司等出现频率比较高,并且名称一模一样的可能性很低的词汇。比如下面两个是同一个地址么?
本文目录如下:一、地址数据预处理二、数据地址标准化处理三、相似度计算四、构造节点表和关系表五、导入节点表和关系表构建图谱
对数据做一个预览,所幸我们本次下载的公开数据质量很高,地址中并未出现一些质量差的数据,省去了多余的要做的一些处理。
二、地址数据标准化处理
地址中有很多存在不标准的情况存在,所以使用capa的包进行标准化处理。写到这里,提一句,本身我是想自己去开发这个一个功能,但是发现了有开源工具,全称为:chinese_province_city_area_mapper。他也提供了全文模式和分词模式两种。那他的功能也很强大,可以将地址数据补全: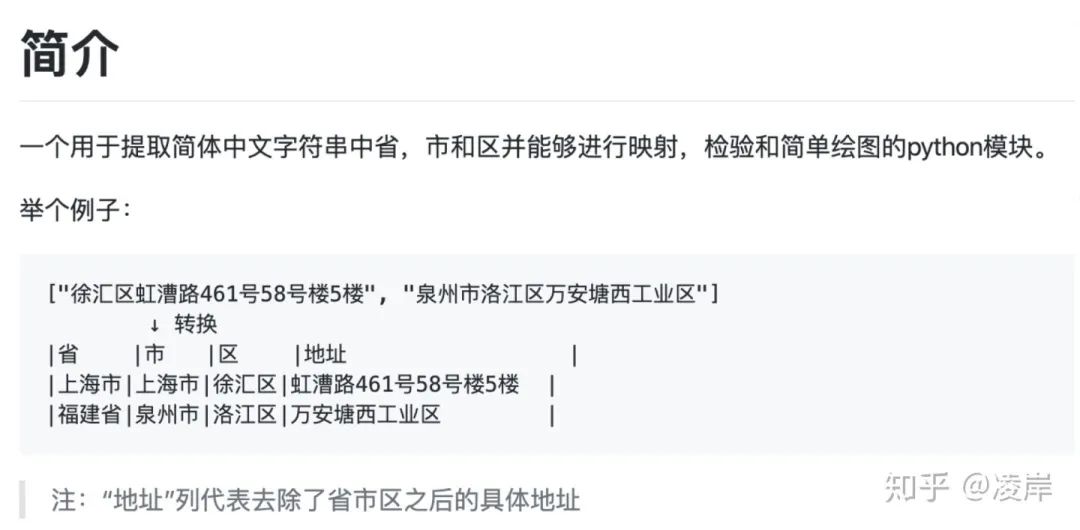 我也附出这个cpca包的github链接:
我也附出这个cpca包的github链接:
处理结束的样例如下: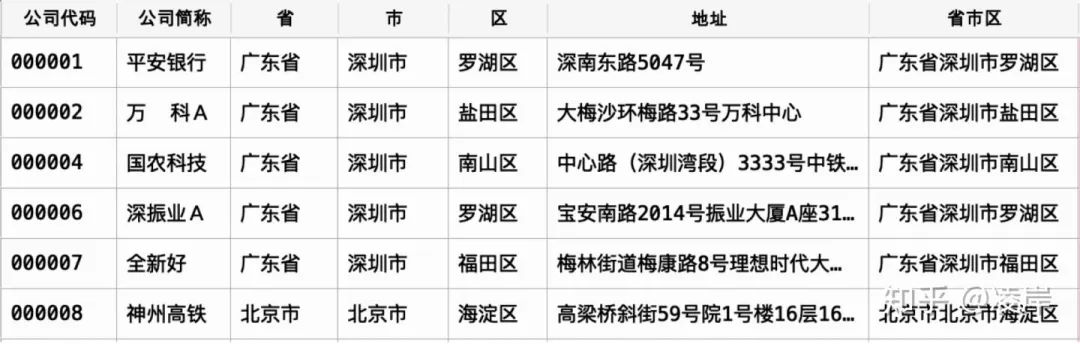
第2个地址与n-2个地址比较
第3个地址与n-3个地址比较
第n-1个地址与n个地址比较
第n个不执行
