
YOLOS:重新思考Transformer的泛化性能
共 3676字,需浏览 8分钟
·
2021-07-04 01:39
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
本文是华科&地平线关于Transformer的迁移学习、泛化性能方面的深度思考。重点揭示了Transformer的迁移学习能力与泛化性能,同时引出了Transformer在模型缩放与ConvNet缩放不一致的问题。

paper: https://arxiv.org/abs/2106.00666
code: https://github.com/hustvl/YOLOS
本文是华科&地平线关于Transformer的迁移学习、泛化性能方面的深度思考。依托于目标检测任务,从最基本的ViT出发,参考DETR架构设计,从ViT的预训练、迁移学习、模型缩放等几个维度展开了讨论了,重点揭示了Transformer的迁移学习能力与泛化性能,同时引出了Transformer在模型缩放与ConvNet缩放不一致的问题。
Abstract
Transformer能否以最少的2D空间结构从纯粹的序列到序列的角度进行2D目标识别呢?
为回答该问题,我们提出了YOLOS(You Only Look at One Sequence),一系列基于朴素ViT(即尽可能少的进行修改)的目标检测模型。我们发现:在中等大小数据集ImageNet上预训练的YOLOS已经足以在COCO上取得极具竞争力的目标检测性能,比如:YOLOS-Base可以取得42.0boxAP指标。与此同时,我们还通过目标检测。讨论了当前预训练机制、模型缩放策略对于Transformer在视觉任务中的局限性。
