
YOLOS:通过目标检测重新思考Transformer(附源代码)
共 3493字,需浏览 7分钟
·
2021-09-28 02:04

计算机视觉研究院专栏
作者:Edison_G
最近“计算机视觉研究院”有一段时间没有分享最新技术,但是最近我看了一些之前的检测框架,发现有两个很有意思,不错的框架,接下来我给大家简单分析下,希望给大家带来创新的启示!

1

2

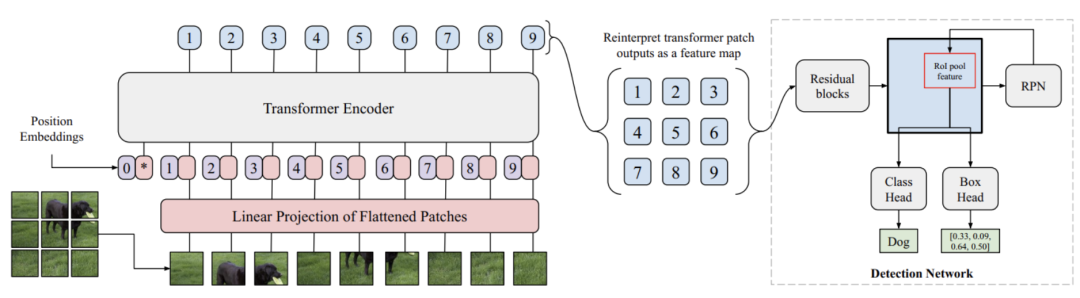
ViT-FRCNN是第一个使用预训练的ViT作为R-CNN目标检测器的主干。然而,这种设计无法摆脱对卷积神经网络(CNN)和强2D归纳偏差的依赖,因为ViT-FRCNN将ViT的输出序列重新解释为2D空间特征图,并依赖于区域池化操作(即RoIPool或RoIAlign)以及基于区域的CNN架构来解码ViT特征以实现目标级感知。受现代CNN设计的启发,最近的一些工作将金字塔特征层次结构和局部性引入Vision Transformer设计,这在很大程度上提高了包括目标检测在内的密集预测任务的性能。然而,这些架构是面向性能的。另一系列工作,DEtection TRansformer(DETR)系列,使用随机初始化的Transformer对CNN特征进行编码和解码,这并未揭示预训练Transformer在目标检测中的可迁移性。
为了解决上面涉及的问题,有研究者展示了You Only Look at One Sequence (YOLOS),这是一系列基于规范ViT架构的目标检测模型,具有尽可能少的修改以及注入的归纳偏置。从ViT到YOLOS检测器的变化很简单:
YOLOS在ViT中删除[CLS]标记,并将一百个可学习的[DET]标记附加到输入序列以进行目标检测;
YOLOS将ViT中的图像分类损失替换为bipartite matching loss,以遵循Carion等人【End-to-end object detection with transformers】的一套预测方式进行目标检测。这可以避免将ViT的输出序列重新解释为2D特征图,并防止在标签分配期间手动注入启发式和对象2D空间结构的先验知识。
3
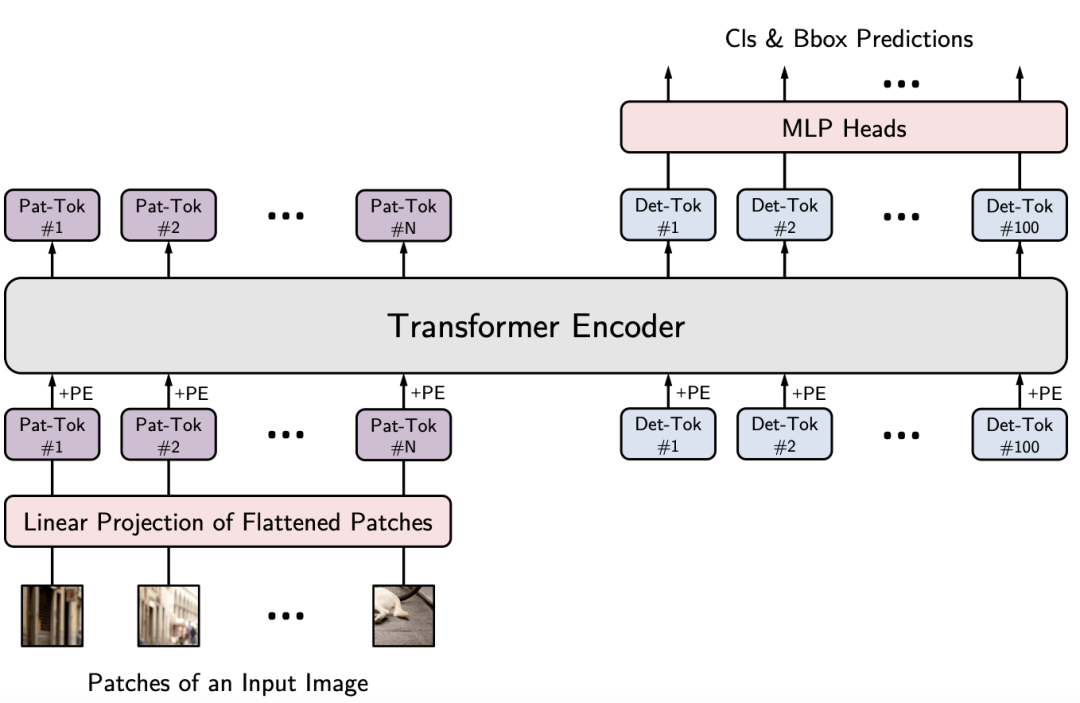
YOLOS删除用于图像分类的[CLS]标记,并将一百个随机初始化的检测标记([DET] 标记)附加到输入补丁嵌入序列以进行目标检测。
在训练过程中,YOLOS将ViT中的图像分类损失替换为bipartite matching loss,这里重点介绍YOLOS的设计方法论。

