
Vision Transformer 必读系列之图像分类综述(一): 概述
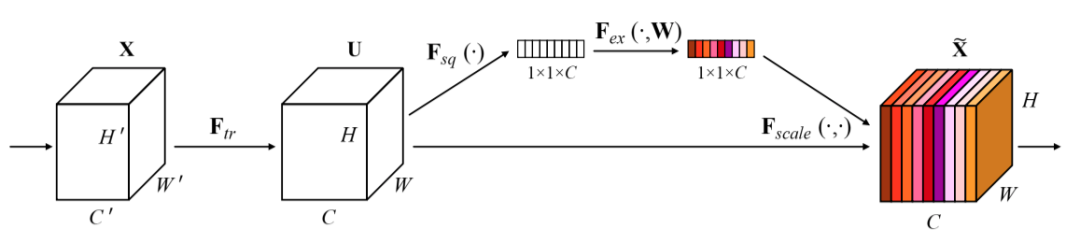
SeNet 网址:
https://arxiv.org/abs/1709.01507
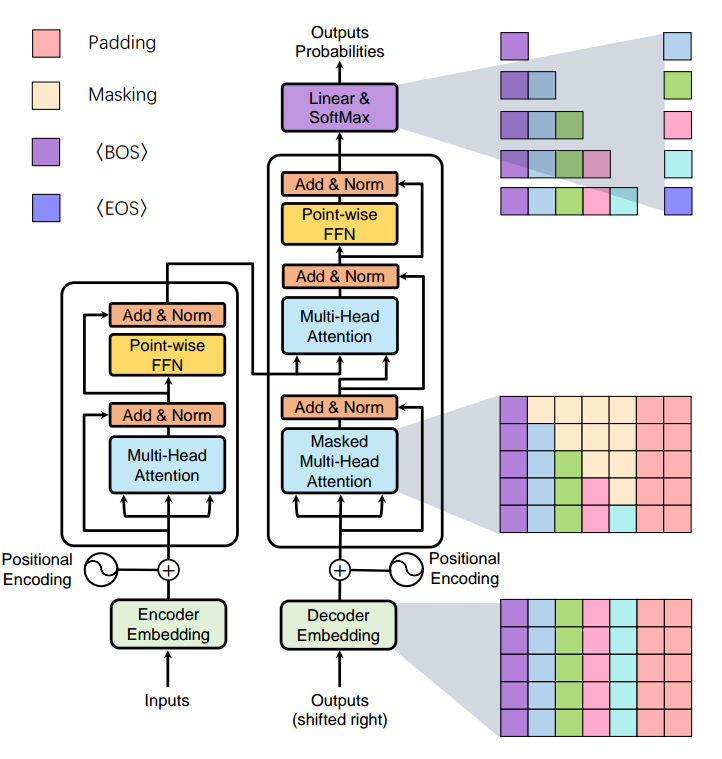