第三层函数计算目标文档与被比较文档之间的地址相似度,其中按照上面的函数举例即为,目标文档为第一个地址,被比较文档为,n-1个所有的地址,这里我们是有使用TF-DF模型对料库建模,如此即将同一个省市区下面的地址循环完成。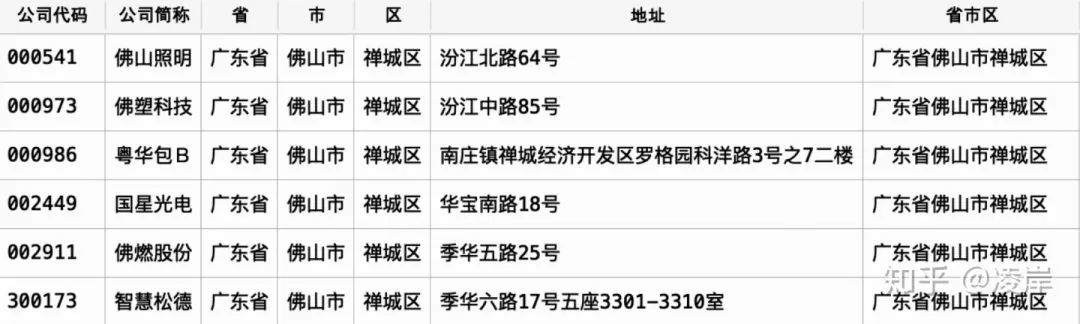 在算法里面,我们将第一个地址即为,佛山照明的地址”汾江北路64号“同时与剩下的5个地址进行比较相似度,
在算法里面,我们将第一个地址即为,佛山照明的地址”汾江北路64号“同时与剩下的5个地址进行比较相似度,
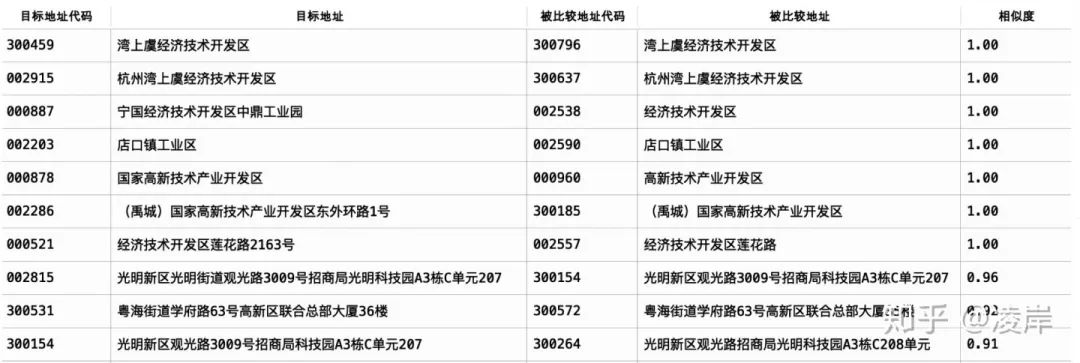 每一行都在同一个省市区下面,那么最后的地址判断,我们看到还是准确的,基本上都识别出来了,特别是相似度为0.9的那个几组。
每一行都在同一个省市区下面,那么最后的地址判断,我们看到还是准确的,基本上都识别出来了,特别是相似度为0.9的那个几组。
 添加图片注释,不超过 140 字(可选)为了要将结果数据导入到neo4j中,我们要加工好节点表和关系,我们顺势采用这个结果。
添加图片注释,不超过 140 字(可选)为了要将结果数据导入到neo4j中,我们要加工好节点表和关系,我们顺势采用这个结果。

今天和各位小伙伴分析一个在搭建知识图谱的时候遇到的一个麻烦的问题。在构建知识图谱的图关系,基础的原始数据来自很多不同的数据源。比如在金融风控领域,我们要构建的知识图谱中,包含地址、公司等出现频率比较高,并且名称一模一样的可能性很低的词汇。比如下面两个是同一个地址么?