YOLOS
在模型设计方面,我们尽可能参照原始ViT架构,并参照DETR针对目标检测进行适当调整。YOLOS可以轻易的适配不同的Transformer结构,这种简单的设置初衷不是为了更好的检测性能,而是为了尽可能无偏的揭示Transformer在目标检测方面的特性。
Architecture
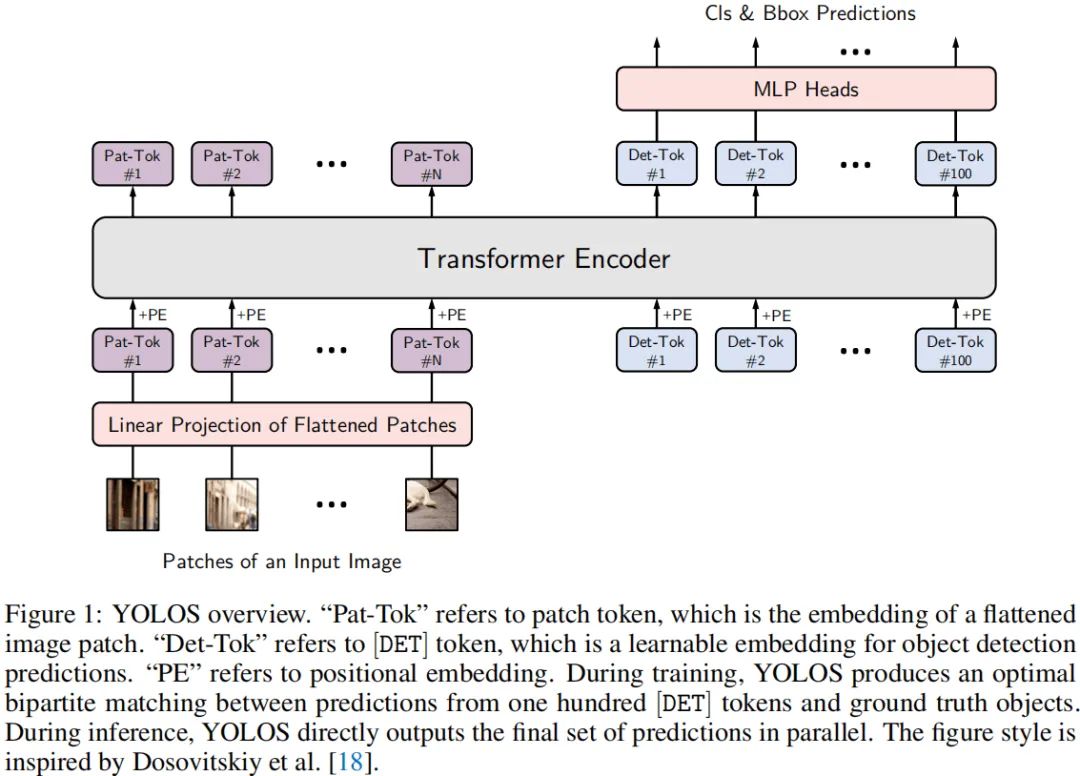
上图给出了本文所提YOLOS架构示意图,而从ViT到YOLOS的过渡非常简单:
YOLOS丢弃了用于图像分类的CLS而添加了100个随机初始化的DET; 在训练阶段,YOLOS采用偶匹配损失( Bipartite Matching Loss)替换了图像分类损失以进行目标检测。
Detection Token
我们针对性的选择随机初始的DET作为目标表达的代理以避免2D结构与标签赋值时注入的先验知识存在的归纳偏置。当在COCO上进行微调时,每次前向传播时,在DET与真实目标之间构建一个最优偶匹配。该步骤起着与标签赋值相同的作用,但它与2D结构无关,也即是说:YOLOS不需要将ViT的输出重解释为2D结构以进行标签赋值。理论上来讲,YOLOS可以进行任意维目标检测,且无需知道精确的空间结构或者几何结构,只要将输入按照相同方式平展为序列即可。
Fine-tuning at Higher Resolution
当在COCO上进行微调时,除了用于分类和BBOX规范的MLP参数以及DET外,其他参数均由ImageNet预训练而来。在YOLOS中,分类与BBOX头采用两层MLP实现且参数不共享。在微调阶段,图像具有比预训练更大的分辨率,我们保持块尺寸()不变,因而导致了更大的序列长度。我们采用了类似ViT的方式对预训练位置嵌入进行2D插值。