4
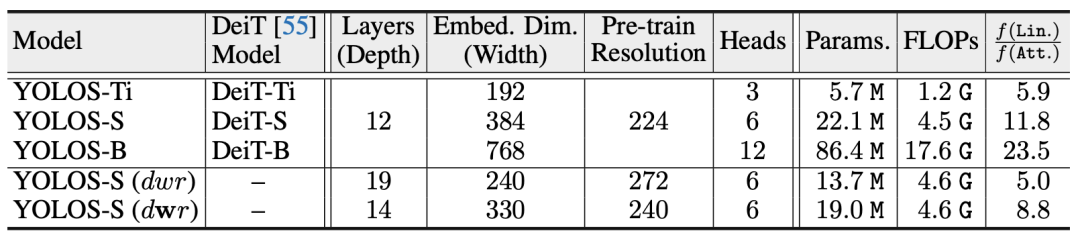
YOLOS的不同版本的结果
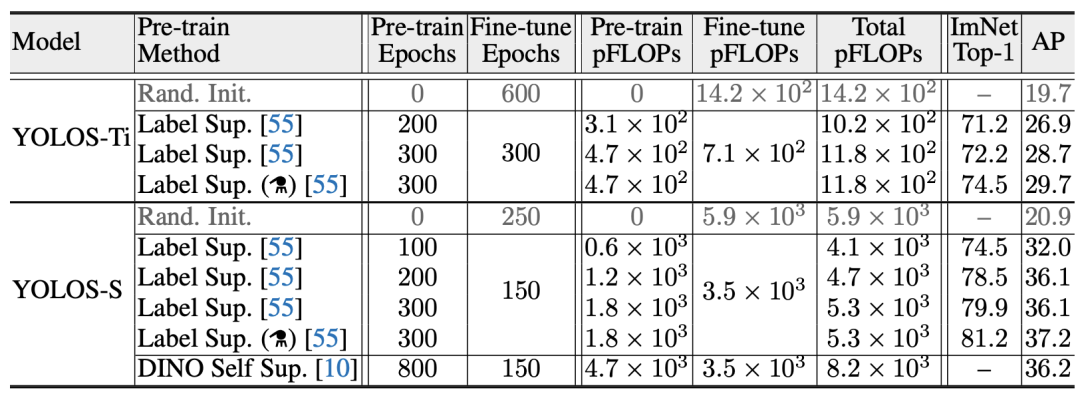
与训练的效果
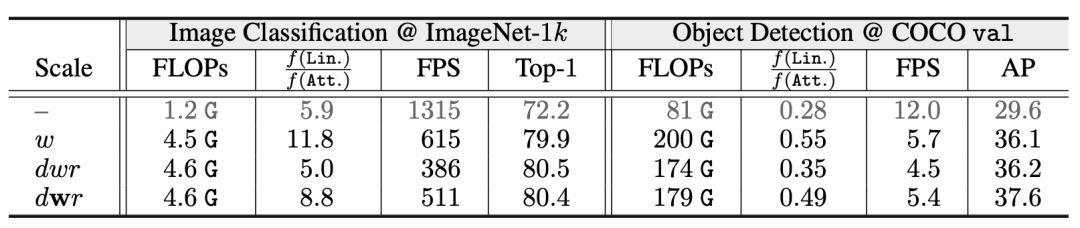
不同尺度模型的预训练和迁移学习性能
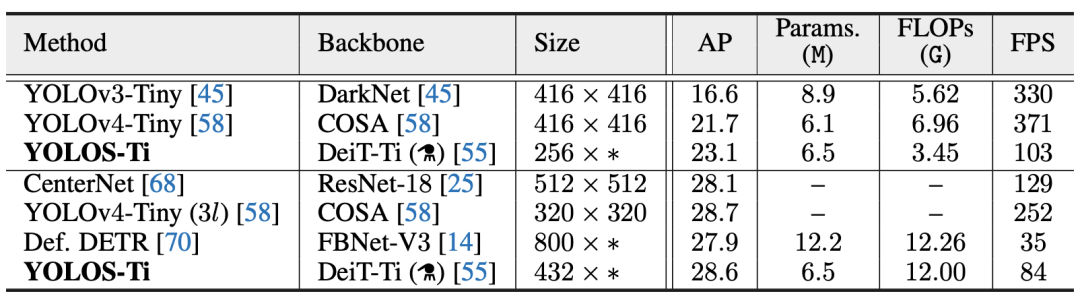
与一些小型CNN检测器的比较

