
「狗」生万物?以色列团队提出零样本训练模型,狗狗秒变尼古拉斯·凯奇

新智元报道
新智元报道
来源:arXiv
编辑:Priscilla 好困
【新智元导读】特拉维夫大学和英伟达研究团队利用CLIP模型的语义能力,提出了一种文本驱动的方法:StyleGAN-NADA,无需在新的领域收集图像,只要有文本提示就能极速生成特定领域图像。



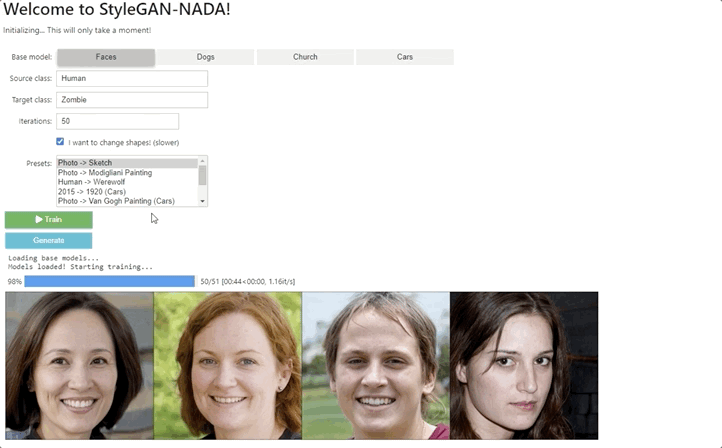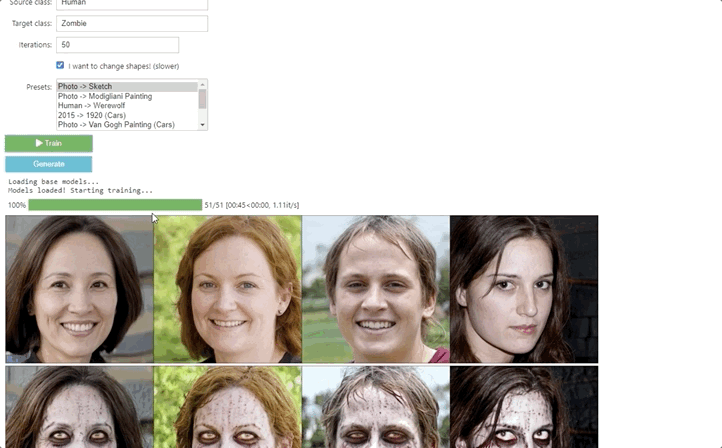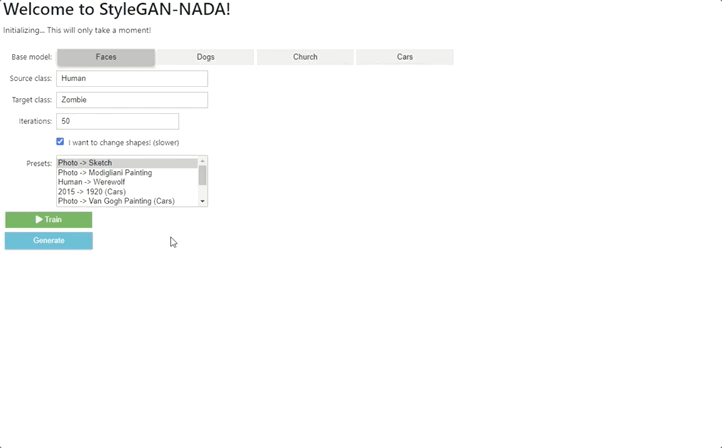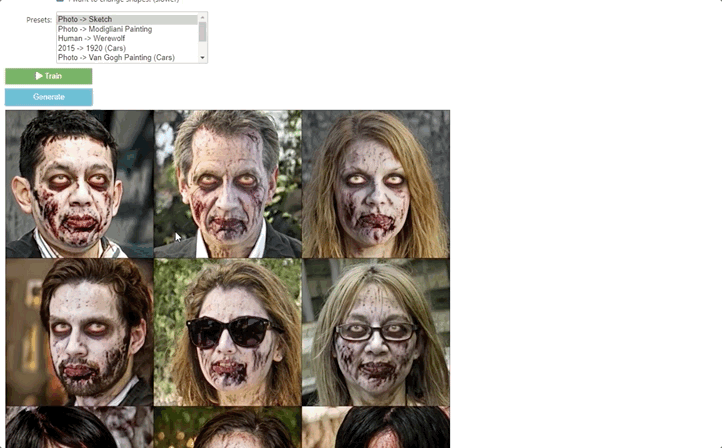
方法实现
方法实现
网络结构概述
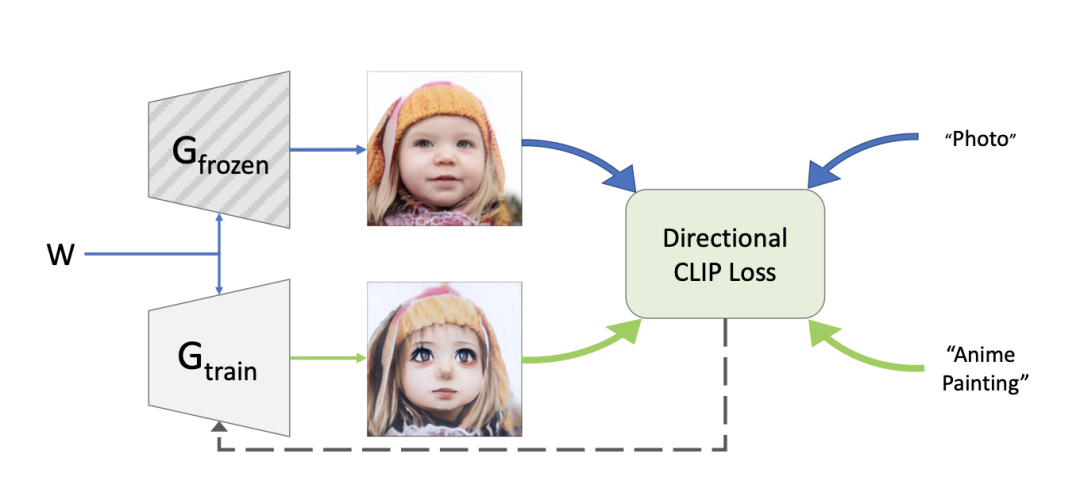