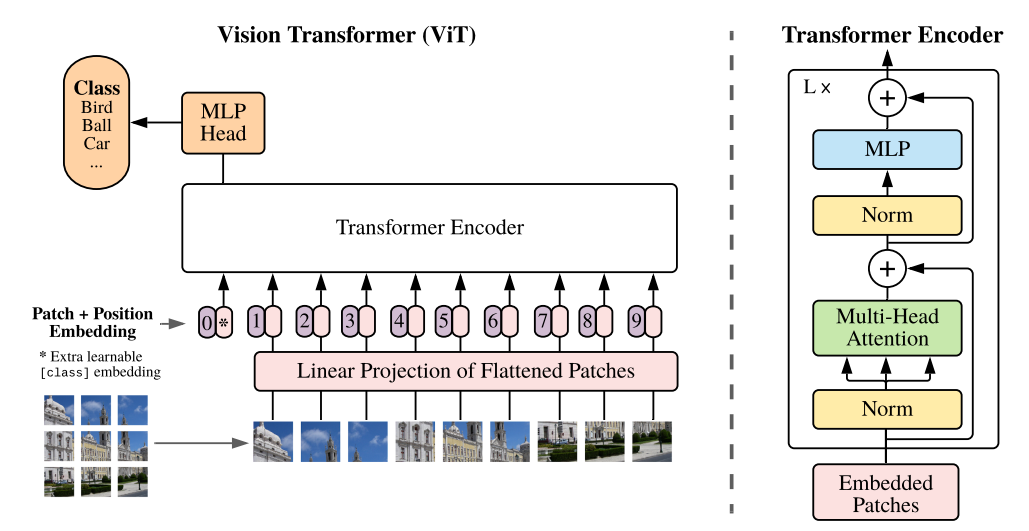
!注意:本文为概述性总结,所以不会对思维导图中包括的每篇论文进行分析,其具体分析会在后续综述文章中详细说明。
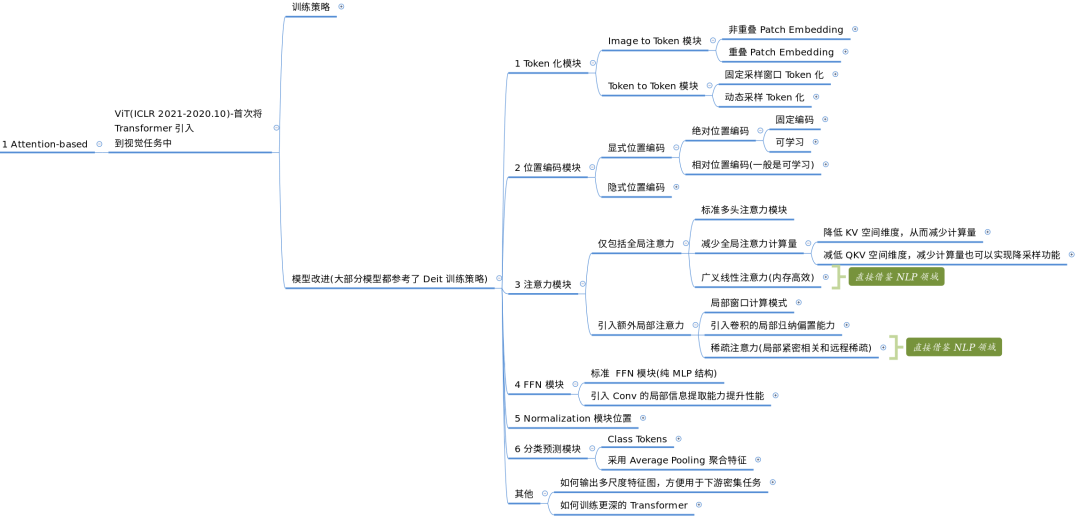
Attention-based
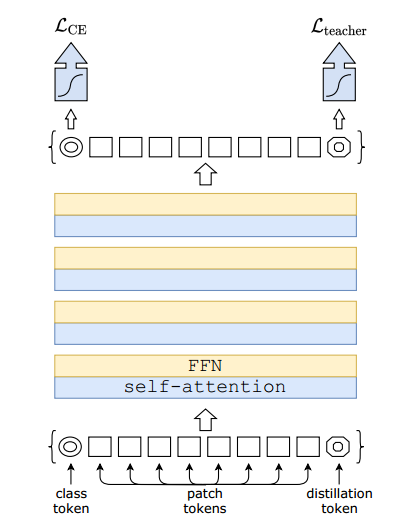
