
支付宝三面:聊聊时间轮算法?哪些开源项目用到了?怎么用的?
共 6111字,需浏览 13分钟
·
2021-02-24 13:39

昨晚去图书馆转了一下,环境还不错哦!
大家好,我是 Guide哥。今天这篇文章所聊的话题,非常重要!不论是你想在面试中脱颖而出,还是你想要搞懂 Netty、Kafka、Zookeeper 等等中间件的原理,你都务必要把这篇文章仔细阅读完!一遍看不懂就多看几遍,相信我,你一定会有收获!总之,搞懂时间轮算法真的非常有必要!!!
另外,我建议你在搞懂了时间轮算法的原理之后,可以参考一些开源项目对时间轮算法的实现,自己也手写一个。 下面是正文!
最近看 Kafka 看到了时间轮算法,记得以前看 Netty 也看到过这玩意,没太过关注。今天就来看看时间轮到底是什么东西。
为什么要用时间轮算法来实现延迟操作?
延时操作 Java 不是提供了 Timer 么?
还有 DelayQueue 配合线程池或者 ScheduledThreadPool 不香吗?
我们先来简单看看 Timer、DelayQueue 和 ScheduledThreadPool 的相关实现,看看它们是如何实现延时任务的,源码之下无秘密。再来剖析下为何 Netty 和 Kafka 特意实现了时间轮来处理延迟任务。
如果在手机上阅读其实纯看字也行,不用看代码,我都会先用文字描述清楚。不过电脑上看效果更佳。
Timer
