本文约2700字,建议阅读15分钟
本文介绍了李飞飞团队的最新研究发现。
走在队伍前面的,是来自斯坦福大学的博士,李飞飞的门生!先来看看李飞飞团队这次在arXiv上发表了的论文题目:强化学习中的泛化(generalization),是指通过不断跟环境交互,产生出一种网络的记忆性。这个网络能够根据环境中特定的信号完成相应的动作,经过训练的agent能够记住在什么状态下要做什么,还能通过识别状态的细微差别来采取不同的动作。再通俗一点,就是在未见过的测试数据上也能够进行预测。因此,提升模型的泛化是机器学习领域中的一个重要研究。特别是视觉强化学习方面,泛化很容易被高维观察空间中,一些无关痛痒的因素分散了注意力。针对这个问题,团队通过鲁棒性策略学习,对具有大分布偏移的未见视觉环境进行零样本泛化。因此,团队提出「SECANT」模型,一种可以适应新测试环境的自专家克隆方法(Self Expert Cloning for Adaptation to Novel Test-environments)。这个方法能够在两个阶段利用图像增广,分离鲁棒性表征和策略优化。首先,专家策略通过弱增广从头开始进行强化学习的训练。而学生网络就是通过强增广的监督学习来模仿专家策略,其表征与专家策略相比,对视觉变化更具鲁棒性。实验表明,SECANT在DMControl(Deepmind Control)、自动驾驶、机器人操作和室内物体导航这四个具有挑战性的领域中,在零样本泛化方面超过了之前的SOTA模型,分别实现了26.5%、337.8%、47.7%和15.8%的提升。提出了SECANT模型,可以依次解决策略学习和鲁棒性表征学习问题,从而实现了对未见过的视觉环境的强大零样本泛化性能。
在自动驾驶、机器人操作和室内物体导航四个领域中,设计并制定了一套多样化的基准测试。除了DMControl外,其它3种环境都具有代表实际应用程序的测试时视觉外观漂移。
证明了SECANT在以上4个领域中,大多数任务都能达到SOTA。
SECANT框架
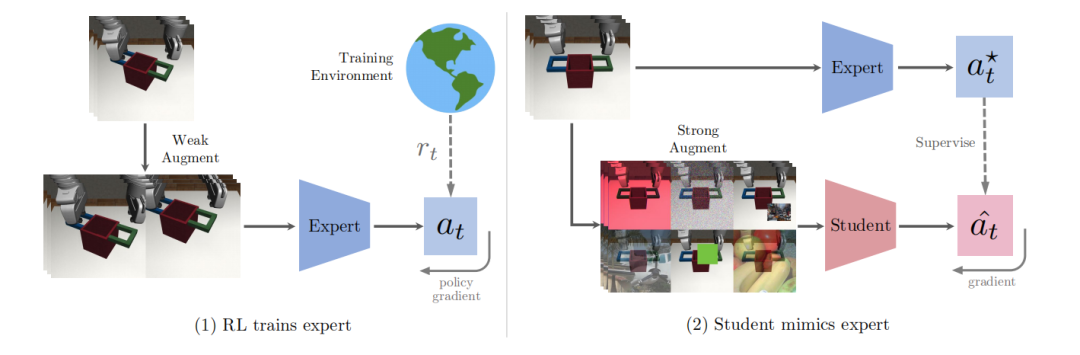
SECANT的主要目标是发展自我专家克隆技术,通过这种技术可以实现零样本生成不一样的视觉样本。
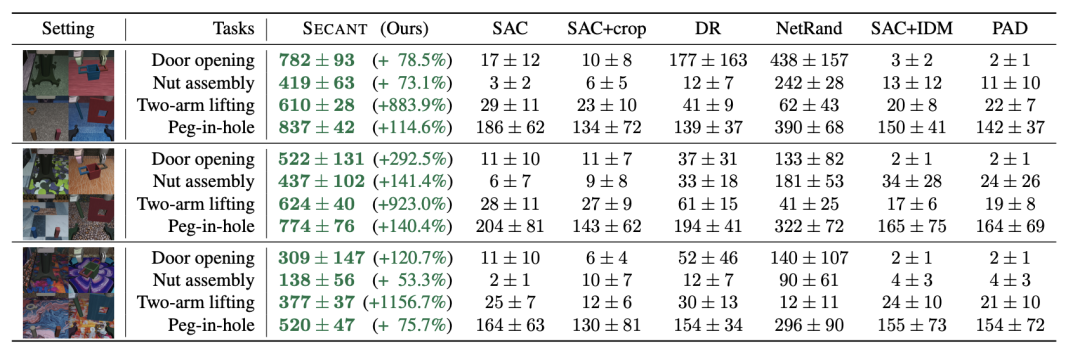
作者研究的SECANT训练模型可以分解为两步,代码已公开。