深圳市京基100大厦写字楼深圳市罗湖区深南东路5016号京基100大厦那在图关系的构建中,如果把上地址作为两个地址进行处理的话,那么就会创建两个实体,并且这两个实体之间并没有什么关联关系,这种处理方法,肯定是有问题的。此时,我们衍生出了两个问题:1、第一,对于以上的问题做地址消歧,把两个地址经过处理后,变成同一个地址。2、或者说,我们做一个两个实体之间的地址相似度,如在图谱中表现为 A节点与B节点的相似度为0.9以上。这个时候我们需要做的是进行相似度计算。我们在深圳证券交易所找到了公开的数据集。发现深交所数据已经失效了,给出百度链接在这里。链接: https://pan.baidu.com/wap/init?surl=qAOb17tGPg_HDKsaZ8w5xw 密码: 7ojt
本文目录如下:一、地址数据预处理二、数据地址标准化处理三、相似度计算四、构造节点表和关系表五、导入节点表和关系表构建图谱
一、地址数据预处理
我们先导入一些后续用的上的python包,如下:下面,我们导入public_company这个数据集,可以预览一下,该部分数据有哪些字段。import numpy as npimport pandas as pdfrom csv import readerimport timeimport cpcaimport jiebafrom gensim import corpora, models, similarities
我们选取公司代码、公司简称、公司地址三个字段,并将字段中地址进行去空处理。df.columnsIndex(['公司代码', '公司简称', '公司全称', '英文名称', '注册地址', 'A股代码', 'A股简称', 'A股上市日期','A股总股本', 'A股流通股本', '地 区', '省 份', '城 市', '所属行业', '公司网址'],dtype='object')
对数据做一个预览,所幸我们本次下载的公开数据质量很高,地址中并未出现一些质量差的数据,省去了多余的要做的一些处理。
def read_data():#导入数据,并对数据做一些处理df = pd.read_excel("../public_company.xlsx", dtype={'公司代码': 'str'})addr_df = df[["公司代码", "公司简称", "注册地址"]]addr_df["注册地址"]= addr_df["注册地址"].apply(lambda x: str(x).strip())return addr_df
二、地址数据标准化处理
地址中有很多存在不标准的情况存在,所以使用capa的包进行标准化处理。写到这里,提一句,本身我是想自己去开发这个一个功能,但是发现了有开源工具,全称为:chinese_province_city_area_mapper。他也提供了全文模式和分词模式两种。那他的功能也很强大,可以将地址数据补全:我也附出这个cpca包的github链接:处理结束的样例如下:
def get_dataset(addr_df):'''#对地址做一个标准化处理,其中导入cpca的包进行处理'''start = time.clock()location_str = []for i in addr_df['注册地址']:location_str.append(i.strip())addr_cp = cpca.transform(location_str,cut=False,open_warning=False)#给结果表拼接唯一识别代码e_data = addr_df[["公司代码", "公司简称"]]addr_cpca = pd.concat([e_data, addr_cp], axis=1)#1.区不为空addr_cpca_1 = addr_cpca[(addr_cpca['省']!= '')&(addr_cpca['市']!= '') & (addr_cpca['区']!= '')]addr_cpca_1= addr_cpca_1.dropna()addr_cpca_11= addr_cpca_1[(addr_cpca['地址']!='')]addr_cpca_12= addr_cpca_11. dropna(subset=['地址'])#将前三个字段完全拼接在一起进行分组然后组内进行相似度分析addr_cpca_12['省市区'] = addr_cpca_12['省'] + addr_cpca_12['市'] + addr_cpca_12['区']addr_cpca_12['省市区长度']=addr_cpca_12['省市区'].apply(lambda x: len(x))count_1 = addr_cpca_12['省市区'].value_counts().reset_index()count_1= count_1.rename(columns={'index':'省市区', '省市区':'个数'})count_delete_1= count_1[count_1['个数']==1]dataset_1 = pd.merge(addr_cpca_12, count_delete_1, on = '省市区', how = 'left')dataset_1= dataset_1[dataset_1['个数']!=1]#2.区为空addr_cpca_2 = addr_cpca[(addr_cpca['省']!= '')&(addr_cpca['市']!= '') & (addr_cpca['区']== '')]addr_cpca_2 = addr_cpca_2.dropna()addr_cpca_21= addr_cpca_2[(addr_cpca['地址']!='')]addr_cpca_22= addr_cpca_21. dropna(subset=['地址'])#将前三个字段完全拼接在一起进行分组然后组内进行相似度分析addr_cpca_22['省市区'] = addr_cpca_22['省'] + addr_cpca_22['市']addr_cpca_22['省市区长度']=addr_cpca_22['省市区'].apply(lambda x: len(x))count_2 = addr_cpca_22['省市区'].value_counts().reset_index()count_2= count_2.rename(columns={'index':'省市区', '省市区':'个数'})count_delete_2 = count_2[count_2['个数']==1]dataset_2 = pd.merge(addr_cpca_22, count_delete_2, on = '省市区', how = 'left')dataset_2 = dataset_2[dataset_2['个数']!=1]print("Time used:", (time. clock()-start), "s")return dataset_1, dataset_2