Timer 可以实现延时任务,也可以实现周期性任务。我们先来看看 Timer 核心属性和构造器。

核心就是一个优先队列和封装的执行任务的线程,从这我们也可以看到一个 Timer 只有一个线程执行任务。
再来看看如何实现延时和周期性任务的。我先简单的概括一下,首先维持一个小顶堆,即最快需要执行的任务排在优先队列的第一个,根据堆的特性我们知道插入和删除的时间复杂度都是 O(logn)。
然后 TimerThread 不断地拿排着的第一个任务的执行时间和当前时间做对比。如果时间到了先看看这个任务是不是周期性执行的任务,如果是则修改当前任务时间为下次执行的时间,如果不是周期性任务则将任务从优先队列中移除。最后执行任务。如果时间还未到则调用 wait() 等待。
再看下图,整理下流程。
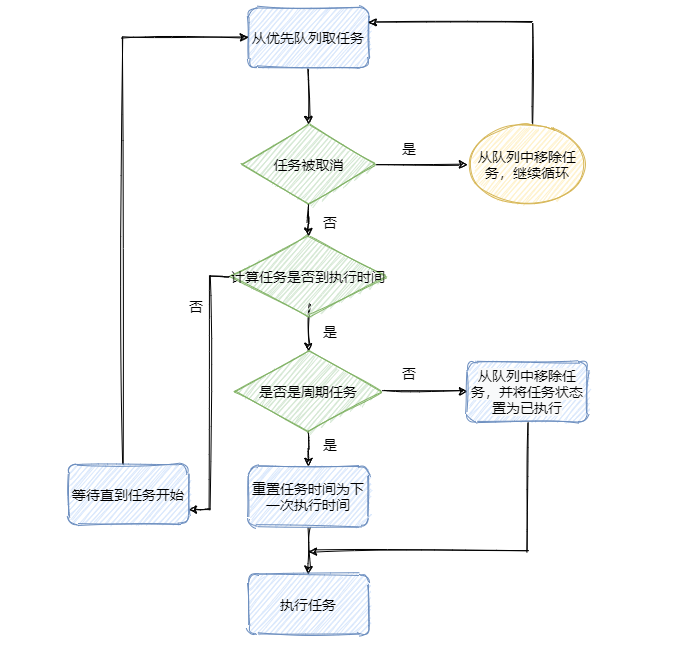
流程知道了再对着看下代码,这块就差不多了。看代码不爽的可以跳过代码部分,影响不大。
先来看下 TaskQueue,就简单看下插入任务的过程,就是个普通的堆插入操作。
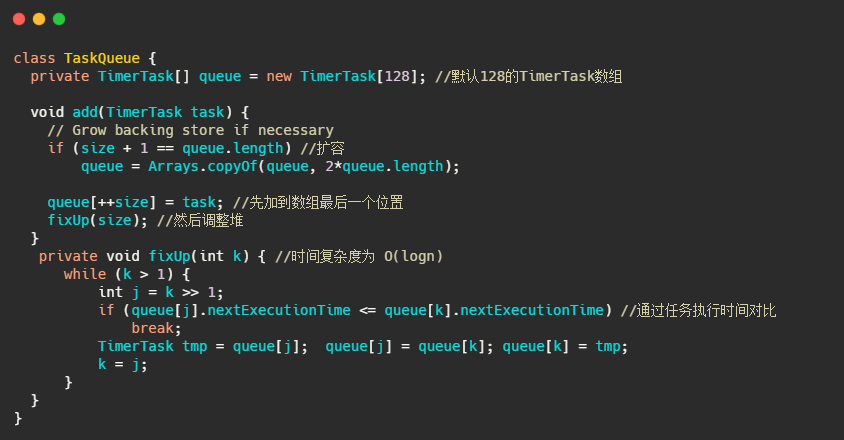
再来看看 TimerThread 的 run 操作。
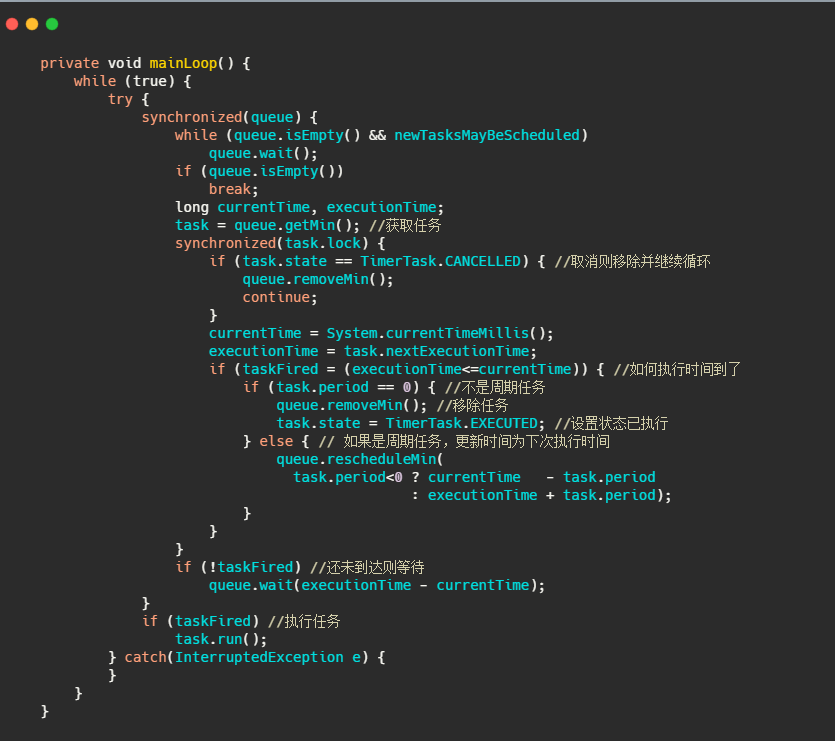
小结一下
可以看出 Timer 实际就是根据任务的执行时间维护了一个优先队列,并且起了一个线程不断地拉取任务执行。
有什么弊端呢?
