【神经网络搜索】NasBench301 使用代理模型构建Benchmark
【GiantPandaCV导语】
本文介绍的是NAS中的一个benchmark-NASBench301, 由automl.org组织发表,其核心思想是针对表格型基准存在的不足提出使用代理模型拟合架构与对应准确率。
Paper: NAS-Bench-301 and The case for surrogate benchmarks for Neural Architecture Search
Code: https://github.com/automl/nasbench301
1 动机
NAS领域需要统一的benchmark,否则研究NAS需要的计算量对大多数人来说很难承受。
目前存在的表格型Benchmark(例如NASbench101中使用了表格进行管理,根据网络结构编码得到对应准确率)存在搜索空间受限的问题,同时迁移性比较差。
为了解决以上问题,提出使用代理模型构建benchmark,其中包含了量级的网络架构,同时可以迁移到其他模型空间中。
所谓代理模型可以理解为一个预测器,输入是网络架构编码,输出是对应架构精度。
根据以上介绍,需要重点关注:
为了适配更多的benchmark,如何进行网络编码?
使用代理模型进行回归就一定会带来误差,如何选择回归模型?如何避免误差带来干扰?
2 贡献
提出代理NAS Benchmark - NAS-Bench-301, 其搜索空间能够覆盖真实场景中NAS的空间(规模),提出使用代理来估计模型性能。
证明了使用代理模型来拟合架构能够比表格型benchmark更能反映架构的真实性能 。
分析并开源了NASbench301的训练集(60k规模),详见Open Graph Benchmark
在NASBench301上详尽的评估了一系列回归模型,证明了在更大的搜索空间中,归回模型依然可以表现出很强的泛化能力。
在NASBench301上运行了一系列NAS算法,发现NAS算法搜索轨迹和真实的搜索轨迹是高度一致的 。
NASBench301可以得到科研方面的insight,以local search为例进行了实验。
3 证明代理模型优越性
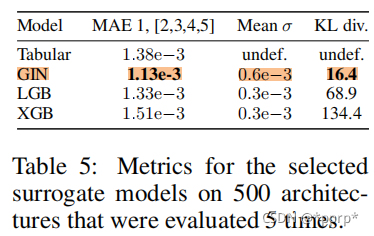
在seed不固定的情况下,模型运行结果并不是固定的,即便是seed固定,一些模型也存在无法精确复现的问题。NAS的Benchmark制作中也会遇到这样的问题,NASBench101中使用三个不同的seed从头开始训练,得到对应模型的三个精度。因此对表格型的基准来说,也是存在一定的误差的,如果基于代理的基准的MAE(MeanAbsoluteError)能够低于表格型,就证明其具有更好的预测能力。
实验结果如下:
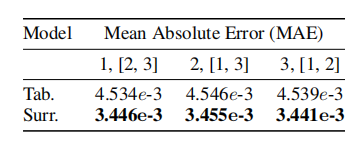
其中代理模型选择是GIN(A fair comparison of graph neural networks for graph classification),实验发现代理模型可以随着训练规模的增大,更好的学习平滑噪声。
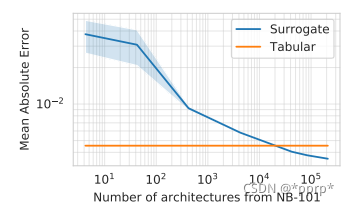