三、相似度计算
在开始计算相似度时候,较为复杂,就是要比较表里面所有数据之间的相似度,那就是两两之间都要比较,如果有N表数据,就要比较(N-1)! 次。但是我们只是不同省份或者不同城市不同区之间的地址其实是不会相似的,我们接着上面的思路,按照区与区地址的地址进行循环比较即可。我们套用两层循环函数即可,第一层循环,函数为get_collect(),我们获取字段省市区,的单个省市区的文档,然后再调用调用第二层循环函数,函数为cycle_first(),第二层循环函数的思想是:第1个地址与n-1个地址比较第2个地址与n-2个地址比较
第3个地址与n-3个地址比较
第n-1个地址与n个地址比较
第n个不执行
第三层函数计算目标文档与被比较文档之间的地址相似度,其中按照上面的函数举例即为,目标文档为第一个地址,被比较文档为,n-1个所有的地址,这里我们是有使用TF-DF模型对料库建模,如此即将同一个省市区下面的地址循环完成。
在算法里面,我们将第一个地址即为,佛山照明的地址”汾江北路64号“同时与剩下的5个地址进行比较相似度,def cal_similar(doc_goal, document, ssim = 0.1):#def cal_similar(doc_goai, document):'''分词;计算文本相似度doc_goal,短文本,目标文档document,多个文本,被比较的多个文档'''all_doc_list=[]for doc in document:doc= "".join(doc)doc_list=[word for word in jieba.cut(doc)]all_doc_list.append(doc_list)#目标文档doc_goal = "".join(doc_goal)doc_goal_list = [word for word in jieba.cut(doc_goal)]#被比较的多个文档dictionary = corpora.Dictionary(all_doc_list) #先用dictionary方法获词袋corpus = [dictionary.doc2bow(doc) for doc in all_doc_list] #使用doc2bow制作预料库#目标文档doc_goal_vec = dictionary.doc2bow(doc_goal_list)tfidf = models.TfidfModel(corpus)#使用TF-DF模型对料库建模index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features = len(dictionary.keys()))#对每个目标文档,分析测文档的相似度#开始比较sims = index[tfidf[doc_goal_vec]]#similary= sorted(enumerate(sims),key=lambda item: -item[1])#根据相似度排序addr_dict={"被比较地址": document, "相似度": list(sims)}similary = pd.DataFrame(addr_dict)similary["目标地址"] = doc_goalsimilary_data = similary[["目标地址", "被比较地址", "相似度"]]similary_data= similary_data[similary_data["相似度"]>=ssim]return similary_datadef cycle_first(single_data):single_value = single_data.loc[:,["公司代码","地址"]].values #提取地址cycle_data = pd. DataFrame([])for key, value in enumerate(single_value):if key < len(single_data)-1:doc_goal=list(value)[1:]document=list(single_data["地址"])[key+1:]cycle = cal_similar(doc_goal, document, ssim=0)cycle['目标地址代码'] = list(single_data["公司代码"])[key]cycle['被比较地址代码'] = list(single_data["公司代码"])[key+1:]cycle = cycle[["目标地址代码","目标地址", "被比较地址代码", "被比较地址", "相似度"]]#print("循环第",key,"个地址,得到表的行数,",len(cycle),",当前子循环计算进度,",key/len(cycle))cycle_data = cycle_data.append(cycle)cycle_data = cycle_data.drop_duplicates()return cycle_datadef get_collect(dataset):start = time. clock()#获取单个省市区的文档collect_data = pd.DataFrame([])ssq=list(set(dataset['省市区']))for v, word in enumerate(ssq):single_data = dataset[dataset['省市区'] == word]print("循环第",v,"个省市区地址为:",word,",当前此区地址有:",len(single_data),",当前计算进度为:{:.1f}%" .format(v*100/len(ssq)))cycle_data = cycle_first(single_data)collect_data = collect_data.append(cycle_data)#将每个市区得到的结果放入一张表print("Time: %s" %time.ctime())print("-----------------------------------------------------------------------")print("Time used:",(time.clock() - start), "s")return collect_data