首先优先队列的插入和删除的时间复杂度是O(logn),当数据量大的时候,频繁的入堆出堆性能有待考虑。
并且是单线程执行,那么如果一个任务执行的时间过久则会影响下一个任务的执行时间(当然你任务的run要是异步执行也行)。
并且从代码可以看到对异常没有做什么处理,那么一个任务出错的时候会导致之后的任务都无法执行。
ScheduledThreadPoolExecutor
在说 ScheduledThreadPoolExecutor 之前我们再看下 Timer 的注释,注释可都是干货千万不要错过。我做了点修改,突出了下重点。
Java 5.0 introduced ScheduledThreadPoolExecutor, It is effectively a more versatile replacement for the Timer, it allows multiple service threads. Configuring with one thread makes it equivalent to Timer。
简单翻译下:1.5 引入了 ScheduledThreadPoolExecutor,它是一个具有更多功能的 Timer 的替代品,允许多个服务线程。如果设置一个服务线程和 Timer 没啥差别。
从注释看出相对于 Timer ,可能就是单线程跑任务和多线程跑任务的区别。我们来看下。
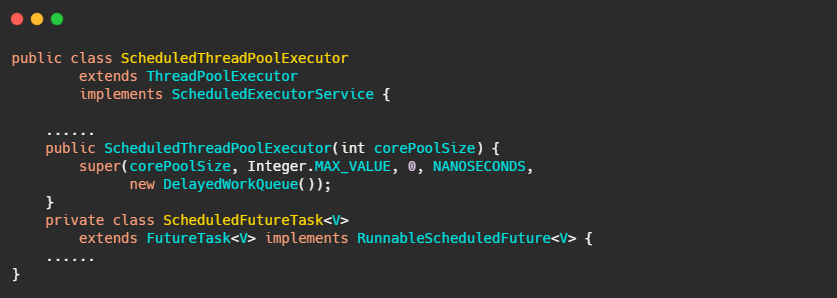
继承了 ThreadPoolExecutor,实现了 ScheduledExecutorService。可以定性操作就是正常线程池差不多了。区别就在于两点,一个是 ScheduledFutureTask ,一个是 DelayedWorkQueue。
其实 DelayedWorkQueue 就是优先队列,也是利用数组实现的小顶堆。而 ScheduledFutureTask 继承自 FutureTask 重写了 run 方法,实现了周期性任务的需求。
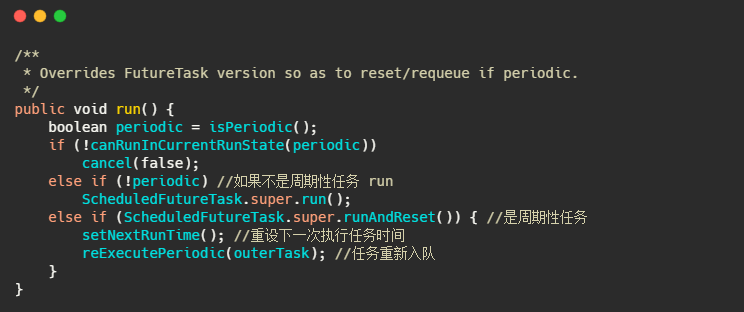
小结一下
ScheduledThreadPoolExecutor 大致的流程和 Timer 差不多,也是维护一个优先队列,然后通过重写 task 的 run 方法来实现周期性任务,主要差别在于能多线程运行任务,不会单线程阻塞。
并且 Java 线程池的设定是 task 出错会把错误吃了,无声无息的。因此一个任务出错也不会影响之后的任务。
DelayQueue