4 NAS-Bench-301数据集
NAS-Bench-301数据集详细信息如下:
由60k个架构组成
数据集是CIFAR10
搜索空间:DARTS-Like search space
3.1 数据采集
由于搜索空间巨大,不可能将整个搜索空间遍历并训练,需要考虑均匀采样搜索空间。
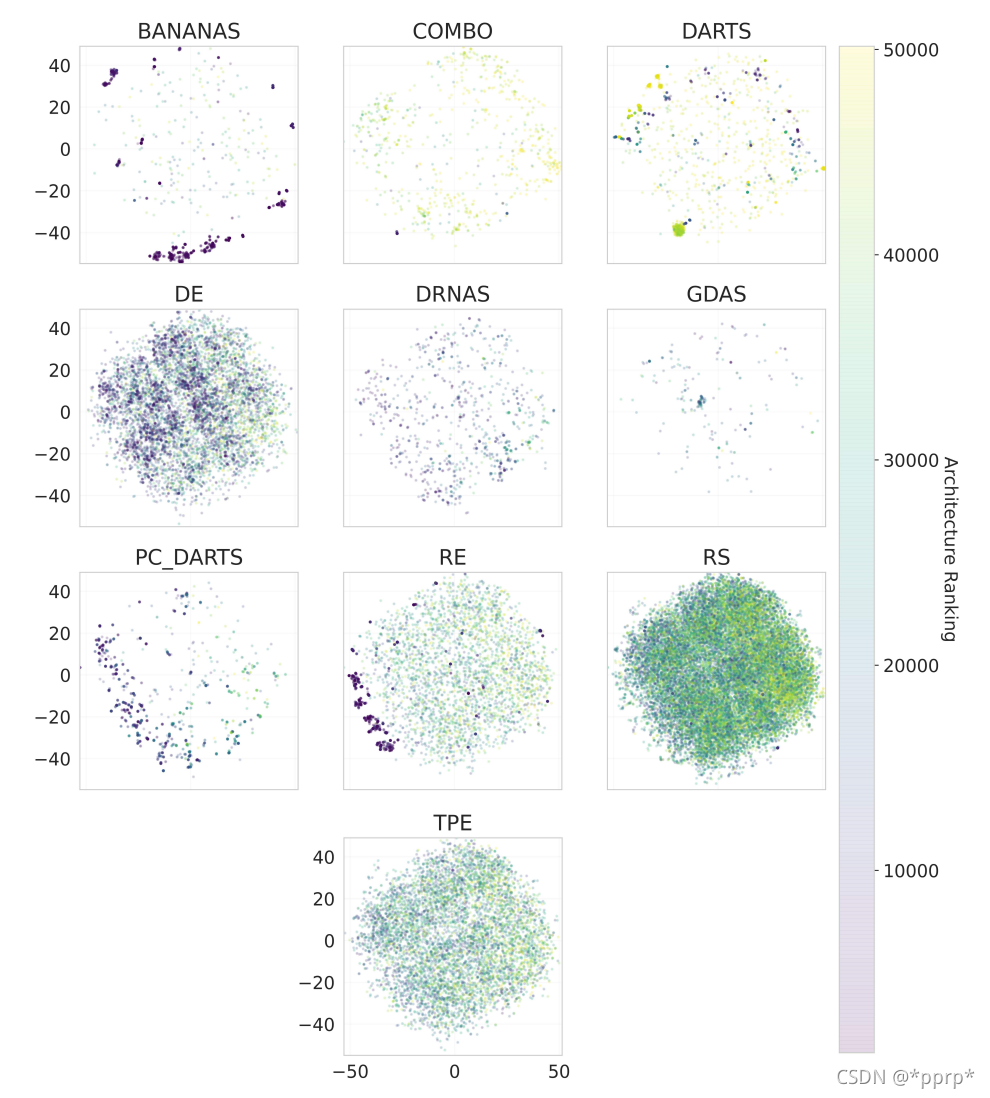
通过对整个搜索空间进行可视化t-SNE:
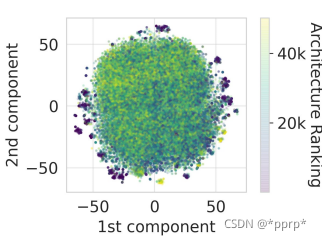
可以发现,并不存在大量突变,同时性能最好的架构在整个簇的外边,形成独立的簇。
可视化不同算法在整个搜索空间中采样结果可得:
3.2 性能表现统计
参数量和验证集error:可以发现形成了帕累托前沿。
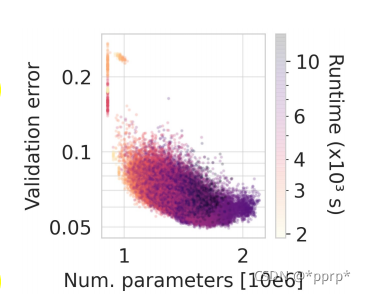
比较奇特的是,随着参数量的增加,error还会进行一次反弹,这说明模型容量过大会导致出现过拟合问题。
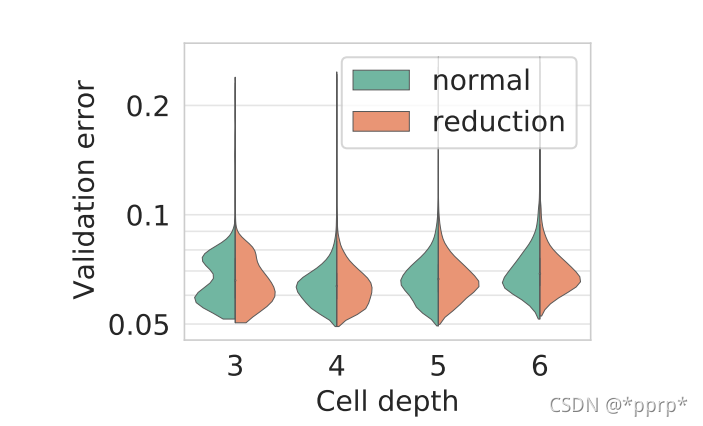
下图发现Cell depth对性能影响不大:
5 在NAS-Bench-301拟合代理模型
代理模型的任务还是回归,本文中并没有提出新的回归模型,而是普遍验证了多种回归算法并进行选择。
可选的代理模型有:
Deep GCN
GIN
Random Forests
Support Vector Regression(SVR)
XGBoost
LGBoost
NGBoost
predictor-based NAS
评估指标包括:
决定系数R
sparse Kendall Tau肯德尔系数
肯德尔系数适用评估模型预测的排序与真实排序的一致性,普通的肯德尔系数过于严苛,需要整个排序严格一致,但是由于相同精度的模型可能数量非常多,如果排序过于严格会导致指标不够精确,所以稀疏肯德尔系数允许出现0.1%的排序改变,能够更好地反映代理模型的性能。
实验结果:最好的几个模型是:LGBoost,XGBoost,GIN, 因而
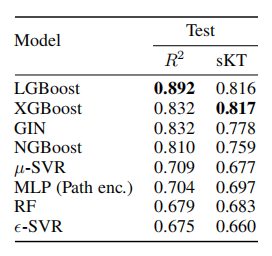
引入噪声建模:发现GIN依然是性能最好的。
6 注意事项
使用NASBench301存在的风险和注意事项:
代理模型被视为黑盒,只能用于预测模型,但不应该被用于提取梯度信息。
不鼓励使用类似于NASBench301中的代理模型,如GNN-based 贝叶斯优化方法,GIN
为了确保可比性,在测评过程中需要提供基准的版本号,比如NB301-XGB-v1.0, NB301-GIN-v1.0
7 代码使用
环境安装:
git clone https://github.com/automl/nasbench301.git
cd nasbench301
cat requirements.txt | xargs -n 1 -L 1 pip install
pip install .
环境安装可能会出现问题,因为原先的requirements.txt只针对cuda10.0,如果本身就是cuda10.0环境可以直接使用官方提供的api,但是如果是cuda11.1可以继续往下看。
