
我就想加个索引,怎么就这么难?
共 8336字,需浏览 17分钟
·
2020-06-11 23:23
领导让我
❞SQL优化,我直接把服务干挂了...
前言
MySQL大表加字段或者加索引,是有一定风险的。
大公司一般有DBA,会帮助开发解决这个痛点,可是DBA是怎么做的呢?
小公司没有DBA,作为开发我们的责任就更大了。那么我们怎么才能安全的加个索引呢?
今天,我们通过模拟案例以及原理分析,去弄清楚MySQL中DDL的风险,以及如何避免事故发生。
准备
软件以及项目
- 安装本地版本MySQL。
- 一个简单的增删改查项目。
- 使用JMeter进行并发请求测试。
创建表
# 如果存在user表则删除
DROP TABLE IF EXISTS user;
# 创建user表
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` varchar(10) DEFAULT NULL COMMENT '姓名',
`age` int(2) DEFAULT NULL COMMENT '年龄',
`address` varchar(30) DEFAULT NULL COMMENT '地址',
`description` varchar(100) DEFAULT NULL COMMENT '描述',
`test_id` bigint DEFAULT NULL COMMENT '测试 id',
`create_time` timestamp NULL DEFAULT NULL COMMENT '创建时间',
`modify_time` timestamp NULL DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='mysql ddl测试表';