Java 中还有个延迟队列 DelayQueue,加入延迟队列的元素都必须实现 Delayed 接口。延迟队列内部是利用 PriorityQueue 实现的,所以还是利用优先队列!Delayed 接口继承了Comparable 因此优先队列是通过 delay 来排序的。

然后我们再来看下延迟队列是如何获取元素的。
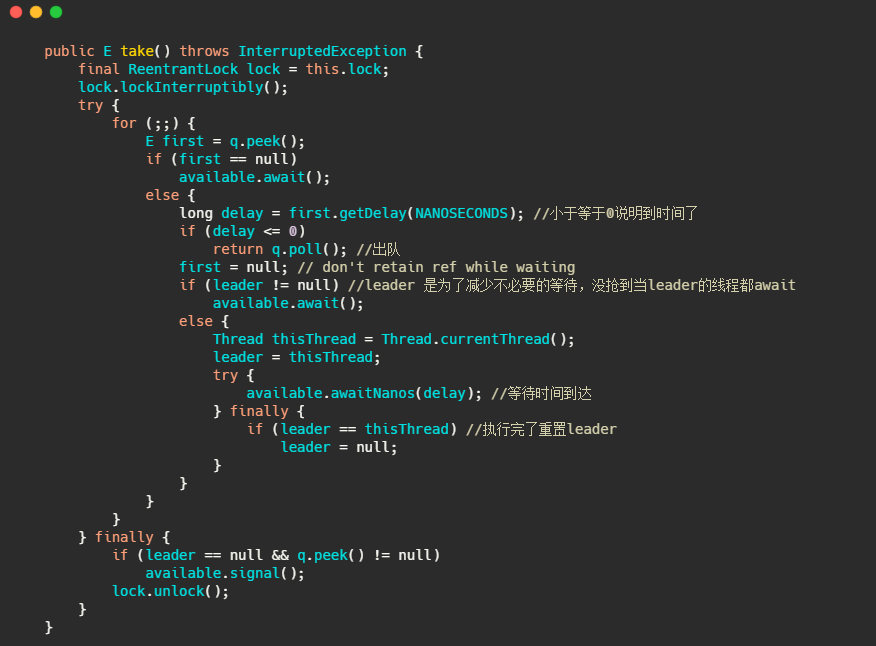
小结一下
也是利用优先队列实现的,元素通过实现 Delayed 接口来返回延迟的时间。不过延迟队列就是个容器,需要其他线程来获取和执行任务。
这下是搞明白了 Timer 、ScheduledThreadPool 和 DelayQueue,总结的说下它们都是通过优先队列来获取最早需要执行的任务,因此插入和删除任务的时间复杂度都为O(logn),并且 Timer 、ScheduledThreadPool 的周期性任务是通过重置任务的下一次执行时间来完成的。
问题就出在时间复杂度上,插入删除时间复杂度是O(logn),那么假设频繁插入删除次数为 m,总的时间复杂度就是O(mlogn),这种时间复杂度满足不了 Kafka 这类中间件对性能的要求,而时间轮算法的插入删除时间复杂度是O(1)。我们来看看时间轮算法是如何实现的。
时间轮算法
俗话说艺术源于生活,技术也能从日常生活中找到灵感。咱们先来看块表,嗯金色的表。
都看清楚了吧,时间轮就是和手表时钟很相似的存在。时间轮用环形数组实现,数组的每个元素可以称为槽,和 HashMap一样称呼。
槽的内部用双向链表存着待执行的任务,添加和删除的链表操作时间复杂度都是 O(1),槽位本身也指代时间精度,比如一秒扫一个槽,那么这个时间轮的最高精度就是 1 秒。
也就是说延迟 1.2 秒的任务和 1.5 秒的任务会被加入到同一个槽中,然后在 1 秒的时候遍历这个槽中的链表执行任务。
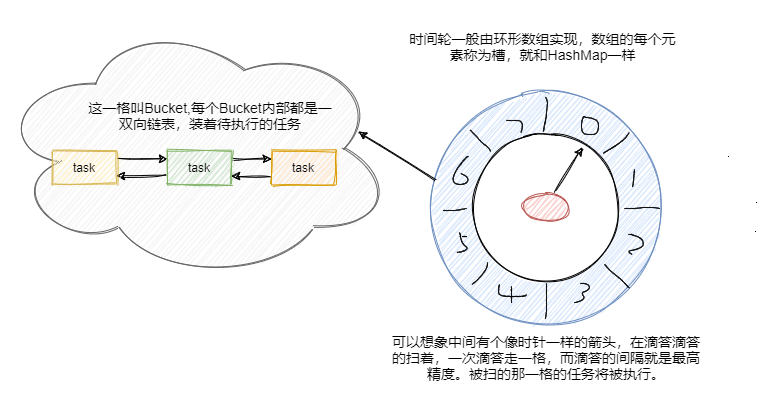
从图中可以看到此时指针指向的是第一个槽,一共有八个槽0~7,假设槽的时间单位为 1 秒,现在要加入一个延时 5 秒的任务,计算方式就是 5 % 8 + 1 = 6,即放在槽位为 6,下标为 5 的那个槽中。更具体的就是拼到槽的双向链表的尾部。
然后每秒指针顺时针移动一格,这样就扫到了下一格,遍历这格中的双向链表执行任务。然后再循环继续。
可以看到插入任务从计算槽位到插入链表,时间复杂度都是O(1)。那假设现在要加入一个50秒后执行的任务怎么办?这槽好像不够啊?难道要加槽嘛?和HashMap一样扩容?