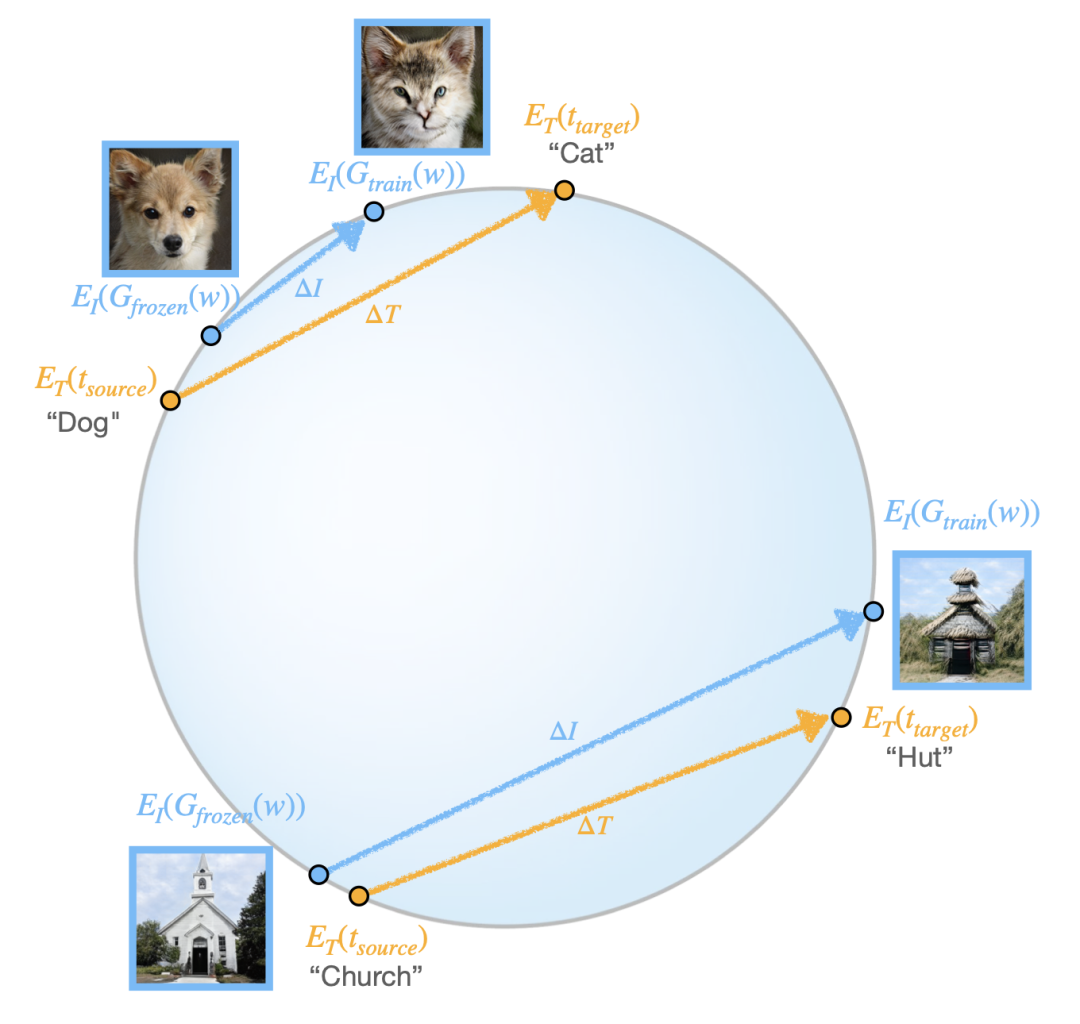
基于CLIP的指导
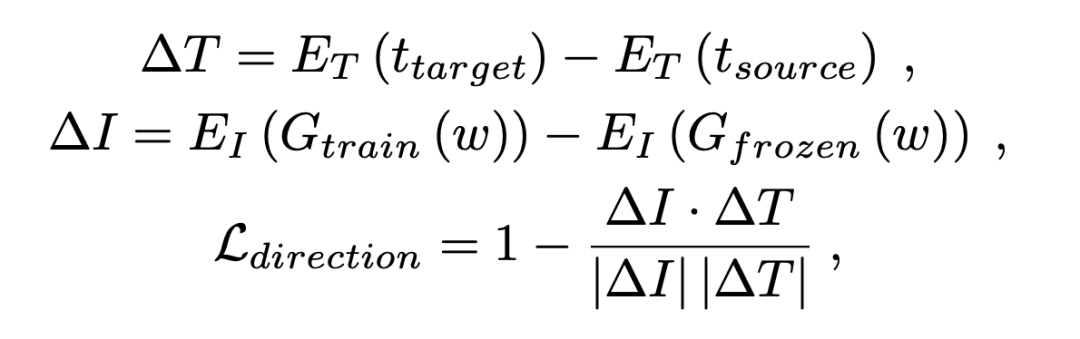
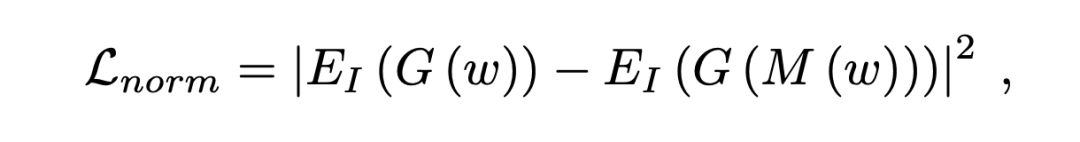
实验结果
实验结果




参考资料:
https://arxiv.org/abs/2108.00946

评论