
神经网络中的泛化总结
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


前言:本文系统地介绍了神经网络中的泛化的概念,以及影响神经网络泛化能力的三种因素,本文对于刚入门的读者理解神经网络会有很大的帮助。
每当我们训练自己的神经网络时,我们都需要处理称为神经网络泛化的事情。这实质上意味着我们的模型在从给定数据中学习并将学到的信息应用到其他地方方面有多好。
在训练神经网络时,会有一些数据供神经网络训练,并且会保留一些数据用于检查神经网络的性能。如果神经网络在它没有训练过的数据上表现良好,我们可以说它在给定的数据上泛化得很好。让我们通过一个例子来理解这一点。
假设我们正在训练一个神经网络,它应该告诉我们给定的图像是否有狗。假设我们有几张狗的图片,每只狗都属于某个品种,这些图片中总共有 12 个品种。我将保留 10 个品种的狗的所有图像用于训练,其余 2 个品种的图像暂时放在一边。

现在,在进入深度学习方面之前,让我们从人类的角度来看一下。让我们考虑一个一生从未见过狗的人(仅举个例子)。现在我们将向这个人展示 10 种狗,并告诉他们这些是狗。在此之后,如果我们向他们展示其他 2 个品种,他们是否能够分辨出它们也是狗?希望他们应该这样做,10 个品种应该足以理解和识别狗的独特特征。这种从某些数据中学习并将获得的知识正确应用于其他数据的概念称为泛化(generalization)。
回到深度学习,我们的目标是让神经网络尽可能有效地从给定数据中学习。如果我们成功地让神经网络理解其他 2 个品种也是狗,那么我们已经训练了一个非常通用的神经网络,它将在现实世界中表现得非常好。
这实际上说起来容易做起来难,训练一个通用的神经网络是深度学习从业者最令人沮丧的任务之一。这是因为神经网络中的一种称为过度拟合的现象。如果神经网络对 10 个品种的狗进行训练,并且拒绝将其他 2 个品种的狗归类为狗,那么这个神经网络在训练数据上就过拟合了。这意味着神经网络已经记住了这 10 种狗,并且只认为它们是狗。因此,它无法对狗的长相形成一个大致的了解。在训练神经网络时解决这个问题是我们将在本文中研究的内容。
现在我们实际上没有像品种这样的基础来划分所有数据的自由,相反,我们将简单地拆分所有数据。一部分数据,通常是较大的一部分(大约 80-90%),将用于训练模型,其余的将用于测试。我们的目标是确保测试数据上的性能与训练数据上的性能大致相同。我们使用损失和准确性等指标来衡量这种性能。
我们可以控制神经网络的某些方面以防止过度拟合。让我们一一浏览它们。首先是参数的数量。
参数数量
在神经网络中,参数的数量本质上就是权重的数量。这将与层数和每层中的神经元数量成正比。参数个数与过拟合的关系如下:参数越多,过拟合的机会越大。我会解释原因。
我们需要根据复杂性来定义我们的问题。一个非常复杂的数据集需要一个非常复杂的函数才能成功地理解和表示它。从数学上讲,我们可以将复杂性与非线性联系起来。让我们回忆一下神经网络公式。
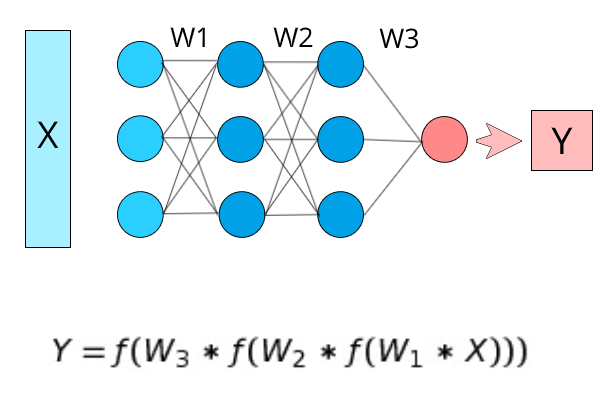
在这里,W1、W2 和 W3 是这个神经网络的权重矩阵。现在我们需要注意的是方程中应用于每一层的激活函数。由于这些激活函数,每一层都与下一层非线性连接。