不是的,常见有两种方式,一种是通过增加轮次的概念。50 % 8 + 1 = 3,即应该放在槽位是 3,下标是 2 的位置。然后 (50 - 1) / 8 = 6,即轮数记为 6。也就是说当循环 6 轮之后扫到下标的 2 的这个槽位会触发这个任务。Netty 中的 HashedWheelTimer 使用的就是这种方式。
还有一种是通过多层次的时间轮,这个和我们的手表就更像了,像我们秒针走一圈,分针走一格,分针走一圈,时针走一格。
多层次时间轮就是这样实现的。假设上图就是第一层,那么第一层走了一圈,第二层就走一格。
可以得知第二层的一格就是8秒,假设第二层也是 8 个槽,那么第二层走一圈,第三层走一格,可以得知第三层一格就是 64 秒。
那么一格三层,每层8个槽,一共 24 个槽时间轮就可以处理最多延迟 512 秒的任务。
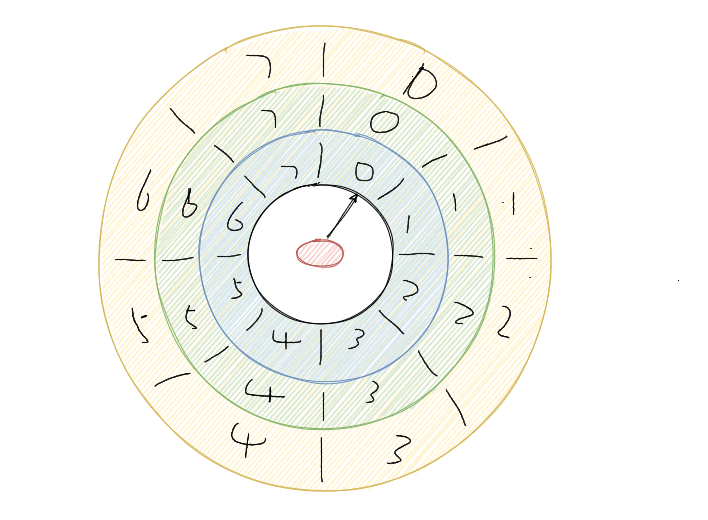
而多层次时间轮还会有降级的操作,假设一个任务延迟 500 秒执行,那么刚开始加进来肯定是放在第三层的,当时间过了 436 秒后,此时还需要 64 秒就会触发任务的执行,而此时相对而言它就是个延迟 64 秒后的任务,因此它会被降低放在第二层中,第一层还放不下它。
再过个 56 秒,相对而言它就是个延迟 8 秒后执行的任务,因此它会再被降级放在第一层中,等待执行。
降级是为了保证时间精度一致性。Kafka内部用的就是多层次的时间轮算法。
Netty中的时间轮
在 Netty 中时间轮的实现类是 HashedWheelTimer,代码中的 wheel 就是上图画的循环数组,mask 的设计和HashMap一样,通过限制数组的大小为2的次方,利用位运算来替代取模运算,提高性能。tickDuration 就是每格的时间即精度。可以看到配备了一个工作线程来处理任务的执行。