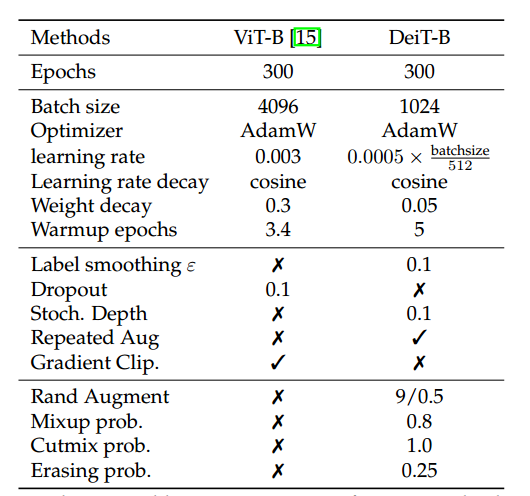
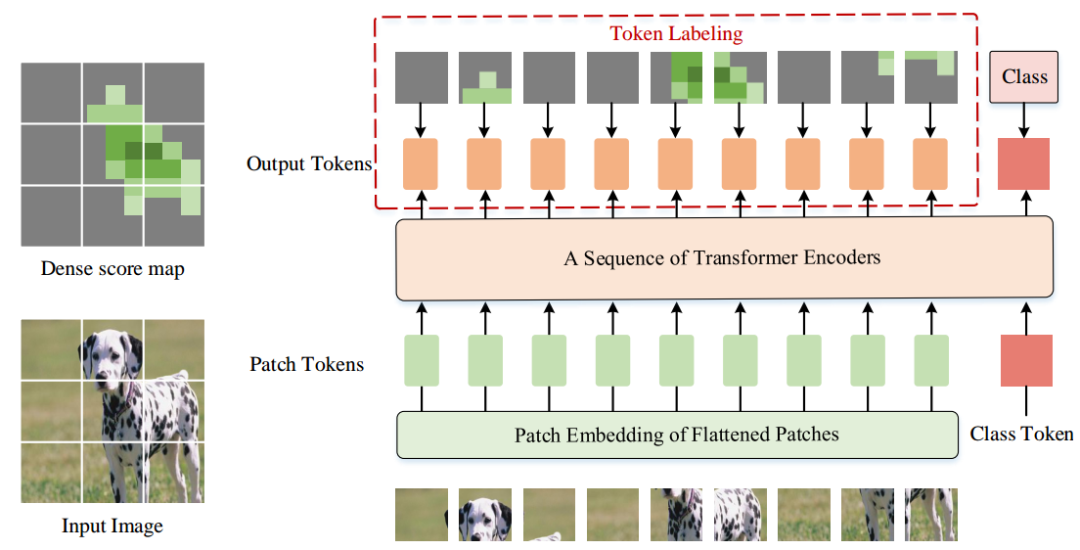
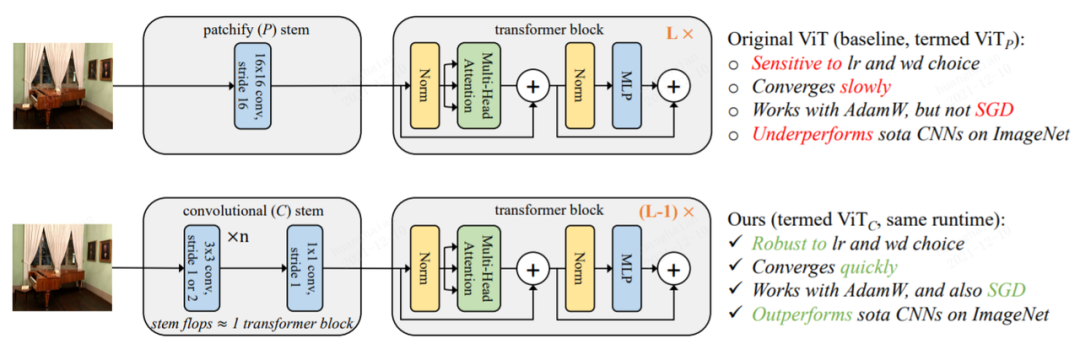
Early Convolutions Help Transformers See Better 链接:
https://arxiv.org/abs/2106.14881
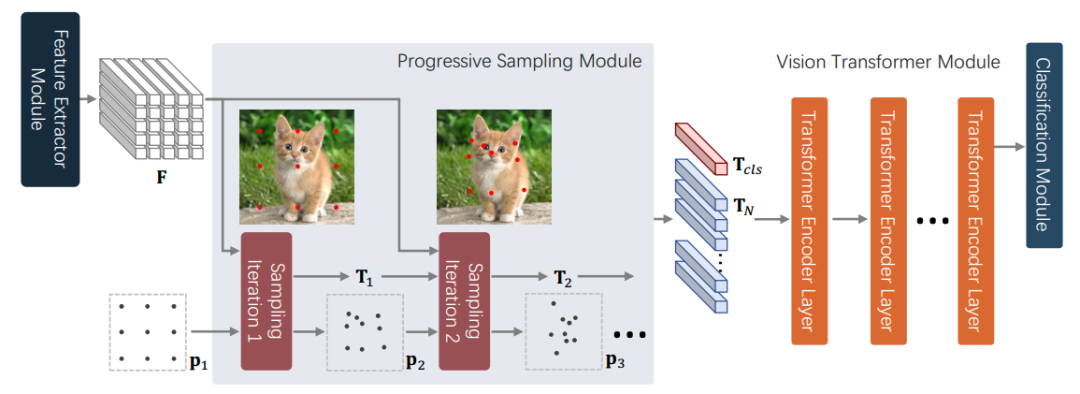
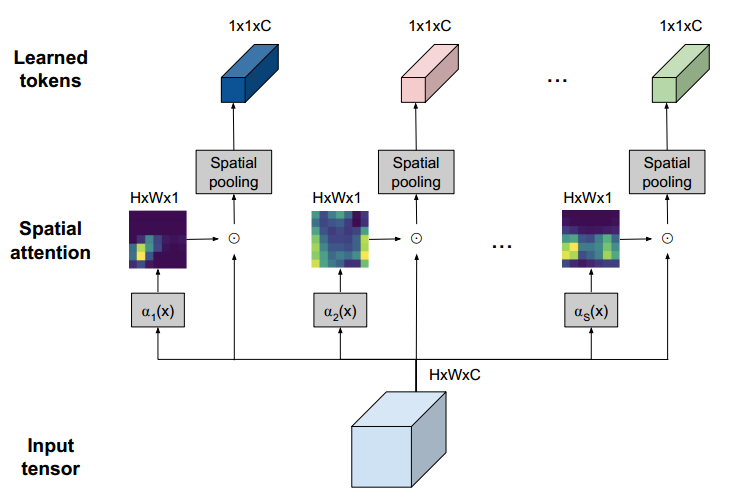

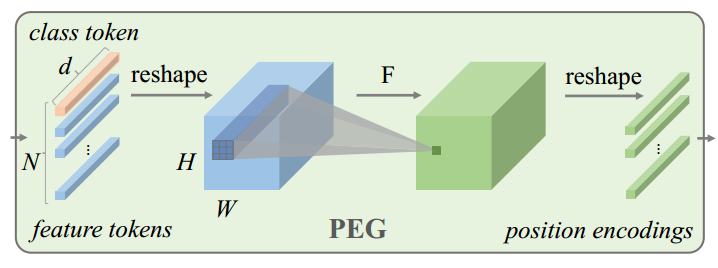
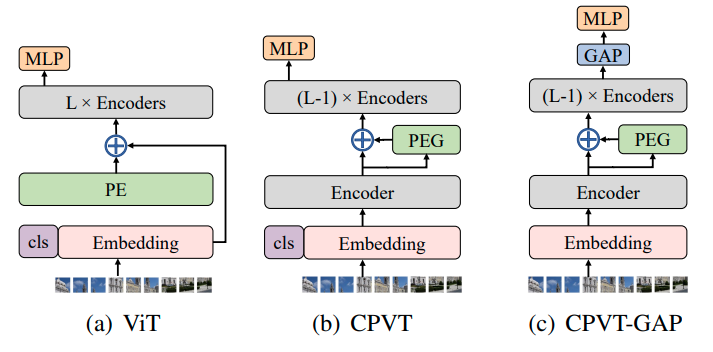
