
Alluxio与CDH组件集成
一、运行 CDH MapReduce
1. 配置core-site.xml
您需要将以下属性添加到中core-site.xml。只有使用HA模式的群集才需要ZooKeeper属性。同样,只有使用嵌入式日志的HA群集才需要嵌入式日志属性。
<property>
<name>fs.alluxio.impl</name>
<value>alluxio.hadoop.FileSystem</value>
</property>
<property>
<name>alluxio.zookeeper.enabled</name>
<value>true</value>
</property>
<property>
<name>alluxio.zookeeper.address</name>
<value>zknode1:2181,zknode2:2181,zknode3:2181</value>
</property>
<property>
<name>alluxio.master.embedded.journal.addresses</name>
<value>alluxiomaster1:19200,alluxiomaster2:19200,alluxiomaster3:19200</value>
</property>
要将配置属性添加到core-site.xmlCloudera Manager中,请在Cloudera Manager中选择“ HDFS”组件,选择“配置”,然后搜索“ core-site.xml的群集范围内的高级配置代码段(安全阀)”。可以对其进行修改以添加所需的属性。请参考下图。
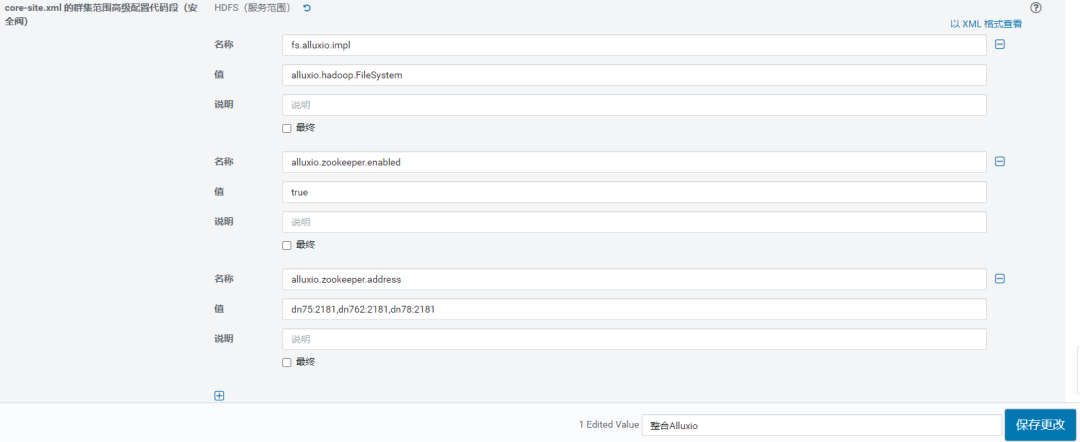
然后,保存配置,Cloudera Manager会通知您应该部署配置并重新启动受影响的组件。接受这些选项以继续。
2. 配置HADOOP_CLASSPATH
为了使Alluxio客户端jar可用于MapReduce应用程序,必须将Alluxio Hadoop客户端jar添加到中的$HADOOP_CLASSPATH环境变量hadoop-env.sh。
在Cloudera Manager的“ YARN(包括MR2)”部分的“配置”选项卡中,搜索参数“ hadoop-env.sh的网关客户端环境高级配置代码段(安全阀)”。然后将以下行添加到脚本中:
HADOOP_CLASSPATH=/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar:${HADOOP_CLASSPATH}
它看起来应该像这样:

保存配置后,Cloudera Manager将通知您需要重新部署陈旧的配置文件,并且需要重新启动受影响的组件。确保接受两个选项并重新启动服务。如果将Alluxio与HDFS日记一起使用,请确保在重新启动HDFS之前停止Alluxio。
在客户端配置环境变量:
[hadoop@dn75 ~]$ vim .bashrc
# set alluxio env
export ALLUXIO_HOME=/home/hadoop/app/alluxio
export PATH=$PATH:$ALLUXIO_HOME/bin
export HADOOP_CLASSPATH=/home/hadoop/app/alluxio/client/alluxio-2.4.1-1-client.jar:${HADOOP_CLASSPATH}
3. 安全
由于MapReduce在YARN上运行,因此需要配置非安全的Alluxio,以允许yarn用户模拟其他用户。为此,将以下属性添加到alluxio-site.propertiesAlluxio Masters和Workers上,然后重新启动Alluxio群集。
alluxio.master.security.impersonation.yarn.users=*
如果对Alluxio和YARN进行了kerberized和Secured,则不需要这样做。
4. 运行MapReduce应用程序
为了使MapReduce应用程序能够在Alluxio中读取和写入文件,必须将Alluxio客户端jar分发到群集中的所有YARN节点,并将其添加到应用程序类路径中。
以下是分发客户端jar的2种主要替代方法的说明。
4.1 使用-libjars命令行选项
-libjars在yarn jar ...将/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar用作参数时, 可以使用命令行选项来运行作业。这会将jar放置在Hadoop DistributedCache中,使其可用于所有节点。例如,以下命令将Alluxio客户端jar添加到该-libjars选项:
$ yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar randomtextwriter -libjars /path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar <OUTPUT URI>
4.2 设置类路径配置变量
如果Alluxio客户端jar已分发到同一路径中的所有节点,则可以使用mapreduce.application.classpath变量将该jar添加到类路径。