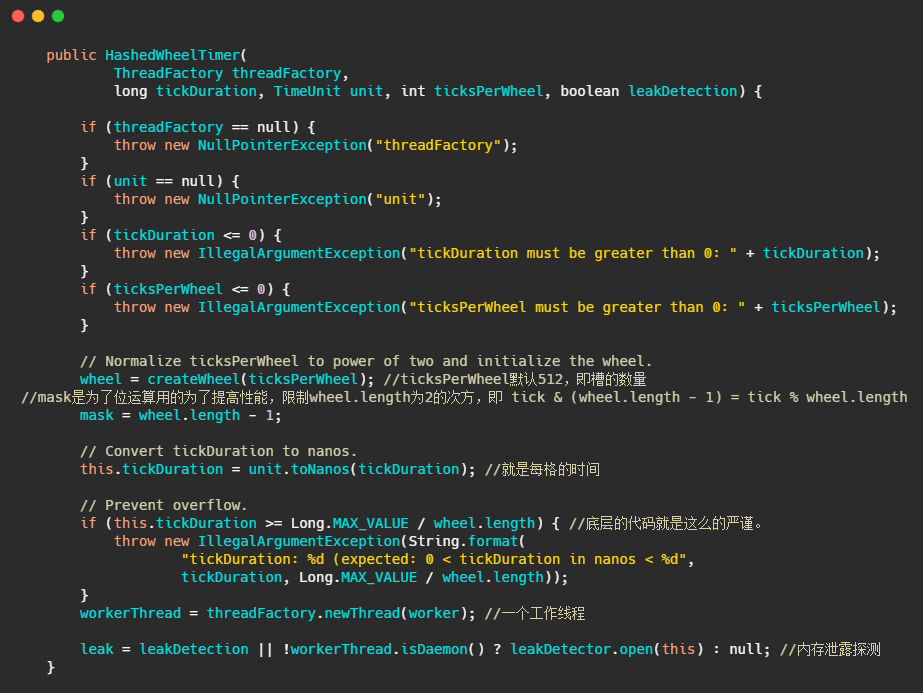
接下来我们再来看看任务是如何添加的。
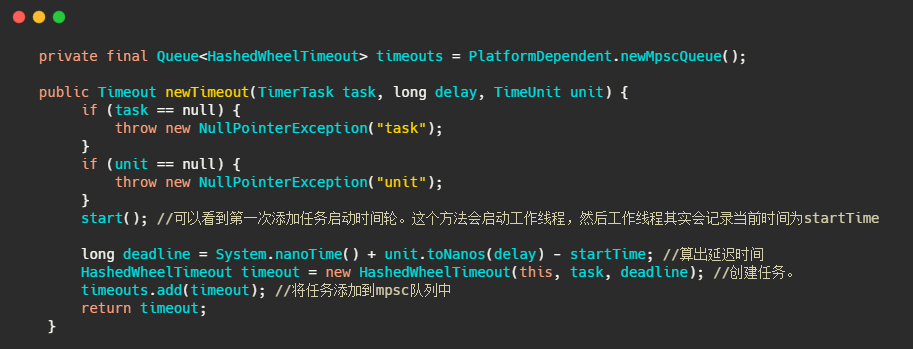
可以看到任务并没有直接添加到时间轮中,而是先入了一个 mpsc 队列,我简单说下 mpsc 是 JCTools 中的并发队列,用在多个生产者可同时访问队列,但只有一个消费者会访问队列的情况。篇幅有限,有兴趣的朋友自行了解实现。
然后我们再来看看工作线程是如何运作的。

很直观没什么花头,我们先来看看 waitForNextTick,是如何得到下一次执行时间的。
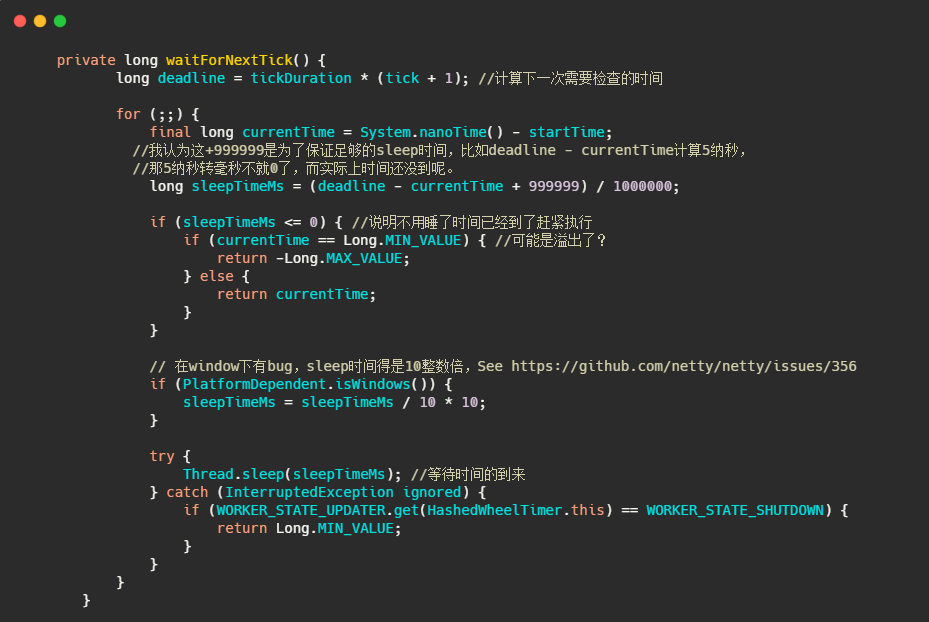
简单的说就是通过 tickDuration 和此时已经滴答的次数算出下一次需要检查的时间,时候未到就sleep等着。
再来看下任务如何入槽的。
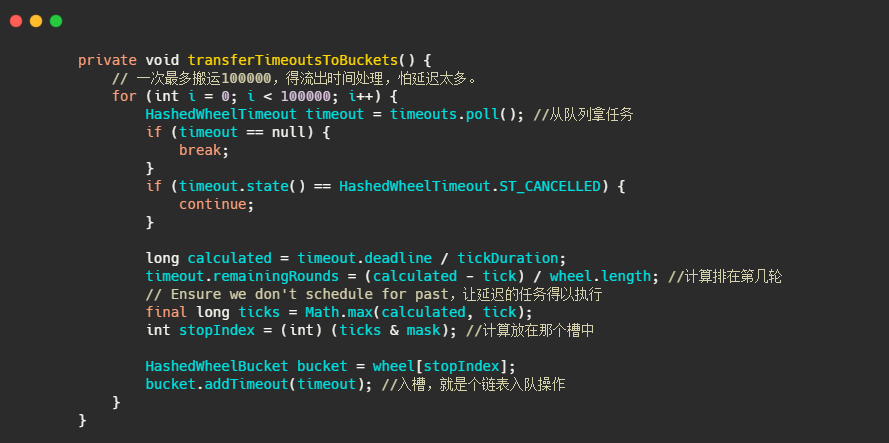
注释的很清楚了,实现也和上述分析的一致。
最后再来看下如何执行的。
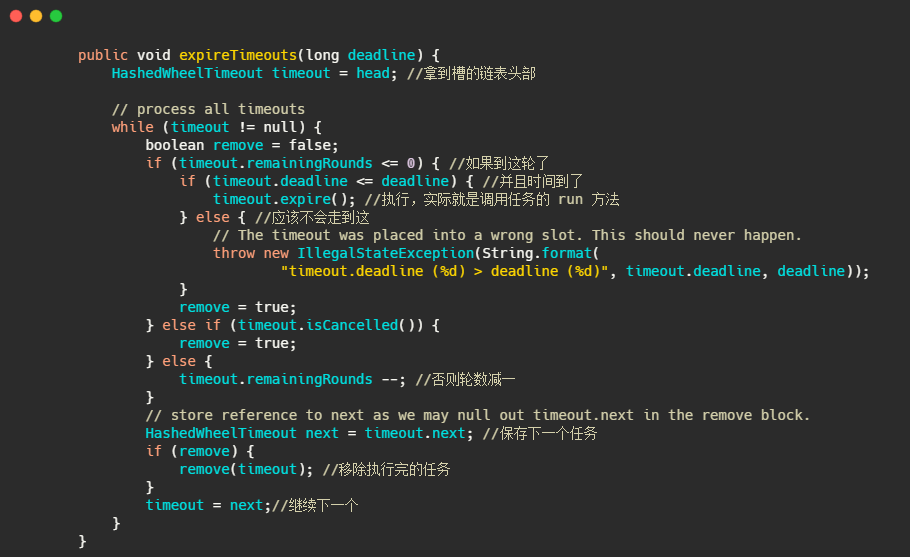
就是通过轮数和时间双重判断,执行完了移除任务。
小结一下
总体上看 Netty 的实现就是上文说的时间轮通过轮数的实现,完全一致。可以看出时间精度由 TickDuration 把控,并且工作线程的除了处理执行到时的任务还做了其他操作,因此任务不一定会被精准的执行。
而且任务的执行如果不是新起一个线程,或者将任务扔到线程池执行,那么耗时的任务会阻塞下个任务的执行。
并且会有很多无用的 tick 推进,例如 TickDuration 为1秒,此时就一个延迟350秒的任务,那就是有349次无用的操作。
