导语 | Redis 大家用的不少,但是我们大多数人可能都只是关注业务本身,对于底层的细节则经常忽略,久而久之,对个人的成长帮助甚少。本文为大家总结了关于 Redis 常见用法的进阶指南,希望帮助大家加深对这门技术的理解。文章作者:何永康,腾讯 CSIG 后台研发工程师。
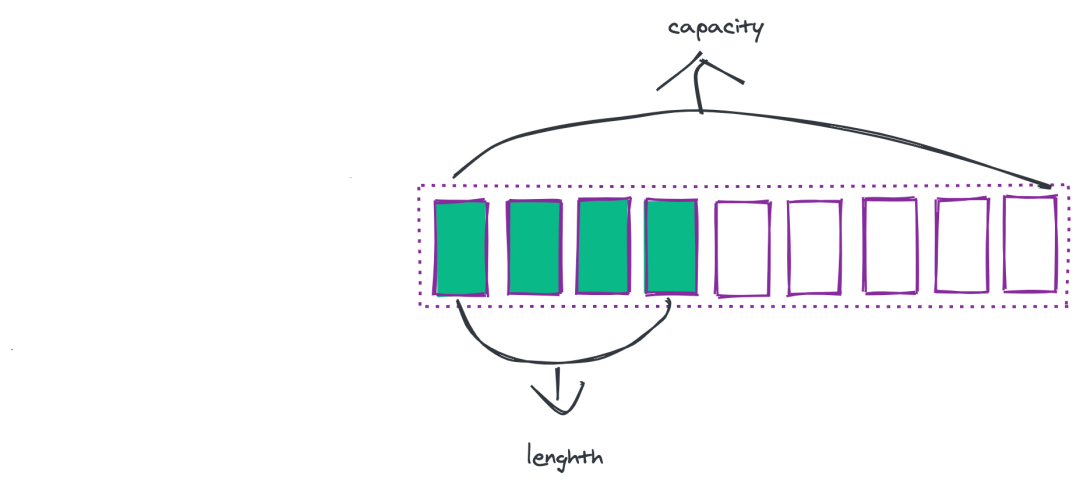
Redis 里的字符串是动态字符串,会根据实际情况动态调整。类似于 Go 里面的切片-slice,如果长度不够则自动扩容。至于如何扩容,方法大致如下:当 length 小于 1M 的时候,扩容规则将目前的字符串翻倍;如果 length 大于 1M 的话,则每次只会扩容 1M,直到达到 512M。
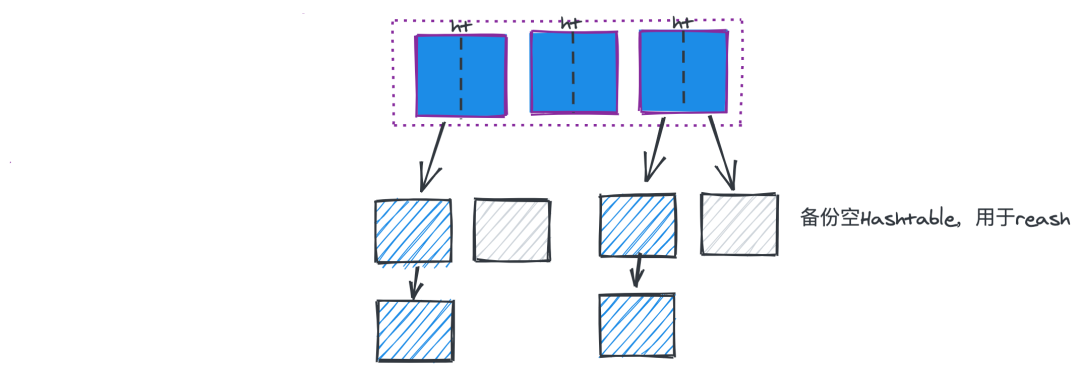
Redis 里的 List 是一个链表,由于链表本身插入和删除比较块,但是查询的效率比较低,所以常常被用做异步队列。Redis 里的 List 设计非常牛,当数据量比较小的时候,数据结构是压缩链表,而当数据量比较多的时候就成为了快速链表。可运用的场景:在业务中异步队列使用 rpush/lpush 操作队列,使用 lpop 和 rpop 出队列,具体结构如下图所示:Redis 中的 set 是一个无序 Map,由于 Go 中没有 set 结构,所以这里只能类比 Java 中的 HashSet 概念。Redis 的 set 底层也是一个 Map 结构,不同于 Java 的是:alue 是一个 NULL。由于 set 的特性,它可以用于去重逻辑,这一点在 Java 中也经常使用。Redis 中的字典类型大家不陌生,也许其他语言都有这种结构(python,Java,Go), hash 的扩容 rehash 过程和 Go 里面的设计颇有类似,也就是维护了两个 hash 结构,如果需要扩容的时候,就把新的数据写入新字典中,然后后端起一个线程来逐步迁移,总体上来说就是采用了空间换时间的思想。可运用场景:记录业务中的不同用户/不同商品/不同场景的信息:如某个用户的名称,或者用户的历史行为。