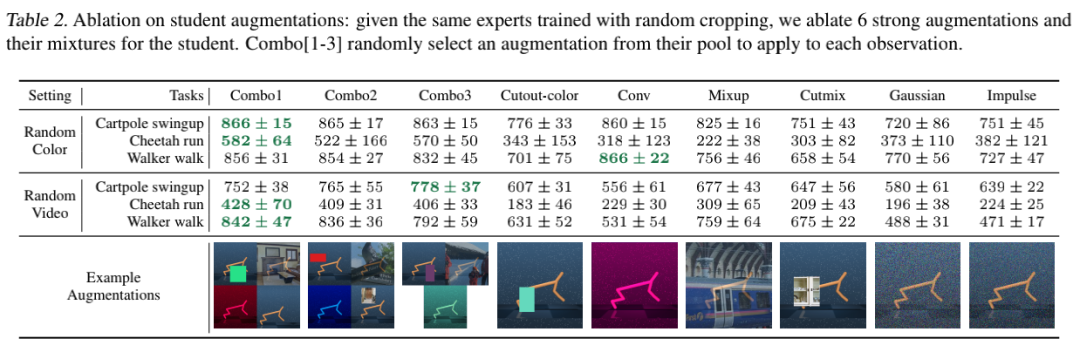
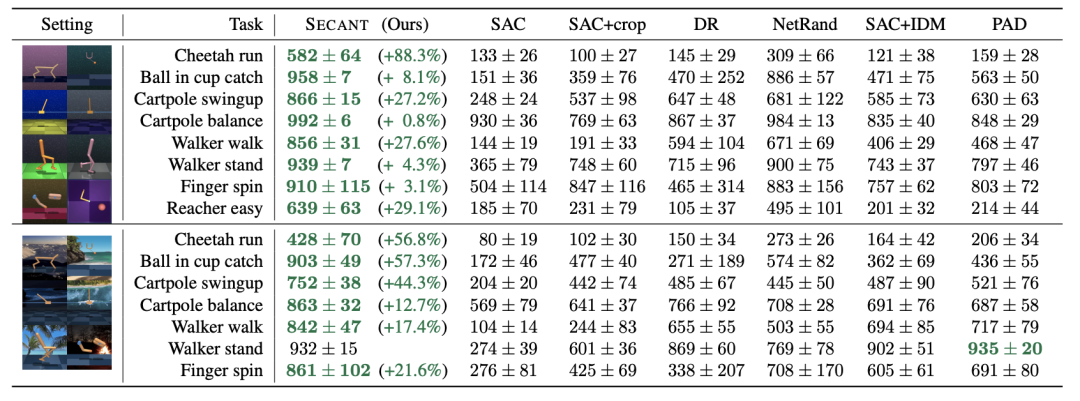
第一步,作者在原始环境中通过弱增广训练了一套高性能的专家策略。在视觉连续控制任务中,这套策略通过前馈深度卷积网络进行参数化,然后将观察到的图像转化为d维连续动作向量。在实际应用中,作者采用了帧叠加技术,在时间信息维度上,连接T个连续图像进行观测。然后通过语义保持图像变换来生成数据扩增的算子。采用随机裁剪图像的方法作为默认的弱增广方法来训练专家策略。这套专家策略可以通过任何标准的RL算法进行优化。作者选择了Soft Actor-Critic (SAC),因为它在连续控制任务中被广泛采用。然后采用梯度下降法对专家参数进行优化,使专家参数最小化。在第二阶段,作者训练一个学生网络来预测专家策略采取的最优行动,在同样的观察的条件下,通过剧烈变化的图像来进行测试。在这个阶段不需要进一步接触奖励信号。从形式上来看,学生策略也是一个深度卷积神经网络,但与专家策略不同的是它有着不同的架构。本质上来说,学生策略是根据DAgger模仿流程,从专家策略中延伸而来的。作者使用专家策略来收集轨迹的初始数据集D。接下来,在每一次迭代中,选择一个强扩增算子,并将其应用于采样的一批观测数据。作者通过将原有视觉元素进行插入色块(Cc)、随机卷积(Cv)、补充高斯噪声(G)以及添线性混合(M)等方式来生成不同的视觉样本。作者还研究了以上的组合,并试图发现从低频和高频结构噪声中的随机抽样产生最佳的总体结果。作者注意到,在混合中添加随机裁剪略微有利于性能的提升,可能是因为它改善了学生策略表征的空间不变性。四种不同场景的视觉策略泛化基准测试(从上至下):DMControl Suite、CARLA、Robosuite和iGibson首先,作者提出了一个适用于四种不同领域的基准测试,系统地评估视觉agent的泛化能力。在每个领域中,团队研究了在一个环境中训练的算法,在零样本设置中的各种未见环境中的表现如何。此时没有奖励信号和额外的试验。在每个任务中,SECANT以之前的SOTA算法为基准:SAC、SAC+crop、DR、NetRand、SAC+IDM和PAD。研究团队依照前人的设置,使用来自DMControl的8个任务进行实验。