但是从另一面来看,如果任务都执行很快(当然你也可以异步执行),并且任务数很多,通过分批执行,并且增删任务的时间复杂度都是O(1)来说。时间轮还是比通过优先队列实现的延时任务来的合适些。
Kafka 中的时间轮
上面我们说到 Kafka 中的时间轮是多层次时间轮实现,总的而言实现和上述说的思路一致。不过细节有些不同,并且做了点优化。
先看看添加任务的方法。在添加的时候就设置任务执行的绝对时间。

那么时间轮是如何推动的呢?Netty 中是通过固定的时间间隔扫描,时候未到就等待来进行时间轮的推动。上面我们分析到这样会有空推进的情况。
而 Kafka 就利用了空间换时间的思想,通过 DelayQueue,来保存每个槽,通过每个槽的过期时间排序。这样拥有最早需要执行任务的槽会有优先获取。如果时候未到,那么 delayQueue.poll 就会阻塞着,这样就不会有空推进的情况发送。
我们来看下推进的方法。

从上面的 add 方法我们知道每次对比都是根据expiration < currentTime + interval 来进行对比的,而advanceClock 就是用来推进更新 currentTime 的。
小结一下
Kafka 用了多层次时间轮来实现,并且是按需创建时间轮,采用任务的绝对时间来判断延期,并且对于每个槽(槽内存放的也是任务的双向链表)都会维护一个过期时间,利用 DelayQueue 来对每个槽的过期时间排序,来进行时间的推进,防止空推进的存在。
每次推进都会更新 currentTime 为当前时间戳,当然做了点微调使得 currentTime 是 tickMs 的整数倍。并且每次推进都会把能降级的任务重新插入降级。
可以看到这里的 DelayQueue 的元素是每个槽,而不是任务,因此数量就少很多了,这应该是权衡了对于槽操作的延时队列的时间复杂度与空推进的影响。