我们最终只需要调用总函数,就可以运行上述代码,def run_(par = 0):#调用上述函数addr_df = read_data()dataset_1, dataset_2 = get_dataset(addr_df)#dataset. to_csv("../data/addr_data/document_address.csv", index =False)#dataset. to_csv( ". /data/addr_data/document_address. csv", index False)collect_data_1 = get_collect(dataset_1)collect_data_2 = get_collect(dataset_2)collect_data = pd.concat([collect_data_1, collect_data_2], axis=0)collect_data = collect_data[collect_data["相似度"]>=par].sort_values(by=["相似度"], ascending=[False])collect_data["相似度"] = collect_data["相似度"].apply(lambda x: ('%.2f' % x))return collect_data
可以看到,其实整个代码运行的速度很快,2000多条地址,5秒就通过我们自己组合起来的算法计算完成。我们可以打印一下前5行结果,看一下相似度计算的结果,肉眼观察一下结果如何:In [23]: collect_data = run_(par = 0.1)Time used: 0.2949850000000005 s0 个省市区地址为: 山东省青岛市崂山区 ,当前此区地址有: 5 ,当前计算进度为:0.0%Loading model cost 0.633 seconds.Prefix dict has been built succesfully.Time: Thu Mar 5 21:52:31 2020-----------------------------------------------------------------------1 个省市区地址为: 广东省珠海市金湾区 ,当前此区地址有: 4 ,当前计算进度为:0.5%Time: Thu Mar 5 21:52:31 2020...97 个省市区地址为: 四川省自贡市 ,当前此区地址有: 2 ,当前计算进度为:98.0%Time: Wed Mar 4 16:19:32 2020-----------------------------------------------------------------------98 个省市区地址为: 山东省聊城市 ,当前此区地址有: 2 ,当前计算进度为:99.0%Time: Wed Mar 4 16:19:32 2020-----------------------------------------------------------------------Time used: 5.461850999999999 s
每一行都在同一个省市区下面,那么最后的地址判断,我们看到还是准确的,基本上都识别出来了,特别是相似度为0.9的那个几组。四、构造节点表和关系表
构造节点表和关系表、以及使用neo4j-admin工具导入数据,我们可以看下官网要求的数据格式,以及导入语句的要求:官网网址如下:https://neo4j.com/docs/operations-manual/4.0/tutorial/import-tool/添加图片注释,不超过 140 字(可选)为了要将结果数据导入到neo4j中,我们要加工好节点表和关系,我们顺势采用这个结果。接下来,我们需要在电脑上装neo4j,假设你已经部署了neo4j。我们先看ne4j是否已经在开启状态,#建表:一张节点表,一张关系表df = pd.read_excel("../public_company.xlsx", dtype={'公司代码': 'str'})df_node = df[['公司代码', '公司简称', '公司全称', '注册地址', '所属行业']]df_node = df_node.rename(columns = {"公司代码": ":ID"})df_node.to_csv("/../node.csv", index =False)df_rela = collect_data[collect_data["相似度"]>= 0.6]df_rela = df_rela[["目标地址代码", "被比较地址代码", "相似度"]]df_relation = df_rela.rename(columns = {"目标地址代码": ":START_ID", "被比较地址代码": ":END_ID", "相似度":":TYPE"})df_relation.to_csv("../relationship.csv", index = False)
发现已经正在运行了,先停止掉,neo4j社区版,只有再关掉图数据库的时候,才能导入数据bogon:bin mbp$ ./neo4j statusNeo4j is running at pid 11074
停掉图数据库以后,我们还要进去database,删掉之前存在graph.db,才能导入数据,否则,导入会报错。bogon:bin mbp$ ./neo4j stopStopping Neo4j.. stopped