创建存储过程
# 如果存在test存储过程则删除
DROP PROCEDURE IF EXISTS `test`;
# 创建无参存储过程,名称为test
CREATE PROCEDURE test()
BEGIN
# 声明变量
DECLARE i INT;
# 变量赋值
SET i = 0;
# 结束循环的条件: 当i等于100万时跳出while循环
WHILE i < 1000000 DO
# 往t_test表添加数据
INSERT INTO `test`.user (`name`, `age`, `address`,
`description`, `test_id`, `create_time`, `modify_time`)
VALUES ('iisheng', 26, '北京', '如逆水行舟', LAST_INSERT_ID() + 1,
'2020-05-17 16:01:44', '2020-05-17 16:01:51');
# 循环一次, i加1
SET i = i + 1;
# 结束while循环
END WHILE;
END
❝下面的创建存储过程语句,是在
❞IDE内选择代码块执行的,如果在Terminal中执行,需要使用DELIMITER关键字,更改语句结束标志。
调用存储过程,生成百万数据
CALL test();
开启慢SQL日志
# 查看MySQL是否开启慢日志记录
SHOW VARIABLES LIKE 'slow_query_log';
# 开启慢SQL日志记录
SET GLOBAL slow_query_log = 'ON';
# 查看慢SQL日志位置
SHOW VARIABLES LIKE 'slow_query_log_file';
# 查看执行多久的SQL才算慢SQL
SHOW VARIABLES LIKE 'long_query_time';