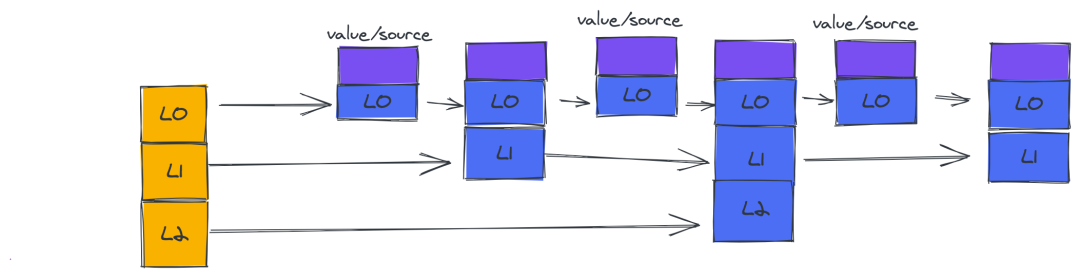
Redis 中的 zset 是一个比较特殊的数据结构(跳跃列表),也就是我们了解到的跳表,底层由于 set 的特性保证了 value 唯一,同时也给了 value 一个得分,所谓的有序其实就是根据这个得分来排序。至于跳跃表如何插入,其实内部采用了一个随机策略:L0:100%-L2:50%-L3:25%-....Ln:(n-1)value/2%。
1. 布隆过滤器
Redis 在 4.0 以后支持布隆过滤(准确的来说是支持了布隆过滤器的插件),给 Redis 提供了强大的去重功能。在业务中,我们可能需要查询数据库判断历史数据是否存在,如果数据库的并发能力有限,这个时候我们可以采用 Redis 的 set 做去重。如果缓存的数据过大,这个时候就需要遍历所有缓存数据,另外如果我们的历史数据缓存写不下了,终究要去查询数据库,这个时候就可以使用布隆过滤器。当然布隆过滤器精确度不是 100% 准确(如果对数据准确度要求很高的话,这里不建议使用),因为对于存在的数据也许这个值不一定存在,当然如果不存在,那肯定 100% 不存在了。(1)命令使用
bf.add #添加元素bf.exists #判断元素是否存在bf.madd #批量添加bf.mexists #批量判断是否存在
(2)原理
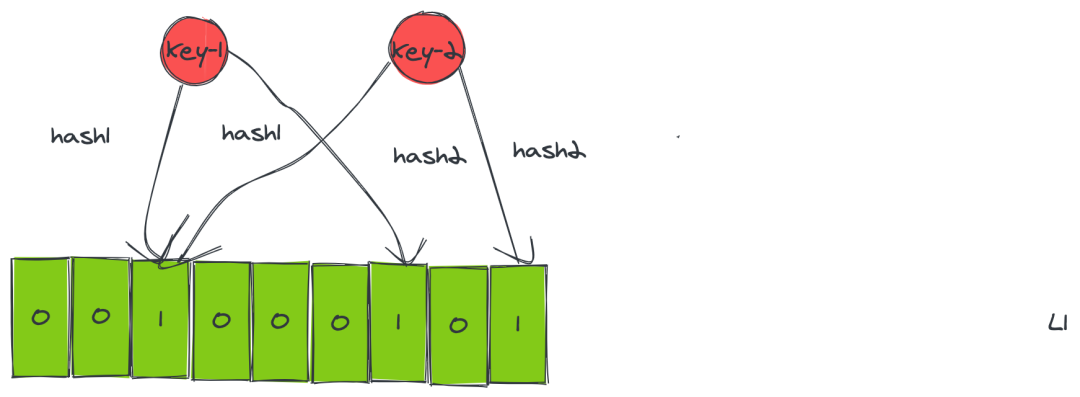
布隆过滤的组成可以当作一个位数组和几个计算结果比较均匀的 hash 函数,每次添加 key 的时候,会把 key 通过多次 hash 来计算所得到的位置,如果当前位置不是 0 则表示存在。可以看到,这样的计算存在一定误差,这也正是它的不准确性问题的由来。
2. 分布式锁
大家对分布式锁也许也不会陌生,现在市面上主流的实现分布锁的技术有 ZK 和 Redis;下文为大家简单介绍一下 Redis 如何实现分布式锁。命令
setnx lock:mutex ture del lock:mutex