安装过程中,主要是问题在于torch_sparse包安装非常繁琐,对版本要求非常高。如果版本不匹配,会出现段错误,或者undefined symbols等问题。
torch_sparse: https://github.com/rusty1s/pytorch_sparse
本文所用环境:
ubuntu16.04
cuda11.1
torch=1.8+cu111
python==3.7
经过一整天的配置,终于试出来一个版本:
torch==1.8.0+cu111 -f https://download.pytorch.org/whl/cu111/torch_stable.html
torchvision==0.9.0+cu111 -f https://download.pytorch.org/whl/cu111/torch_stable.html
torch-scatter==2.0.6 -f https://data.pyg.org/whl/torch-1.9.0%2Bcu111.html
torch-sparse==0.6.12 -f https://data.pyg.org/whl/torch-1.9.0%2Bcu111.html
torch-cluster==1.5.9 -f https://data.pyg.org/whl/torch-1.9.0%2Bcu111.html
torch-spline-conv==1.2.0 -f https://data.pyg.org/whl/torch-1.9.0%2Bcu111.html
torch-geometric==1.6.3
torch-scatter中提供的源:https://data.pyg.org/whl/torch-1.9.0%2Bcu111.html
nasbench301使用的源:https://pytorch-geometric.com/whl/torch-1.9.0%2Bcu111.html
torch官方源:https://download.pytorch.org/whl/cu111/torch_stable.html
遇到的错误:
TypeError: load() missing 1 required positional argument: ‘Loader‘
YAML 5.1版本后弃用了yaml.load(file)这个用法,因为觉得很不安全,5.1版本之后就修改了需要指定Loader,通过默认加载器(FullLoader)禁止执行任意函数,该load函数也变得更加安全
用以下三种方式都可以
d1=yaml.load(file,Loader=yaml.FullLoader)
d1=yaml.safe_load(file)
d1 = yaml.load(file, Loader=yaml.CLoader)
原文链接:https://blog.csdn.net/qq_34495095/article/details/120905179
OSError: python3.7/site-packages/torch_sparse/_version_cuda.so: undefined symbol
这个主要是由于环境不匹配导致的问题,需要选择正确对应关系的版本。如果有更好的解决方案也欢迎联系笔者。