# 设置慢SQL执行时间 只有新session才生效
SET GLOBAL long_query_time = 1;
❝通常情况下这些会在MySQL的配置文件中配置,启动时生效。
❞
几个有用的SQL语句
# 展示哪些线程正在运行
SHOW PROCESSLIST;
# 查看正在执行的事务
SELECT * FROM information_schema.INNODB_TRX;
# 查看正在锁的事务
SELECT * FROM information_schema.INNODB_LOCKS;
# 查看正在等待锁的事务
SELECT * FROM information_schema.INNODB_LOCK_WAITS;
# 显示innodb存储引擎状态的大量信息,包含死锁日志
SHOW ENGINE INNODB STATUS ;
# 展示数据库最大连接数的配置
SHOW VARIABLES LIKE 'max_connections';
# 查看存在哪些触发器
SELECT * FROM information_schema.TRIGGERS;
# 查看MySQL版本
SELECT VERSION();
❝后面我们会主要用前两条。
❞
事故现场
说明
- 我创建的
user表除了主键是没有其他索引的。 - 测试的
user表数据量为一百万。 - 测试
MySQL版本为5.7.28。 - 测试项目的逻辑:随机get()、list()、update()、create(),每个操作都开启事务,并且休眠500毫秒。
步骤
❝运行测试项目
❞
 项目启动图
项目启动图
这里我们可以看到,项目已经正常启动了。
❝❞
postman调用一下接口
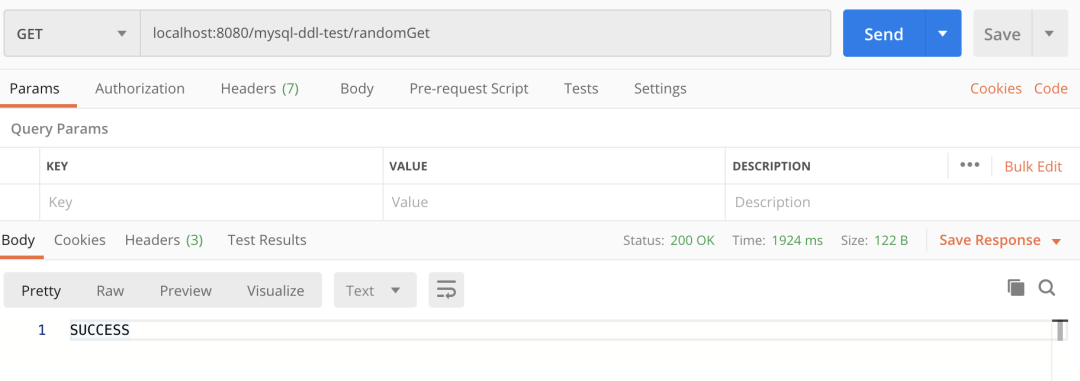 接口请求图