第一层的输出是f(W_1*X)(假设是L1),第二层的输出是f(W_2*L1)。正如您在此处看到的,由于激活函数 (f),第二层的输出与第一层具有非线性关系。所以在神经网络的最后,根据神经网络的层数,最终值Y相对于输入X会有一定程度的非线性。
层数越多,破坏层间线性的激活函数的数量就越多,因此非线性越多。
由于这种关系,我们可以说,如果神经网络具有更多层和每层中的更多节点,它就会变得更加复杂。因此,我们需要根据数据的复杂性调整参数。除了反复试验和比较结果外,没有明确的方法可以做到这一点。
在给定的实验中,如果测试分数远低于训练分数,则模型过度拟合,这意味着神经网络对于给定数据有太多参数。这基本上意味着神经网络对于给定的数据来说太复杂了,需要简化。如果测试分数和训练分数差不多,那么模型已经泛化了,但这并不意味着我们已经达到了神经网络的最大潜力。如果我们增加参数,性能会提高,但也可能会过拟合。所以我们需要不断尝试通过平衡性能和泛化来优化参数的数量。
我们需要将神经网络的复杂性与数据复杂性相匹配。如果神经网络过于复杂,它会开始记忆训练数据,而不是对数据有一个大致的了解,从而导致过拟合。
通常深度学习从业者的做法是首先用足够多的参数训练一个神经网络,这样模型就会过拟合。所以最初我们试图得到一个非常适合训练数据的模型。接下来我们尝试迭代地减少参数的数量,直到模型停止过拟合,这可以被认为是一个最优的神经网络。我们可以用来防止过度拟合的另一种技术是使用 dropout 神经元。
丢弃神经元
在神经网络中,添加 dropout 是减少神经网络过度拟合的最流行和最有效的方法之一。在 dropout 中发生的事情是,本质上网络中的每个神经元都有一定的概率从网络中完全退出。这意味着在特定时刻,将有某些神经元不会连接到网络中的任何其他神经元。这是一个视觉示例:
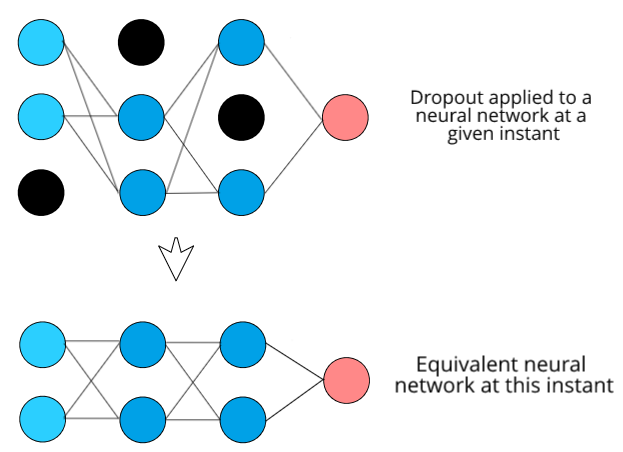
在训练过程中的每个时刻,都会以随机方式丢弃一组不同的神经元。因此我们可以说,在每个时刻,我们都在有效地训练某个神经网络子集,它的神经元比原始神经网络少。由于 dropout 神经元的随机性,这个子集神经网络每次都会发生变化。
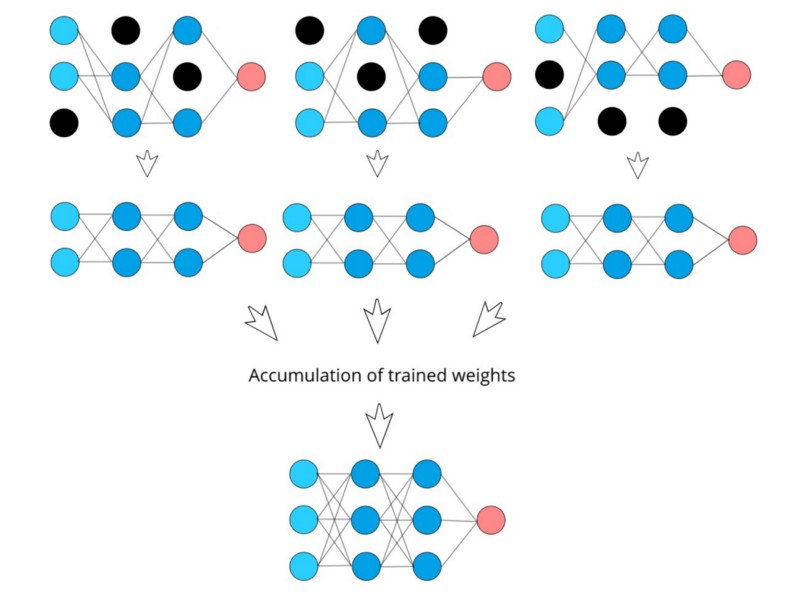
这里基本上发生的是,当我们训练一个带有 dropout 神经元的神经网络时,我们基本上是在训练许多较小的子集神经网络,并且由于权重是原始神经网络的一部分,因此神经网络的最终权重可以被视为 所有相应子集神经网络权重的平均值。这是正在发生的事情的基本可视化:
这就是 dropout 神经元在神经网络中的工作方式,但为什么 dropout 可以防止过拟合?这有两个主要原因:
第一个原因是辍学神经元促进了神经元的独立性。由于特定神经元周围的神经元在某个时刻可能存在也可能不存在,因此该神经元不能依赖于围绕它的那些神经元。因此,它将被迫在训练时更加独立。
第二个原因是因为 dropout,我们实际上是在一次训练多个较小的神经网络。一般来说,如果我们训练多个模型并平均它们的权重,由于每个神经网络独立学习的积累,性能通常会提高,但是这是一个昂贵的过程,因为我们需要定义多个神经网络并单独训练它们。然而,在 dropout 的情况下,这会做同样的事情,而我们只需要一个神经网络,我们就可以从中训练多个可能的子集神经网络配置。