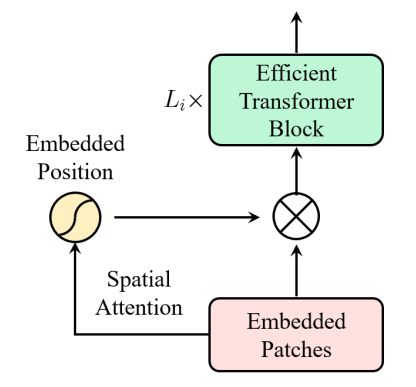
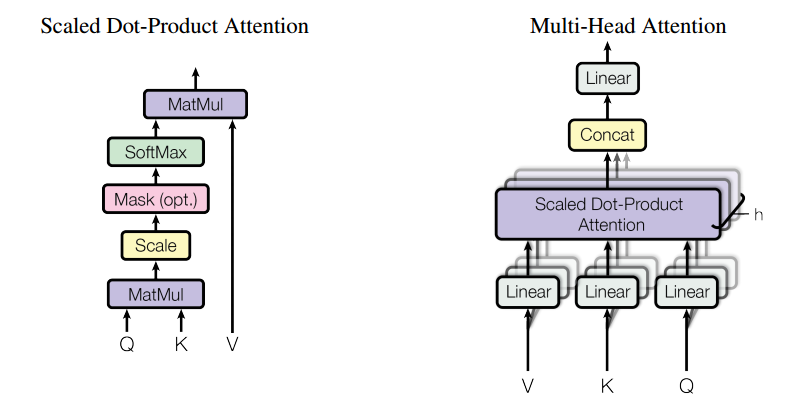
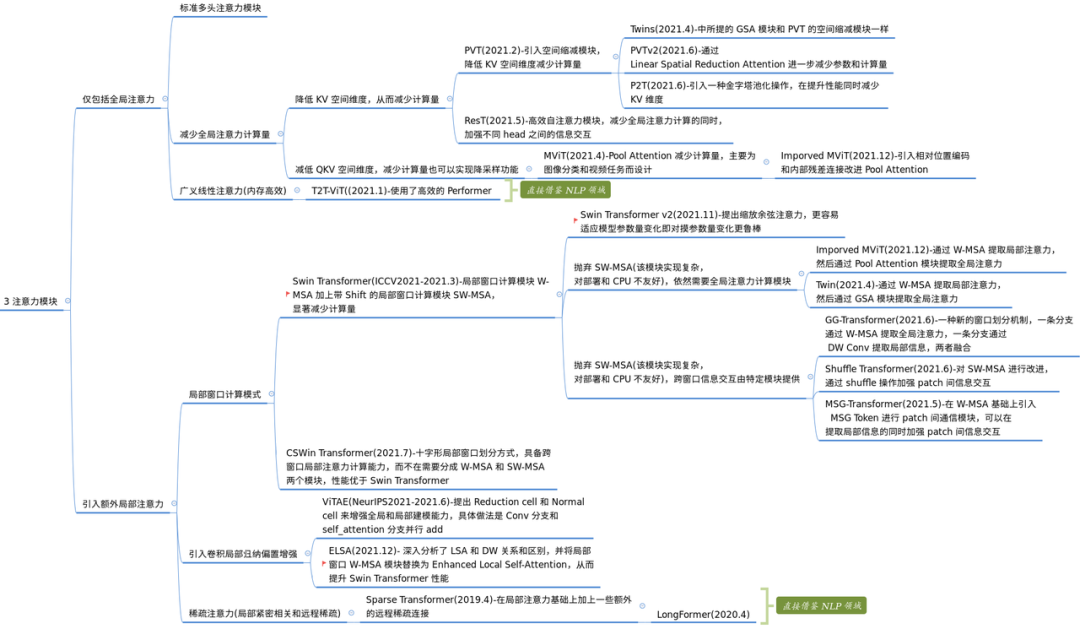




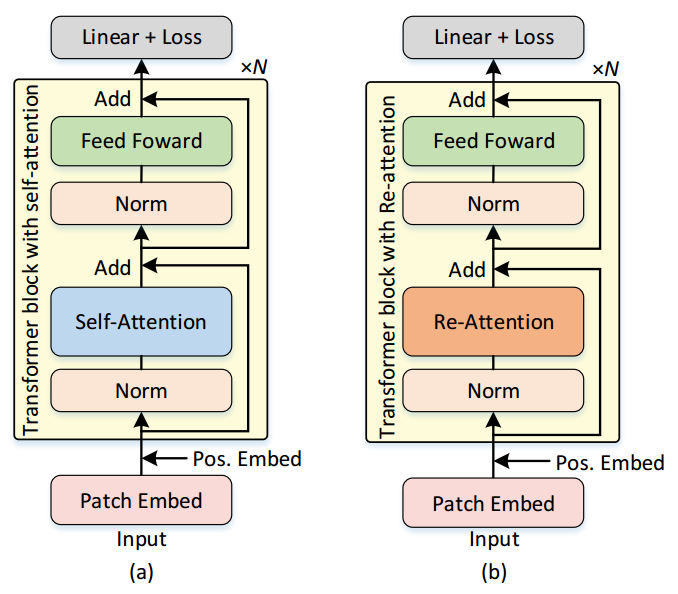