接口请求图
这里我们随便测试一个接口,请求时间2秒左右。
❝执行JMeter的Test Plan,观察项目日志
❞
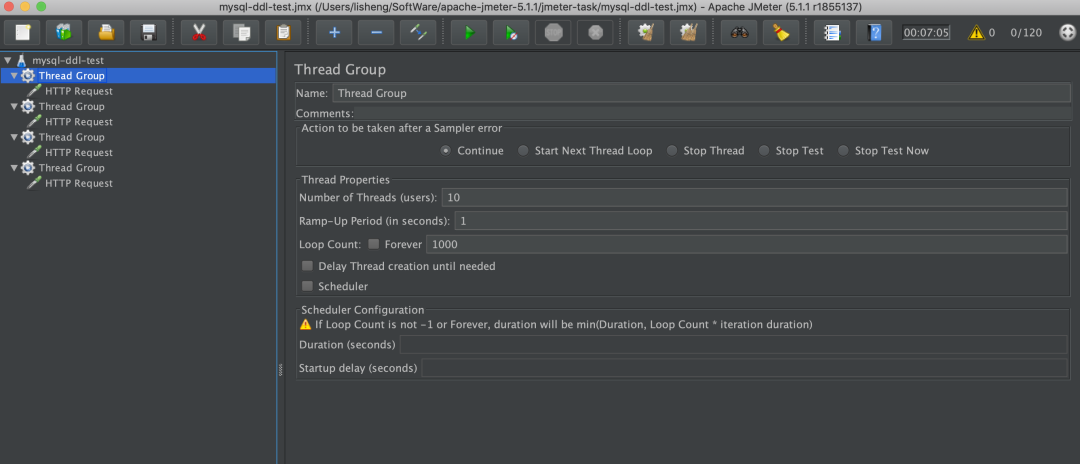 JMeter配置图
JMeter配置图
这里我们创建了四个线程组,每个线程组调用一个我们的接口。模拟10个人循环1000次的访问。
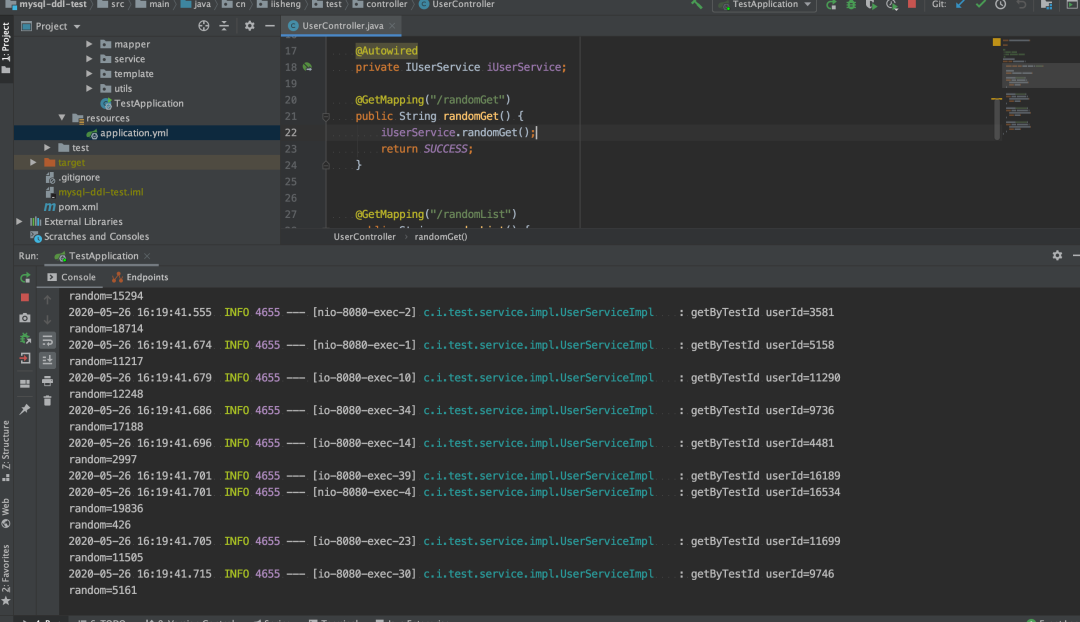 正常项目日志图
正常项目日志图
这里我们看到该请求频率下,日志无异常。
❝慢SQL日志
❞
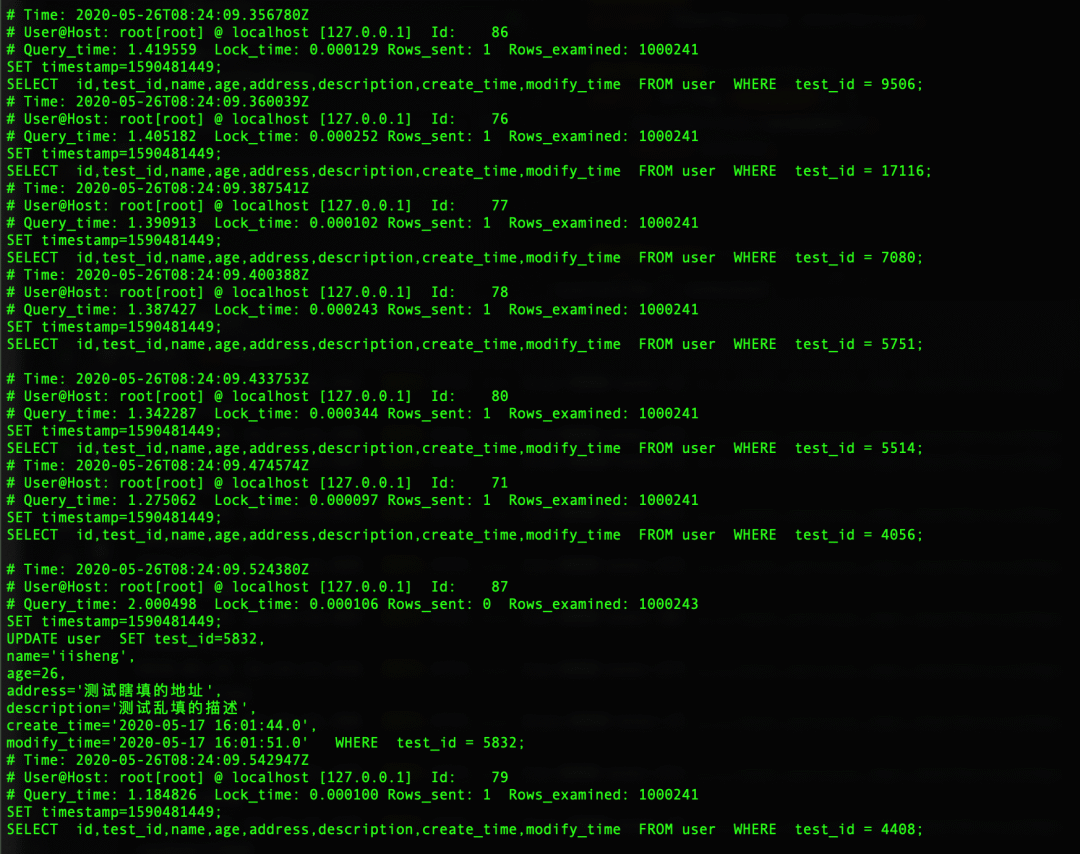 慢SQL日志图
慢SQL日志图
这里我们看到,百万级的SQL,如果没加索引SQL执行时间还是比较长的,有的已经达到了2s。
❝加个索引,再观察项目日志
❞
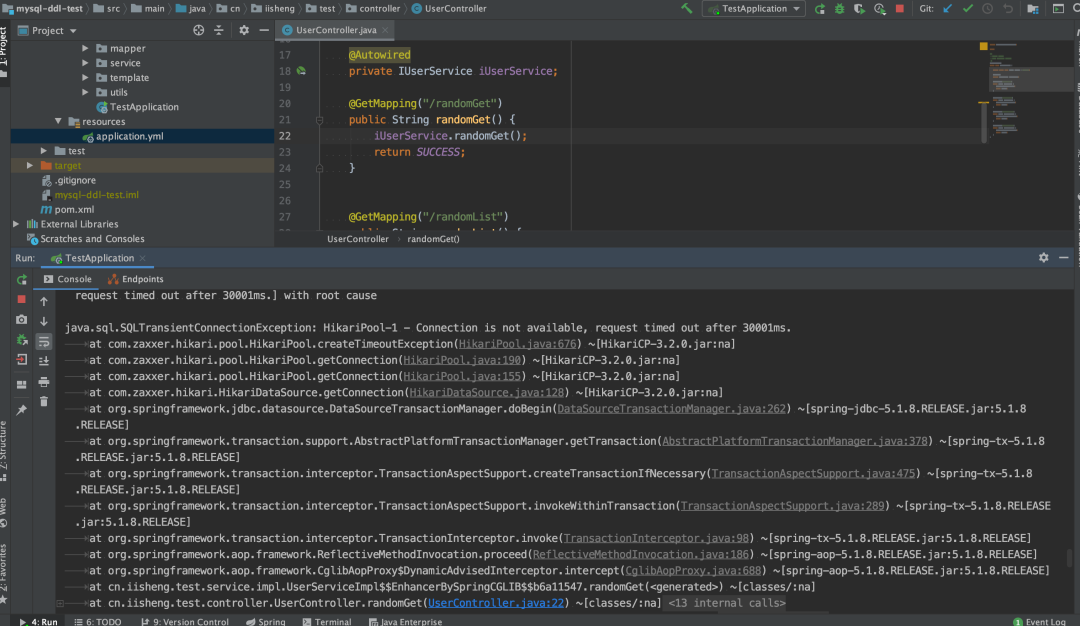 加索引过程日志图
加索引过程日志图
这里我们看到,项目已经开始报错了,大量的Connection is not available, request timed out after 30001ms。
❝❞
SHOW PROCESSLIST一下
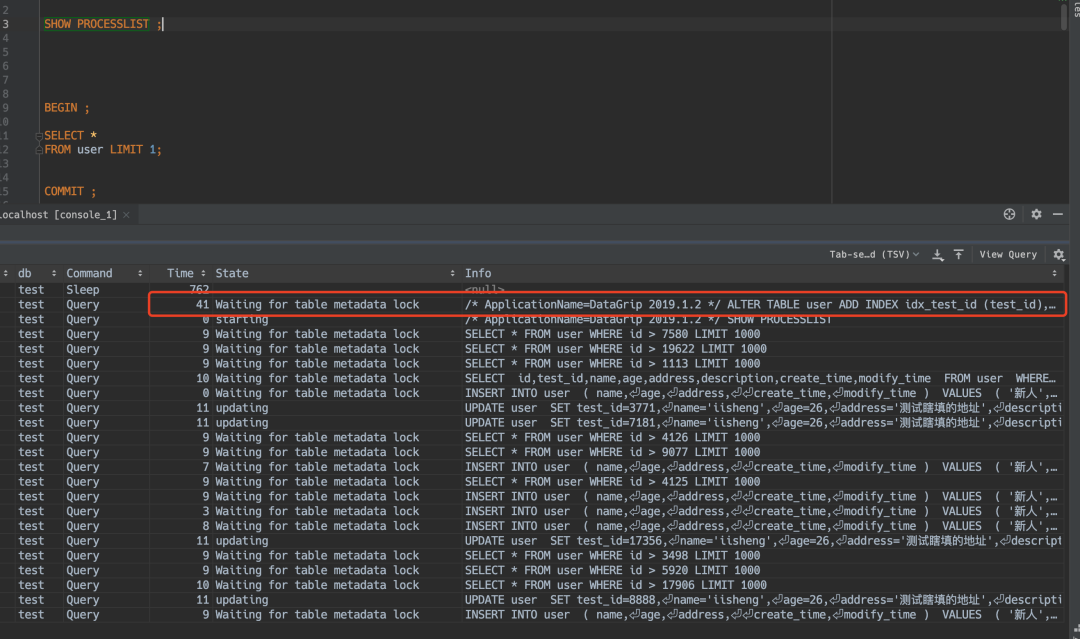 PROCESSLIST图
PROCESSLIST图
这里我们看到,有大量的Waiting for table metadata lock。
❝❞
postman再次调用一下接口
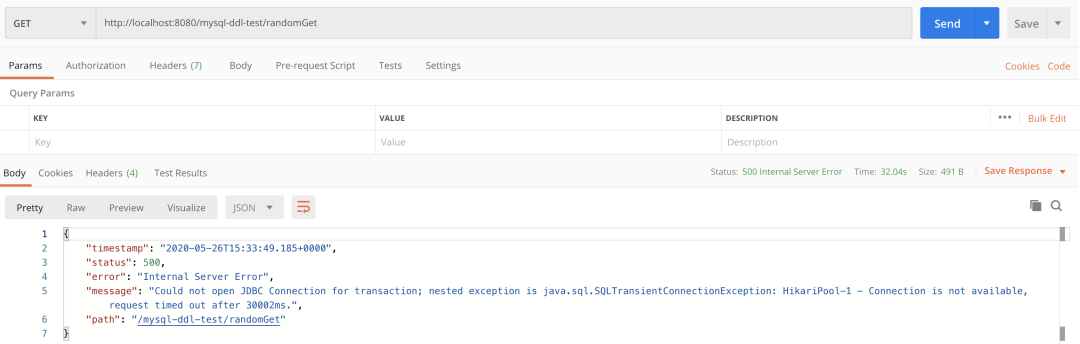 请求接口报错图
请求接口报错图
这个时候,调用接口已经报错了,响应时间也比较久。此时,服务对用户来说,已经基本不可用了。
为什么会这样?