总结
首先介绍了 Timer、DelayQueue 和 ScheduledThreadPool,它们都是基于优先队列实现的,O(logn) 的时间复杂度在任务数多的情况下频繁的入队出队对性能来说有损耗。因此适合于任务数不多的情况。
Timer 是单线程的会有阻塞的风险,并且对异常没有做处理,一个任务出错 Timer 就挂了。而 ScheduledThreadPool 相比于 Timer 首先可以多线程来执行任务,并且线程池对异常做了处理,使得任务之间不会有影响。
并且 Timer 和 ScheduledThreadPool 可以周期性执行任务。而 DelayQueue 就是个具有优先级的阻塞队列。
对比而言时间轮更适合任务数很大的延时场景,它的任务插入和删除时间复杂度都为O(1)。对于延迟超过时间轮所能表示的范围有两种处理方式,一是通过增加一个字段-轮数,Netty 就是这样实现的。二是多层次时间轮,Kakfa 是这样实现的。
相比而言 Netty 的实现会有空推进的问题,而 Kafka 采用 DelayQueue 以槽为单位,利用空间换时间的思想解决了空推进的问题。
可以看出延迟任务的实现都不是很精确的,并且或多或少都会有阻塞的情况,即使你异步执行,线程不够的情况下还是会阻塞。
巨人的肩膀
《深入理解Kafka:核心设计与实践原理》
https://www.cnblogs.com/luozhiyun/p/12075326.html
推荐 👍 :Github 掘金计划:Github 上的一些优质项目搜罗
推荐 👍 :啪地一下,很快啊!
推荐 👍 :唠唠嗑!大学那会接私活赚了 3w+
推荐 👍 :我花了一周,总结了一份 Java 学习/面试自测指南!200+道 Java 最常见面试题!