实现分布式锁的核心就是:请求的时候 Set 这个 key,如果其他请求设置失败的时候,即拿不到锁。但是存在一个问题:如果业务 panic 或者忘记调用 del 的话,就会产生死锁,这个时候大家很容易能想到:我们可以 expire 一个过期时间,这样就可以保证请求不会一直独占锁且无法释放锁的逻辑了。但是假设业务存在这样一种情况:A 请求在获取锁后处理逻辑,由于逻辑过长,这个时候锁到期释放了,A 这个时候刚刚处理完成,而 B 又去改了这个数据,这就存在一个锁失效的问题。解决这种问题参考 CAS 的方式,对锁设置一个随机数,可以理解为版本号,如果释放的时候版本号不一致,则表示数字已经在释放那一刻改掉了。
1. IO模型
Redis 是单线程模型(这里的单线程指的是 IO 和键值对的读写是一个线程完成的),当然如果严谨的来说还是可以理解为是多线程,不过这样的多线程不过是在数据备份的时候会 fork 一个子进程对数据进行从磁盘读取数据并组装 RDB,然后同步给 slaver 节点的操作,当然包括备份和持久化也都是通过另外起线程完成的,所以我们可以把 Redis 认作为一个单线程模型。那么问题来了,为什么单线程的模型能这么快?原因很简单,因为 Redis 本身就是在内存中运算,而对于上游的客户端请求,采用了多路复用的原理。Redis 会给每一个客户端套接字都关联一个指令队列,客户端的指令队列通过队列排队来进行顺序处理,同时 Reids 给每一个客户端的套件字关联一个响应队列,Redis 服务器通过响应队列来将指令的接口返回给客户端。
Redis IO 处理模型
2. 通信协议
Redis 采用了 Gossip 协议作为通信协议。Gossip 是一种传播消息的方式,可以类比为瘟疫或者流感的传播方式,使用 Gossip 协议的有:Redis Cluster、Consul、Apache Cassandra 等。Gossip 协议类似病毒扩散的方式,将信息传播到其他的节点,这种协议效率很高,只需要广播到附近节点,然后被广播的节点继续做同样的操作即可。当然这种协议也有一个弊端就是:会存在浪费,哪怕一个节点之前被通知到了,下次被广播后仍然会重复转发。
3. 持久化
(1)RDB
RDB 是对当前 Redis 的存储数据进行一次快照(具体原理和如何做,限于篇幅这里不做过多复述了)。