bogon:bin mbp$ cd /Users/mbp/neo4j-community-3.5.4/data/databasesbogon:databases mbp$ rm -rf graph.dbbogon:databases mbp$ cd /Users/mbp/neo4j-community-3.5.4/binbogon:bin mbp$ ./neo4j-admin import --mode=csv --database=graph.db --nodes:公司 "/Users/mbp/neo4j-community-3.5.4/import/node.csv" --relationships:地址相似 "/Users/mbp/neo4j-community-3.5.4/import/relationship.csv" --ignore-duplicate-nodes=true --ignore-missing-nodes=trueNeo4j version: 3.5.4Importing the contents of these files into /Users/mbp/neo4j-community-3.5.4/data/databases/graph.db:Nodes::公司/Users/mbp/neo4j-community-3.5.4/import/node.csvRelationships::地址相似/Users/mbp/neo4j-community-3.5.4/import/relationship.csvAvailable resources:Total machine memory: 8.00 GBFree machine memory: 54.28 MBMax heap memory : 1.78 GBProcessors: 4Configured max memory: 5.60 GBHigh-IO: true...(1/4) Node import 2020-03-03 12:43:15.718+0800Estimated number of nodes: 5.30 kEstimated disk space usage: 1.78 MBEstimated required memory usage: 1020.07 MB-......... .......... .......... .......... .......... 5% ∆62ms.......... .......... .......... .......... .......... 10% ∆0ms............. .......... .......... .......... .......... 95% ∆0ms.......... .......... .......... .......... .......... 100% ∆1ms(2/4) Relationship import 2020-03-03 12:43:16.205+0800Estimated number of relationships: 216.00Estimated disk space usage: 7.17 kBEstimated required memory usage: 1.00 GB.......... .......... .......... .......... .......... 5% ∆45ms.......... .......... .......... .......... .......... 10% ∆0ms............. .......... .......... .......... .......... 95% ∆0ms.......... .......... .......... .......... .......... 100% ∆0ms(3/4) Relationship linking 2020-03-03 12:43:16.257+0800Estimated required memory usage: 1020.03 MB-......... .......... .......... .......... .......... 5% ∆34ms............. .......... .......... .......... .......... 90% ∆0ms.......... .......... .......... .......... .......... 95% ∆0ms.......... .......... .......... .......... .........(4/4) Post processing 2020-03-03 12:43:16.398+0800Estimated required memory usage: 1020.01 MB-......... .......... .......... .......... .......... 5% ∆55ms.......... .......... .......... .......... .......... 10% ∆0ms............. .......... .......... .......... .......... 100% ∆0msIMPORT DONE in 1s 261ms.Imported:2214 nodes216 relationships8856 propertiesPeak memory usage: 1.00 GBbogon:bin mbp$
然后再次开启neo4j图数据库,
bogon:bin mbp$ ./neo4j startActive database: graph.dbDirectories in use:home: /Users/mbp/neo4j-community-3.5.4config: /Users/mbp/neo4j-community-3.5.4/conflogs: /Users/mbp/neo4j-community-3.5.4/logsplugins: /Users/mbp/neo4j-community-3.5.4/pluginsimport: /Users/mbp/neo4j-community-3.5.4/importdata: /Users/mbp/neo4j-community-3.5.4/datacertificates: /Users/mbp/neo4j-community-3.5.4/certificatesrun: /Users/mbp/neo4j-community-3.5.4/runStarting Neo4j.Started neo4j (pid 11074). It is available at http://localhost:7474/There may be a short delay until the server is ready.See /Users/mbp/neo4j-community-3.5.4/logs/neo4j.log for current status.
