
一道搜狗面试题:IO多路复用中select、poll、epoll之间的区别
共 5480字,需浏览 11分钟
·
2020-08-07 21:16
链接:cnblogs.com/aspirant/p/9166944.html
正文
(1)select==>时间复杂度O(n)
它仅仅知道了,有I/O事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以select具有O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
(2)poll==>时间复杂度O(n)
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的.
(3)epoll==>时间复杂度O(1)
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll会把哪个流发生了怎样的I/O事件通知我们。所以我们说epoll实际上是事件驱动(每个事件关联上fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了O(1))
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
epoll跟select都能提供多路I/O复用的解决方案。在现在的Linux内核里有都能够支持,其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
select:
select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是:
1、 单个进程可监视的fd数量被限制,即能监听端口的大小有限。
一般来说这个数目和系统内存关系很大,具体数目可以cat /proc/sys/fs/file-max察看。32位机默认是1024个。64位机默认是2048.
2、 对socket进行扫描时是线性扫描,即采用轮询的方法,效率较低:
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll与kqueue做的。
3、需要维护一个用来存放大量fd的数据结构,这样会使得用户空间和内核空间在传递该结构时复制开销大
poll:
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态,如果设备就绪则在设备等待队列中加入一项并继续遍历,如果遍历完所有fd后没有发现就绪设备,则挂起当前进程,直到设备就绪或者主动超时,被唤醒后它又要再次遍历fd。这个过程经历了多次无谓的遍历。
它没有最大连接数的限制,原因是它是基于链表来存储的,但是同样有一个缺点:
大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。
poll还有一个特点是“水平触发”,如果报告了fd后,没有被处理,那么下次poll时会再次报告该fd。
epoll:
epoll有EPOLLLT和EPOLLET两种触发模式,LT是默认的模式,ET是“高速”模式。LT模式下,只要这个fd还有数据可读,每次 epoll_wait都会返回它的事件,提醒用户程序去操作,而在ET(边缘触发)模式中,它只会提示一次,直到下次再有数据流入之前都不会再提示了,无 论fd中是否还有数据可读。
所以在ET模式下,read一个fd的时候一定要把它的buffer读光,也就是说一直读到read的返回值小于请求值,或者 遇到EAGAIN错误。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll为什么要有EPOLLET触发模式?
如果采用EPOLLLT模式的话,系统中一旦有大量你不需要读写的就绪文件描述符,它们每次调用epoll_wait都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率.。而采用EPOLLET这种边沿触发模式的话,当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。
如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符
epoll的优点:
没有最大并发连接的限制,能打开的FD的上限远大于1024(1G的内存上能监听约10万个端口); 效率提升,不是轮询的方式,不会随着FD数目的增加效率下降。只有活跃可用的FD才会调用callback函数;即Epoll最大的优点就在于它只管你“活跃”的连接,而跟连接总数无关,因此在实际的网络环境中,Epoll的效率就会远远高于select和poll。 内存拷贝,利用mmap()文件映射内存加速与内核空间的消息传递;即epoll使用mmap减少复制开销。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
select
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的
epoll
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
2、FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
epoll通过内核和用户空间共享一块内存来实现的。
往期:100期面试题汇总
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
今天对这三种IO多路复用进行对比,参考网上和书上面的资料,整理如下:
1、select实现
select的调用过程如下所示:
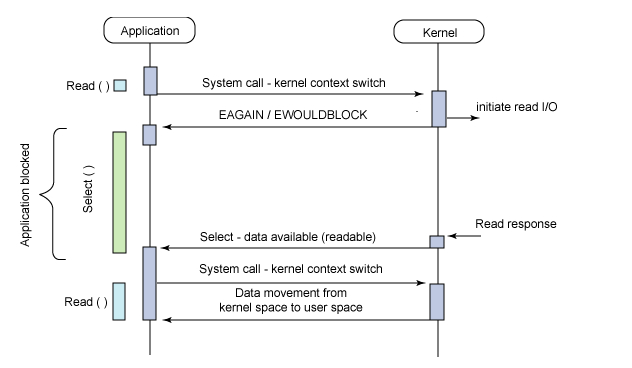
使用copy_from_user从用户空间拷贝fd_set到内核空间 注册回调函数__pollwait 遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll) -以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。 __pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。 poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。 如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。 把fd_set从内核空间拷贝到用户空间。
总结:
select的几大缺点:
每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大 同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大 select支持的文件描述符数量太小了,默认是1024
2、poll实现
poll的实现和select非常相似,只是描述fd集合的方式不同,poll使用pollfd结构而不是select的fd_set结构,其他的都差不多,管理多个描述符也是进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。
poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
3、epoll
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。
而epoll提供了三个函数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。
虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。