(2)AOF
日志只记录 Redis 对内存修改的指令记录,Redis 提供了一个 bgrewriteaif 的指令对 AOF 进行压缩。原理就是:开辟一个子进程对内存进行遍历后,转换成一系列对 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。系列化完成后再将发送的增量 AOF 日志追加到这个新的 AOF 日志中,追加完成后用新的 AOF 日志代替旧的。(3)混合持久化
由于单纯 RDB 的话,可能存在数据的丢失,而频繁的 AOF 又会影响了性能,在 Redis 4.0 之后,支持了混合持久化,也就是每次启动时候通过 RDB+增量的 AOF 文件来进行回复,由于增量的 AOF 仅记录了开始持久化到持久化结束期间发生的增量,这样日志不会太大,性能相对较高。4. 主从同步
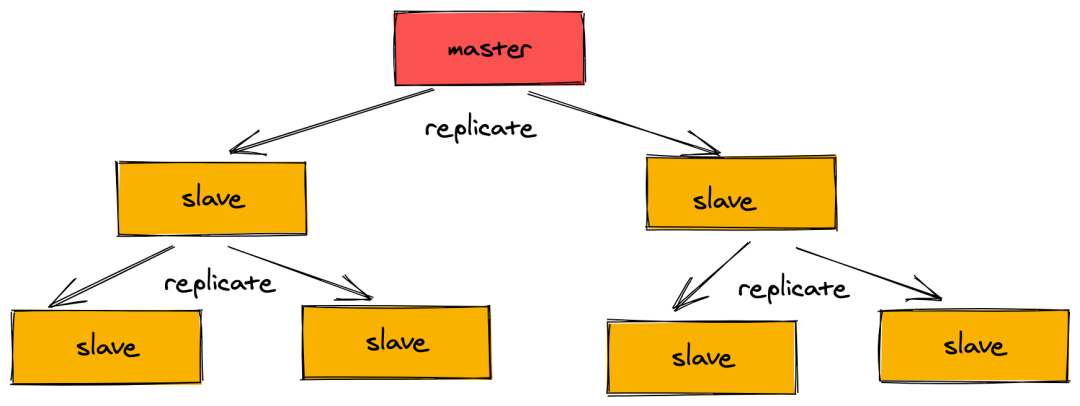
Redis 的同步方式有:主从同步、从从同步(由于全部都由 master 同步的话,会损耗性能,所以部分的 slave 会通过 slave 之间进行同步)。同步过程:
- 建立连接,然后从库告诉主库:“我要同步啦,你给我准备好”,然后主库跟从库说:“收到”。
- 从库拿到数据后,要把数据保存到库里。这个时候就会在本地完成数据的加载,会用到 RDB 。
主库把新来的数据 AOF 同步给从库。
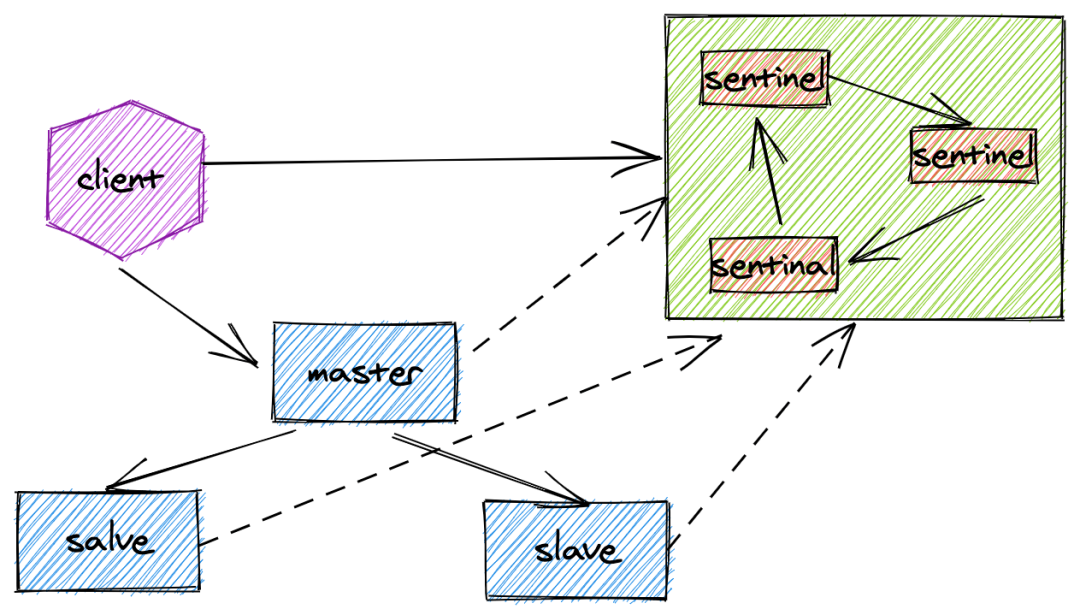
5. Sentinel
Redis 的主从切换是通过哨兵来解决的。这里哨兵主要解决的问题就是:当 master 挂了的情况下,如果在短时间内重新选举出一个新的 master 。Sentinel 集群是一个由 3-5 个(可以更多)节点组成的,用来监听整个 Redis 的集群,如果发现 master 不可用的时候,会关闭和断开全部的与 master 相连的旧链接。这个时候 Sentinel 会完成选举和故障转移,新的请求则会转到新到 master 中。6. Redis集群工作原理