在Cloudera Manager中,您可以mapreduce.application.classpath在“配置”选项卡的“ YARN(包括MR2)”组件中找到变量。对于“ MR应用程序类路径”,将Alluxio Hadoop客户端jar添加为新条目。
/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar
这将添加到mapreduce.application.classpath参数中。它看起来应该像这样:
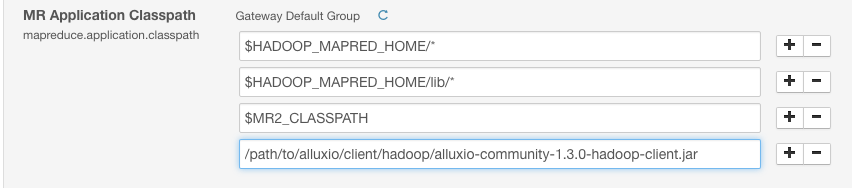
保存配置后,重新启动受影响的组件。
alluxio client jar及其所有父目录必须要有755权限,才能读到
5. 运行示例MapReduce应用程序
[hadoop@dn75 ~]$ hadoop jar /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-examples-3.0.0-cdh6.3.4.jar wordcount \
-libjars /opt/alluxio/client/alluxio-enterprise-2.5.0-1.1-client.jar \
alluxio:///wordcount/input.txt \
alluxio:///wordcount/output
二、运行CDH Spark
要与Alluxio一起运行CDH Spark应用程序,需要对应用程序进行其他配置。
Spark和Alluxio部署有两种方案。如果您已经在群集的所有节点上安装了Alluxio Spark客户端jar,则只需为类路径指定正确的路径即可。否则,您可以允许Spark为应用程序的每次调用将Alluxio Spark客户端jar分发到每个Spark节点。
1. 每个节点上已经有Alluxio Spark客户端jar
如果Alluxio客户端jar已存在于每个节点上,则必须将该路径添加到Spark驱动程序和执行程序的类路径中。为此,请使用spark.driver.extraClassPath或--driver-java-options 和spark.executor.extraClassPath变量。
注意:如果设置多次
spark.executor.extraClassPath,spark.driver.extraClassPath将覆盖。如果应用程序已经设置了此参数,则需要将Alluxio客户端jar添加到设置此属性的位置。
对于spark-submit一个例子如下所示。(在示例中,替换MASTER_HOSTNAME为实际的Alluxio主主机名。)
$ spark-submit --master yarn --conf "spark.driver.extraClassPath=/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar" --conf "spark.executor.extraClassPath=/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar" --class org.apache.spark.examples.JavaWordCount /opt/cloudera/parcels/CDH/lib/spark/examples-1.6.0-cdh5.14.4-hadoop2.6.0-cdh5.14.4.jar alluxio://MASTER_HOSTNAME:19998/testing/randomtext/
注意:此示例将对Alluxio path下的所有文本文件运行字数统计
/testing/randomtext/。
同样,对于spark-shell,下面是一个示例:
$ spark-shell --master yarn --driver-class-path "/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar" --conf "spark.executor.extraClassPath=/path/to/alluxio/client/alluxio-enterprise-2.4.1-1.1-client.jar"
2. 为每个应用程序分配Alluxio Spark客户端jar
如果尚未在每台计算机上安装Alluxio客户端jar,则可以使用该--jars选项为每个应用程序分发jar。
例如,使用spark-submit看起来像:
$ spark-submit --master yarn --jars /path/to/alluxio/spark/alluxio-enterprise-2.4.1-1.1-client.jar ...
3. CDH界面配置Alluxio Spark客户端jar
将 Alluxio 客户端 jar 包添加到 Spark driver 和 executor 的 classpath 中,以便 Spark 应用程序能够使用客户端 jar 包在 Alluxio 中读取和写入文件。具体来说,在运行 Spark 的每个节点上,将以下几行添加到spark/conf/spark-defaults.conf中。
spark.driver.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.5.0-client.jar
spark.executor.extraClassPath /<PATH_TO_ALLUXIO>/client/alluxio-2.5.0-client.jar