我们打开浏览器,输入网址 localhost:7474/browser/
我们看到节点和关系以及属性都成功导入了,标签也导入了。
一共有2214个节点,219个关系,其中节点的属性为 公司全称、公司简称、所属行业、注册地址。
实际上关系做成这样,我们是不建议这样做的,因为目前我们的数字种类不多,neo4j不会报错,实际上他的官网有要求,关系总的种类大于6万多条导入时候会报错。
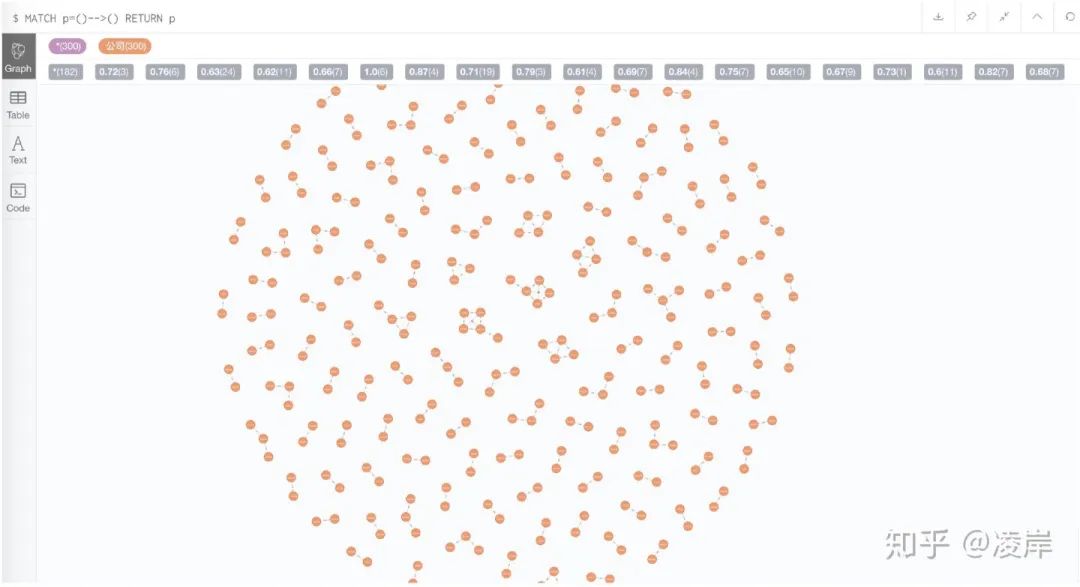
我们在网页端输入cypher语句,看一下节点与节点之间的效果:
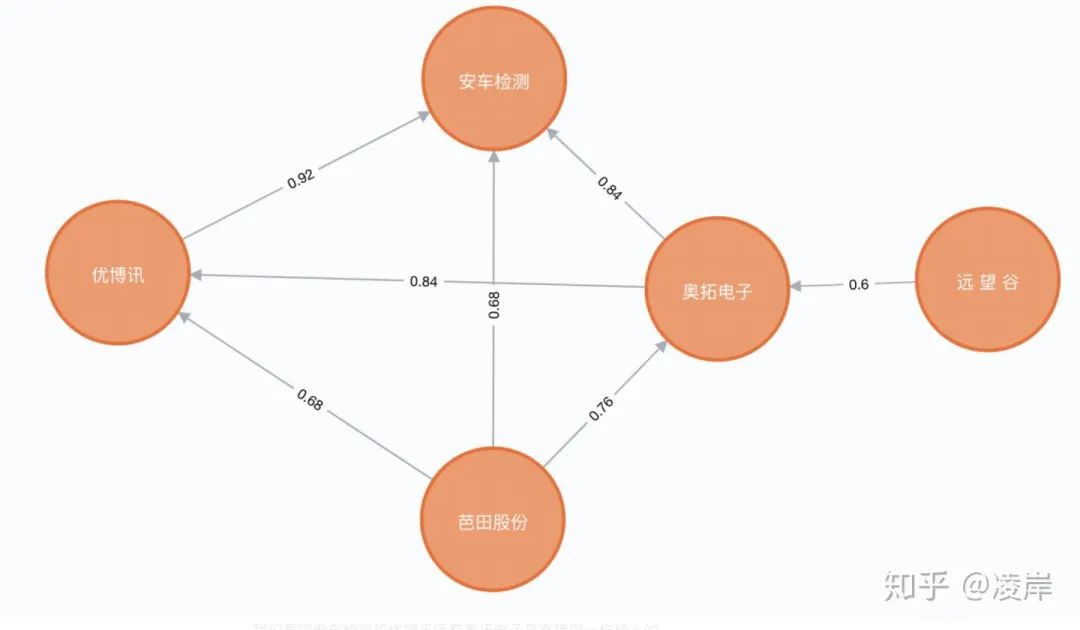
MATCH p=()-->() RETURN p我们选取其中一个小强连通闭环图看一下:
我们看到安车检测和优博讯还有奥拓电子是直接同一栋楼上的。
虽然安车检测与芭田股份以及远望谷所填写的地址貌似看起来不在一起,但是发现他们全部都是在 联合总部大厦的。
题外话,如果这些节点是 申请小额贷款的客户,他们地址高度相似,集中在同一个小区,在关系图谱上面,他们被通过地址相似的方式计算出来,有一个强连通图,那么是否他们有团伙欺诈的嫌疑?我认为这是一个很好的应用场景。
··· END ···
评论