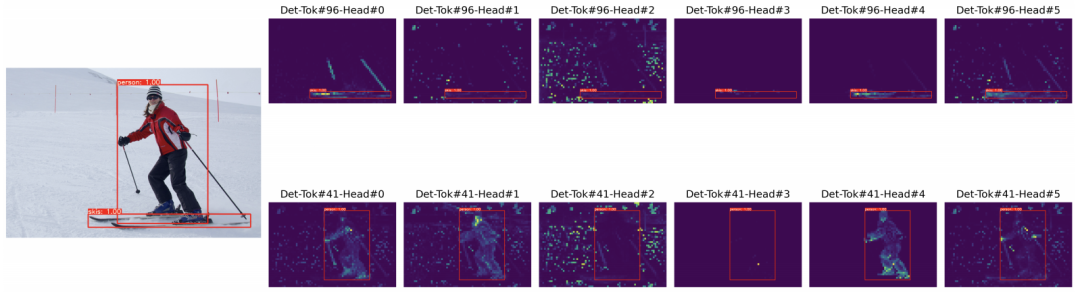
对于给定的YOLOS模型,不同的自注意力头关注不同的模式和不同的位置。一些可视化是可解释的,而另一些则不是。
我们研究了两个YOLOS模型的注意力图差异,即200 epochs ImageNet-1k预训练YOLOS-S和300 epochs ImageNet-1k预训练YOLOS-S。注意这两个模型的AP是一样的(AP=36.1)。从可视化中,我们得出结论,对于给定的预测对象,相应的[DET]标记以及注意力图模式通常对于不同的模型是不同的。
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
自己觉得挺有意思的目标检测框架,分享给大家(源码论文都有) CVPR2021:IoU优化——在Anchor-Free中提升目标检测精度(附源码) 多尺度深度特征(上):多尺度特征学习才是目标检测精髓(干货满满,建议收藏) 多尺度深度特征(下):多尺度特征学习才是目标检测精髓(论文免费下载) ICCV2021目标检测:用图特征金字塔提升精度(附论文下载) CVPR21小样本检测:蒸馏&上下文助力小样本检测(代码已开源) 半监督辅助目标检测:自训练+数据增强提升精度(附源码下载) 目标检测干货 | 多级特征重复使用大幅度提升检测精度(文末附论文下载) 目标检测新框架CBNet | 多Backbone网络结构用于目标检测(附源码下载) CVPR21最佳检测:不再是方方正正的目标检测输出(附源码) Sparse R-CNN:稀疏框架,端到端的目标检测(附源码) 利用TRansformer进行端到端的目标检测及跟踪(附源代码)