测量泛化能力,随机生成背景和机器人本身的颜色,将真实的视频作为动态背景。除了一项任务外,SECANT在所有任务中都显着优于先前的SOTA,通常高出88.3%。所有方法都经过50万步训练,有密集的任务特定奖励。Robosuite是用于机器人研究的模块化模拟器。作者在4个具有挑战性的单臂和双手操作任务上对SECANT和先前方法进行了基准测试。使用具有操作空间控制的Franka Panda机器人模型,并使用特定于任务的密集奖励进行训练。所有agent都接收一个168×168以自我为中心的RGB视图作为输入。与之前SOTA相比,SECANT有337.8%的提升实验表明,与之前的最佳方法相比,SECANT在简单设置中获得的奖励平均增加了287.5%,在困难设置中增加了374.3%,在极端设置中增加了351.6%。为了进一步验证SECANT对自然变化的泛化能力,作者在CARLA模拟器中构建了一个具有视觉观察的真实驾驶场景。测试目标是在1000个时间步长内沿着8字形高速公路(CARLA Town 4)行驶尽可能远,不与行人或车辆发生碰撞。agent在「晴朗的中午」情景接受训练,并在中午和日落时对各种动态天气和光照条件进行评估。例如,潮湿天气的特点是道路具有高反射点。经过平均每个天气超过10集和5次训练运行,SECANT在测试中能够比之前的SOTA行驶的距离增加47.7%。iGibson是一个交互式模拟器,有高度逼真的3D房间和家具。奖励函数激励agent使灯在视野中所占的像素比例最大,当这个比例在连续10个步骤中超过5%时就算成功。在本测试中,在未见过的房间里,SECANT的成功率比之前的方法高出15.8%。本文一作是李飞飞门下得意弟子Linxi Fan,他毕业于上海实验中学,本科就读于纽约哥伦比亚大学,目前在斯坦福大学攻读博士,主修计算机视觉、强化学习以及机器人技术。在英伟达实习期间完成了本论文。本文二作黄德安同样师从李飞飞, 获得了卡内基梅隆大学硕士学位。目前在斯坦福大学计算机科学专业攻读博士学位,在NVIDIA做泛化学习类研究。三作禹之鼎也是来自NVIDIA的科学家,获得华南理工大学电机工程联合班学士学位、香港科技大学电子工程学士学位,2017年在卡内基梅隆大学获得了ECE博士学位。2018年加入英伟达,现在是英伟达机器学习研究组的高级研究科学家。https://arxiv.org/abs/2106.09678