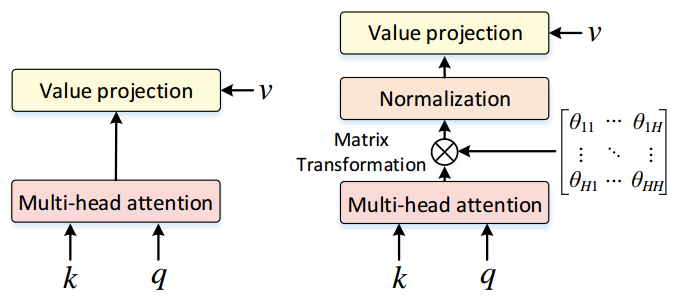
MLP-based

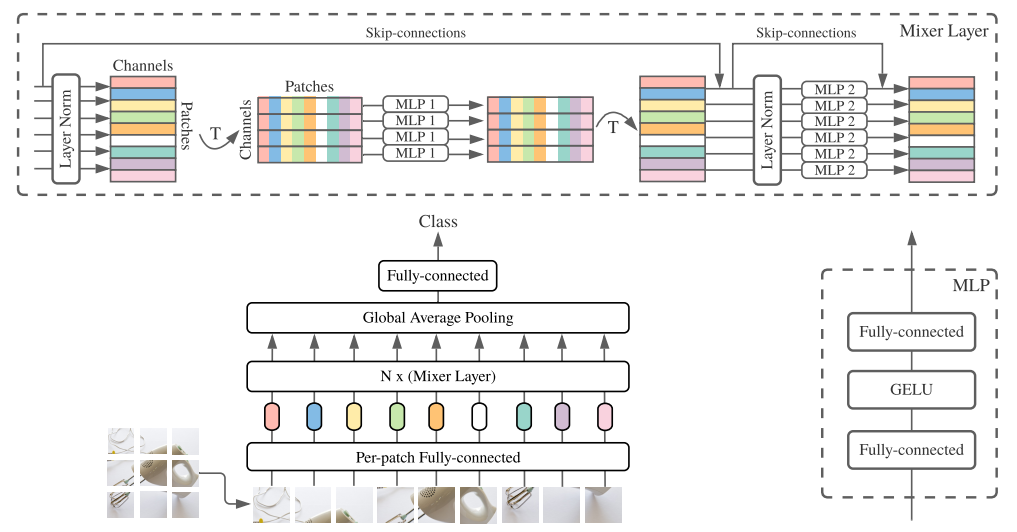
ConvMixer-based

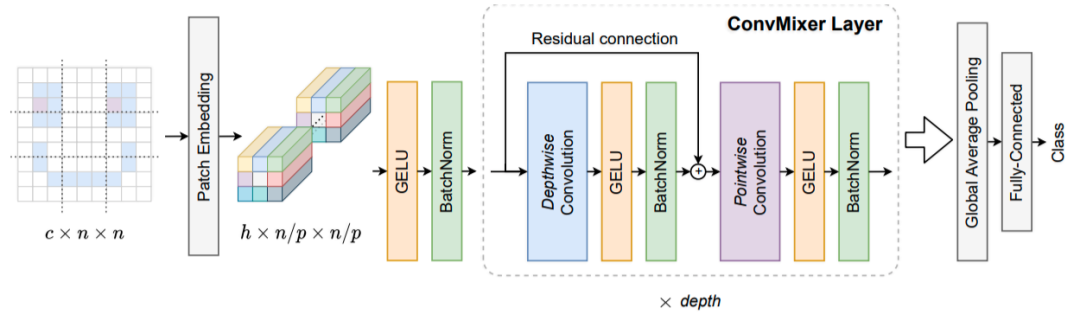
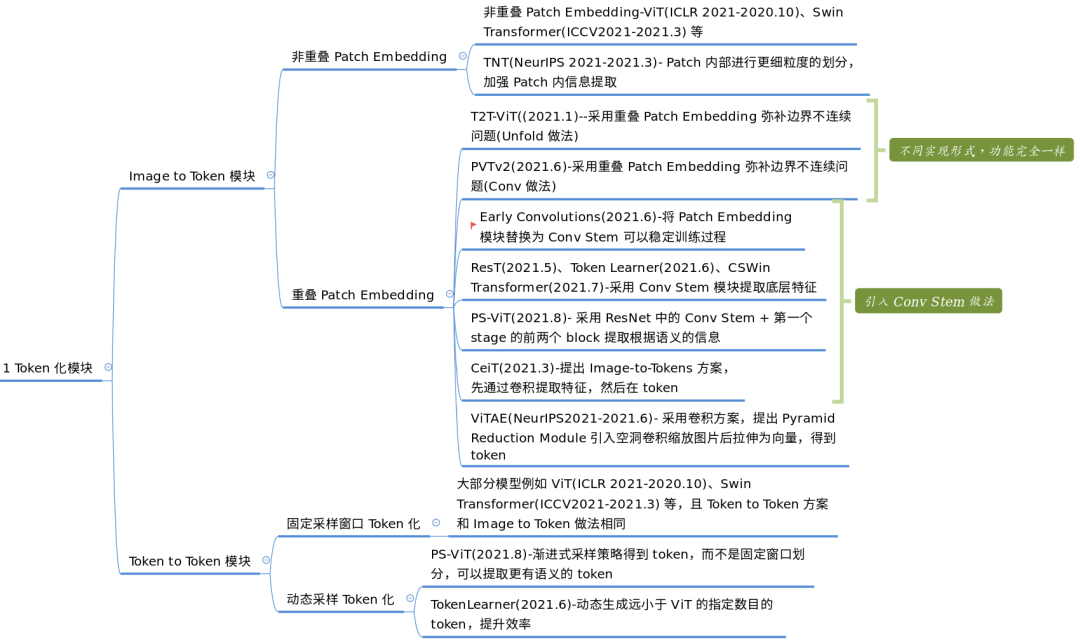