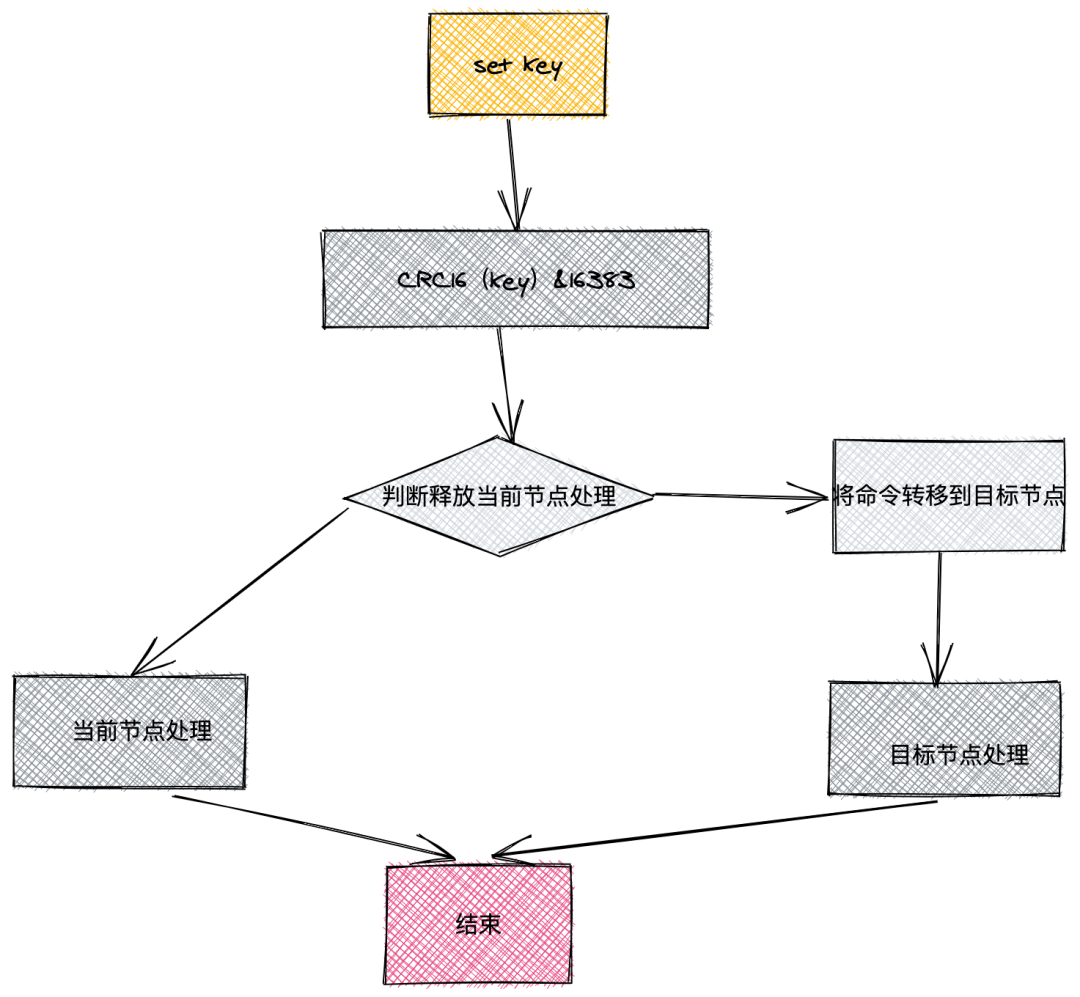
Redis 集群通过槽指派机制来决定写命令应该被分配到那个节点。整个集群对应的槽是由 16384 大小的二进制数组组成,集群中每个主节点分配一部分槽,每条写命令落到二进制数组中的某个位置,该位置被分配给了哪个节点,则对应的命令就由该节点去执行。槽指派对应的二进制数组如下图所示:从上图可以看到:节点 1 只负责 执行 0 - 4999 的槽位,而节点 2 负责执行 5000 - 9999,节点 3 执行 9999- 16383 。当进行写的时候:命令通过 CRC16(key) & 16383 = 6789(假设结果),由于节点 2 负责 5000~9999 的槽位,则该命令的结果 6789 最终由节点 2 执行。当然如果在节点 2 执行一条命令时,假设通过 CRC 计算后得到的值为 567,则其应该由节点 1 执行,此时命令会进行转向操作,将要执行的命令流转到节点 1 上去执行。
集群中每个主节点都会定时发送信息到其他主节点进行同步,如果其他主节点在规定时间内响应了发送消息的主节点,则发送消息的主节点认为响应了消息的主节点正常,反之则认为响应消息的主节点疑似下线,则发送消息的主节点在其节点上将其标记“疑似下线”。当集群中超过一半以上的节点认为某个主节点被标记为“疑似下线”,则其中某个主节点将疑似下线节点标记为下线状态,并向集群广播一条下线消息,当下线节点对应的从节点接收到该消息时,则从从节点中选举出一个节点作为主节点继续对外提供服务。
业务场景中,不知道大家是否碰到过 Redis 变慢的情况:
原因分析
查看慢查询,由于笔者本身机器没有慢查询,所以这里看到是空(实在尴尬,这里没有可用的例子~~)
默认会监听 6379 端口,最好在 Redis 的配置文件中指定监听的 IP 地址,更进一步还可以增加 Redis 的 ACL 访问控制,对客户指定群组,并限限制用户对数据的读写权限。
访问 Redis 尽量走公司代理,由于 Redis 本身不支持 SSL 的链接,所以走公司代理可以保证安全。客户端登陆 Redis 必须设置 Auth 秘密登陆。