Inductive Bias
我们精心设计了YOLOS以最小化额外的归纳偏置注入。由ViT产生的归纳片偏置源自网络的stem部分的块提取以及位置嵌入的分辨率调整。除此之外,YOLOS并未在ViT上添加额外卷积。从表达学习角度,我们选择采用DET作为目标代理并用于最终目标预测以避免额外的2D归纳偏置。
Comparisons with DETR
YOLOS的设计是受DETR启发而来:YOLOS采用DET作为目标表达的代理以避免2D结构和任务相关的先验知识导致的归纳偏置,YOLOS采用了与DETR相似的优化方式。但同时存在几点不同:
DETR采用了随机初始化的编解码形式的Transformer;而YOLOS则仅研究了预训练ViT编码的迁移能力; DETR采用了decoder-encoder注意力并在每个decoder层添加额外辅助监督;而YOLOS总是查看每一层的一个序列,而没有再操作方面对块与DET进行区分。
Experiments
Setup
Pre-training
我们在ImageNet上采用DeiT训练策略对YOLOS/ViT进行预训练。
Fine-tuning
我们采用类似DETR方式在COCO数据上对YOLOS进行微调。
Model Variants
下表给出了我们关于YOLOS的不同模型配置信息。
The Effects of Pre-training
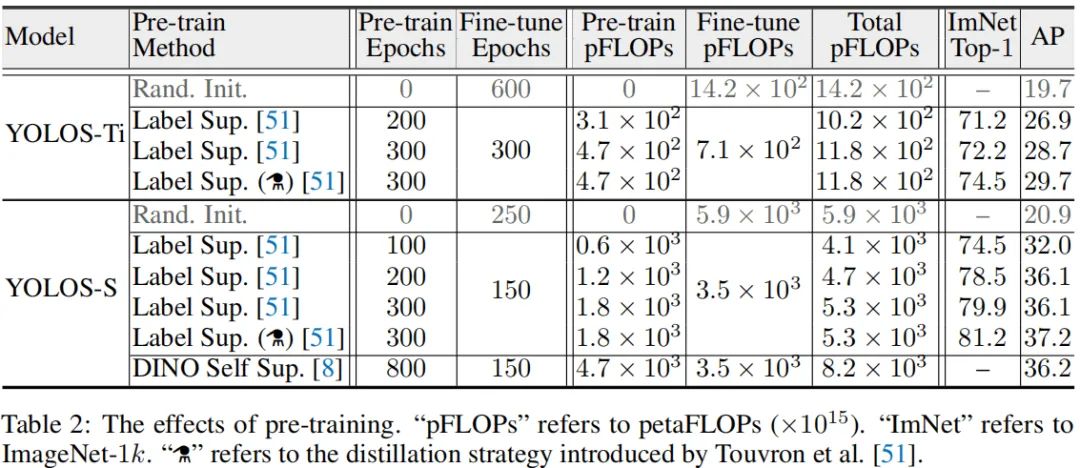
我们通过YOLOS研究了不同预训练策略对于ViT的影响,结果见上表。从上表可以看到:
至少在迁移学习框架下,从计算效率角度来看,预训练是很有必要的。从Tiny与Small模型对比来看,预训练可以节省大量的计算耗时;而且从头开始训练的模型性能要低于预训练模型的性能。这与恺明大神之前关于ConvNet的预训练研究不一致。 从真实标签监督预训练来看,不同大小模型倾向于不同的预训练机制:200epoch预训练+300epoch微调的YOLOS-Ti仍无法匹配300epoch预训练的性能;而对于small模型200epoch预训练具有与300epoch预训练相当的性能。引入额外的蒸馏,模型的性能可以进一步提升1AP指标。这是因为预训练CNN老师后模型有助于ViT更好的适配COCO。 从上述分析我们可以得出:ImageNet预训练结果无法精确的反应在COCO目标检测上迁移学习性能。相比图像识别中常用的迁移学习基准,YOLOS对于预训练机制更为敏感,且性能仍未达到饱和。因此,将YOLOS作为一个具有挑战性的迁移学习基础评价不同预训练策略对于ViT的影响是很合理的。
Pre-traing and Transfer Learning Perforrmance of Different Scaled Models
我们研究了不同模型缩放策略的预训练与迁移学习性能,比如宽度缩放w、均匀复合缩放dwr以及快速速度dwr。模型从1.2G缩放到4.5G并用于预训练。相关模型配置见前面的Table1,结果见下表。
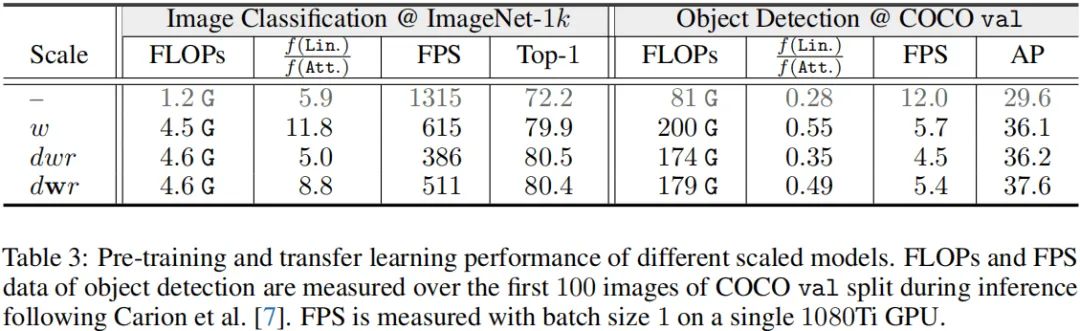
从上表指标对比可以看到:
dwr与dwr缩放均比简单的w缩放取得了更佳的精度; 关于缩放策略的属性与CNN相一致,比如w缩放速度最友好;dwr缩放取得了最佳精度;dwr缩放速度接近w缩放,精度与dwr相当。 由于COCO数据微调时分辨率与预训练分辨率不一致,此时预训练性能与迁移学习性能出现了不一致:dwr缩放具有与w缩放相当的性能,而dwr缩放则具有最佳性能。这种性能不一致说明:ViT需要一种新的模型缩放策略。