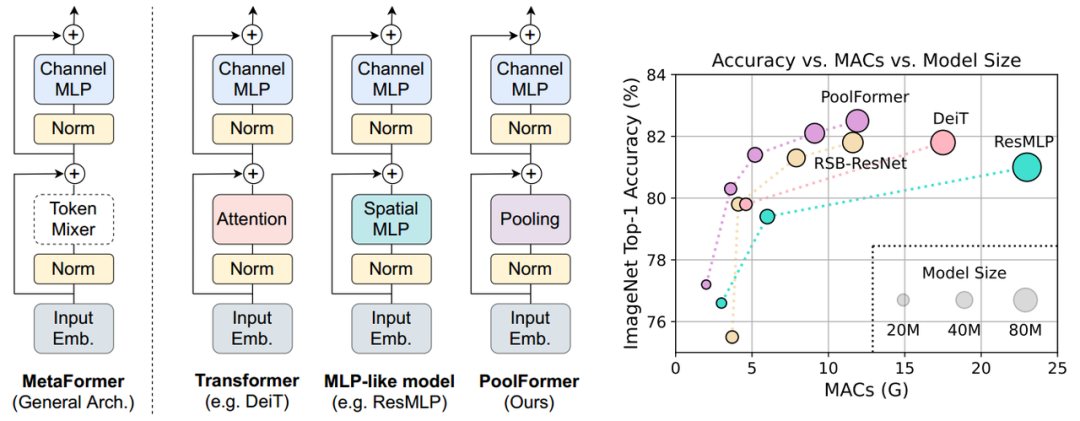
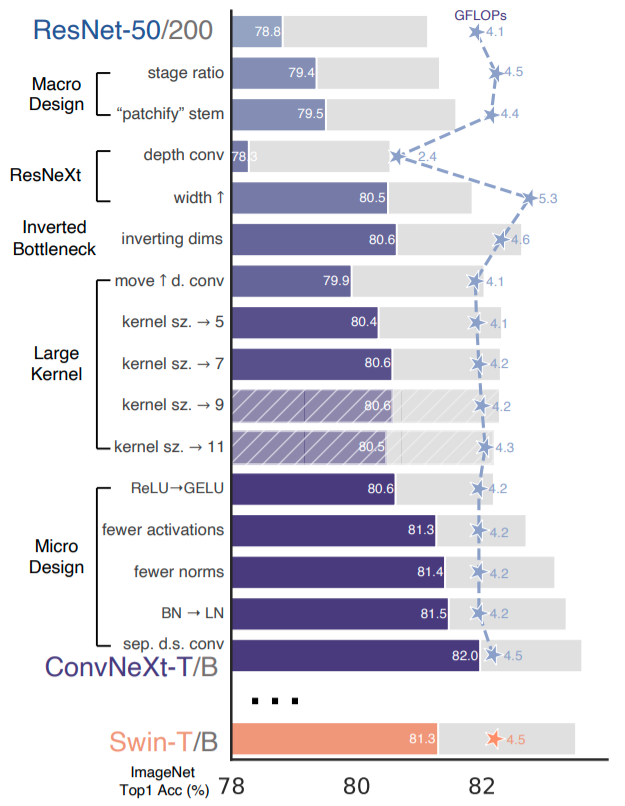
通用架构分析
- The End -
长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!
评论