
【Redis —进阶】缓存设计
作者:与昊
来源:SegmentFault 思否社区
缓存的收益和成本
收益
加速读写:因为缓存通常都是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载。
成本
数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
开销大的复杂计算:以MySQL为例,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
加速请求响应:即使查询单条后端数据足够快,那么依然可以使用缓存,以Redis为例,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间。
缓存更新策略
LRU/LFU/FIFO算法剔除
超时剔除
主动更新
最佳实践
缓存粒度控制
全部数据会造成内存的浪费。
全部数据可能每次传输产生的网络流量会比较大,耗时相对较大,在极端情况下会阻塞网络。
全部数据的序列化和反序列化的CPU开销更大。
缓存穿透
缓存空对象
空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
布隆过滤器拦截
缓存空对象和布隆过滤器方案对比

缓存无底洞
客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随着节点的增多,耗时会不断增大。 网络连接数变多,对节点的性能也有一定影响。
命令本身的优化,例如优化SQL语句等。
减少网络通信次数。
降低接入成本,例如客户端使用长连/连接池、NIO等。
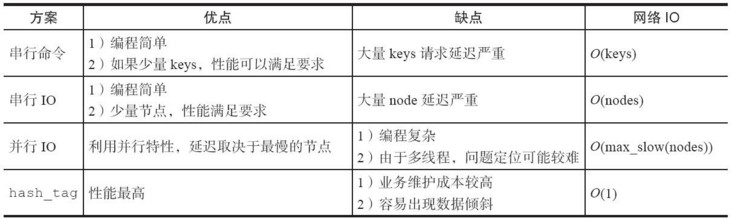
串行命令
现起来比较简单。
串行IO
并行IO
hash_tag实现
方案对比
缓存雪崩
保证缓存层服务高可用性
依赖隔离组件为后端限流并降级
提前演练
热点key重建
当前key是一个热点key,并发量非常大。 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
减少重建缓存的次数。 数据尽可能一致。 较少的潜在危险。
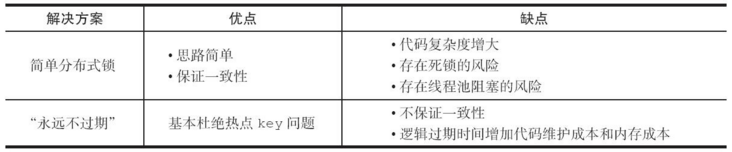
互斥锁
永远不过期
从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。 从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,会使用单独的线程去构建缓存。
总结

评论