Comparisons with CNN-based Object Detectors
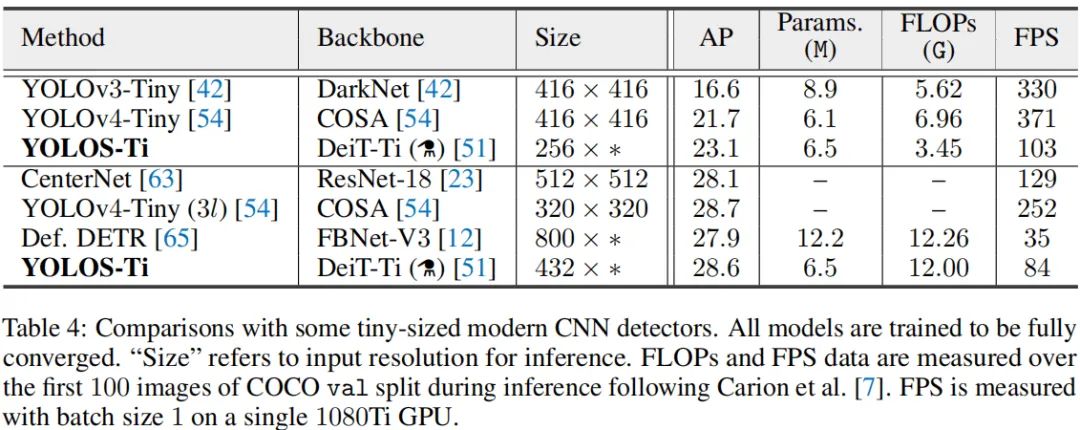
上表对比了YOLOS与ConvNet作为骨干时的性能,从中可以看到:在Tiny模型方面,YOLOS-Ti取得比高度优化CNN作为骨干时更佳的性能。
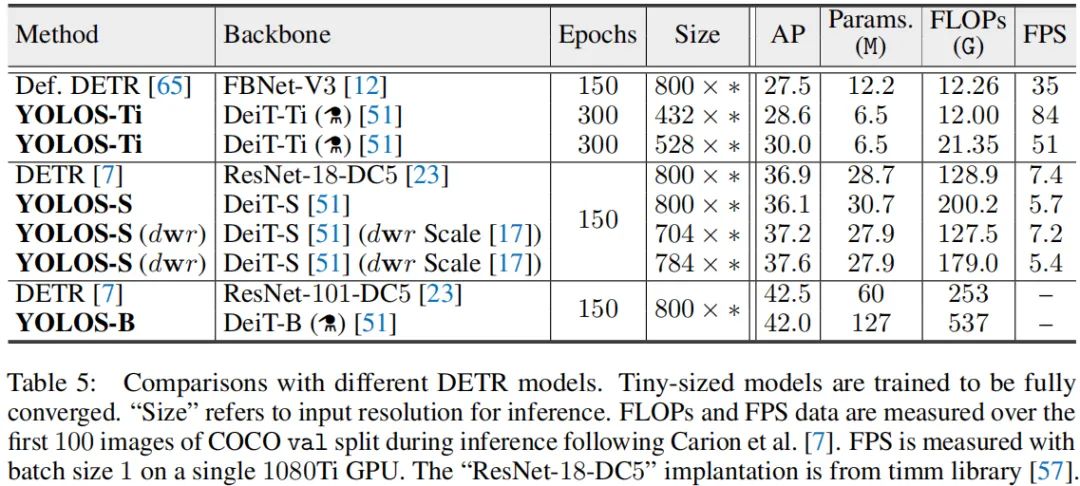
上表给出了YOLOS与DETR的性能对比,从中可以看到:
YOLOS-Ti具有比DETR更佳的性能; YOLOS-S-dwr缩放取得了比DETR更佳的性能; 而YOLOS-B尽管具有更多的参数量,但仍比同等大小DETR稍弱。
尽管上述结果看起来让人很是沮丧,但是YOLOS的出发点并不是为了更佳的性能,而是为了精确的揭示ViT在目标检测方面的迁移能力。仅需要对ViT进行非常小的修改,这种架构即可成功的迁移到极具挑战性的COCO目标检测基准上并取得42boxAP指标。YOLOS的这种最小调改精确地揭示了Transformer的灵活性与泛化性能。
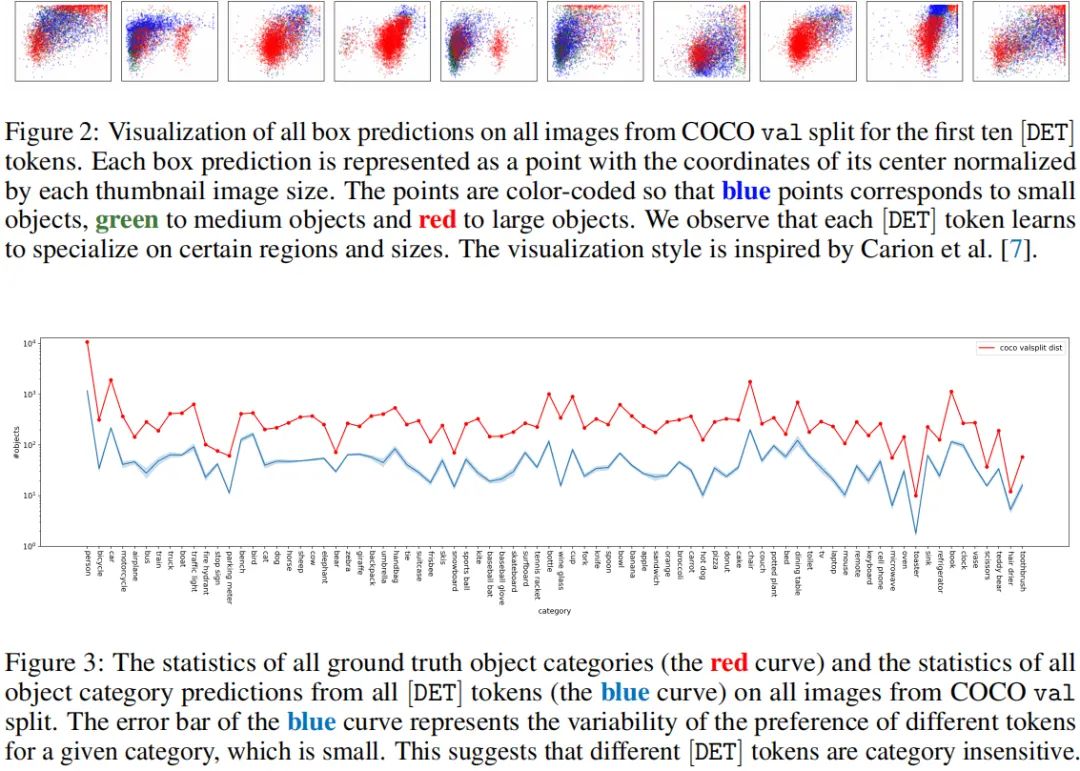
作为一种目标检测器,YOLOS采用DET表示所检测到地目标。我们发现:不同DET对目标位置与尺寸比较敏感,而对目标类别不敏感。见上面Fig2与Fig3.
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!

点个在看 paper不断!