训练多个神经网络并聚合它们的学习被称为“集成”,通常会提高性能。使用 dropout 基本上可以做到这一点,而只有 1 个神经网络。
减少过度拟合的下一个技术是权重正则化(weight regularization)。
权重正则化
在训练神经网络时,某些权重的值有可能变得非常大。发生这种情况是因为这些权重专注于训练数据中的某些特征,这导致它们在整个训练过程中不断增加价值。因此,网络在训练数据上过度拟合。
我们不需要不断增加权重来捕捉某种模式,相反,如果它们的值相对于其他权重更高,那也没关系。但是在训练过程中,当神经网络通过多次迭代对数据进行训练时,权重有可能不断增加,直到变得很大,这是不必要的。
巨大的权重对神经网络不利的另一个原因是输入输出方差增加。基本上当网络中有一个巨大的权重时,它很容易受到输入的微小变化的影响,但是神经网络对于相似的输入应该输出相同的东西。当我们拥有巨大的权重时,即使我们保留两个非常相似的独立数据输入,输出也有可能大不相同。这会导致在测试数据上出现许多不正确的预测,从而降低了神经网络的泛化能力。
神经网络中权重的一般规则是,神经网络中的权重越高,神经网络就越复杂。因此,具有较高权重的神经网络通常会过度拟合。
所以基本上我们需要限制权重的增长,这样它们就不会增长太多,但是我们到底要怎么做呢?神经网络尝试在训练时最小化损失,因此我们可以尝试在该损失函数中包含一部分权重,以便在训练时也最小化权重,但当然首先要减少损失。
有两种方法可以做到这一点,它们称为 L1 和 L2 正则化。在 L1 中,我们取网络中所有权重绝对值总和的一小部分。在 L2 中,我们取网络中所有权重平方值之和的一小部分。我们只是将这个表达式添加到神经网络的整体损失函数中。方程式如下:
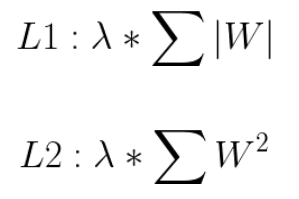
这里的 lambda 是一个允许我们改变权重变化程度的值。我们基本上只是将 L1 或 L2 项添加到神经网络的损失函数中,这样网络也会尝试最小化这些项。通过添加 L1 或 L2 正则化,网络将限制其权重的增长,因为权重的大小是损失函数的一部分,并且网络总是试图最小化损失函数。让我们重点介绍 L1 和 L2 之间的一些差异。
对于 L1 正则化,当权重由于正则化而减少时,L1 试图将其完全下推到零。因此,对神经网络贡献不大的不重要的权重最终会变为零。然而,在 L2 的情况下,由于平方函数对于小于 1 的值成反比,权重不会被推到零,而是被推到小值。因此,不重要的权重比其他权重的值低得多。
这涵盖了防止过度拟合的重要方法。在深度学习中,我们通常混合使用这些方法来提高神经网络的性能并提高模型的泛化能力。
原文链接:
https://medium.com/deep-learning-demystified/generalization-in-neural-networks-7765ee42ac23
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!