❝我就想加个索引,怎么就这么难?
❞
看吧,就因为我加了个索引,服务就挂了,我没加之前还是好好的。遇到问题,我们要冷静,不是我们的锅坚决不能背,真的是我们的问题,下次一定要记得改正。那么,此刻的服务为什么就不可用了呢?
首先我们要知道,在InnoDB事务中,锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
然后,在MySQL5.5版本中引入了MDL(Metadata Lock),当对一个表做增删改查操作的时候,加MDL读锁;当要对表做结构变更操作的时候,加MDL写锁。
我们可以简单的尝试一下下面的情况。
 DDL锁等待图
DDL锁等待图
Session A开启一个事务,执行了一个简单的查询语句。此时,Session B,执行另一个查询语句,可以成功。接着,Session C执行了一个DDL操作,加了个字段,因为Session A的事务没有提交,而且Session A持有MDL读锁,Session C获取不到MDL写锁,所以Session C堵塞等待MDL写锁。又由于MDL写锁获取优先级高于MDL读锁,因此Session D这个时候也获取不到MDL读锁,等待Session C获取到MDL写锁之后它才能获取到MDL读锁。
我们发现,DDL操作之前如果存在长事务,一直不提交,DDL操作就会一直被堵塞,还会间接的影响后面其他的查询,导致所有的查询都被堵塞。
这也就是为什么我们把服务干挂的原因了。
目前主流解决方案
针对上面出现的情况,我们怎么解决呢?
MySQL5.6的Online DDL
MySQL从5.6开始,支持Online DDL。类似于这种的语句ALTER TABLE user ADD INDEX idx_test_id (test_id), ALGORITHM=INPLACE, LOCK=NONE在普通的ALTER TABLE或者CREATE INDEX语句后面添加ALGORITHM参数和LOCK参数。
❝实际上,
❞ALTERT TABLE语句如果不加ALGORITHM参数,默认就会选择ALGORITHM=INPLACE的形式,如果执行的语句支持INPLACE,否则,会使用ALGORITHM=COPY。
以前写SQL只会ALTER TABLE不知道后面还可以加ALGORITHM参数,后来知道了Online DDL,知道了可以加ALGORITHM=INPLACE,结果两种写法有的时候是一样的...
 MySQL官网截图
MySQL官网截图
这里顺便提一句,学习的途径有很多,但是官网,的确可以多看看。
使用pt-online-schema-change
❝简单说一下怎么安装这个东西
❞
首先官网下载,然后校验以及安装,执行下面命令
perl Makefile.PL
make
make install
然后使用CPAN安装相关依赖(适用Unix),CentOS下直接yum更简单
perl -MCPAN -e shell
cpan> install DBI
cpan> install DBD::mysql
❝我自己Mac安装没啥问题,公司Mac安装失败了,然后升级了一下Perl版本就可以了。
❞
语法
pt-online-schema-change --charset=utf8 --no-check-replication-filters --no-version-check --user=user --password=pass --host=host_addr P=3306,D=database,t=table --alter "ADD INDEX idx_name(field_name)" --execute
我的脚本添加索引
pt-online-schema-change --charset=utf8 --no-check-replication-filters --no-version-check --user=root --password=mGy6GAzdawFPTJ7R --host=127.0.0.1 P=3306,D=test,t=user --alter "add INDEX idx_test_id(test_id)" --execute
使用pt-osc测试
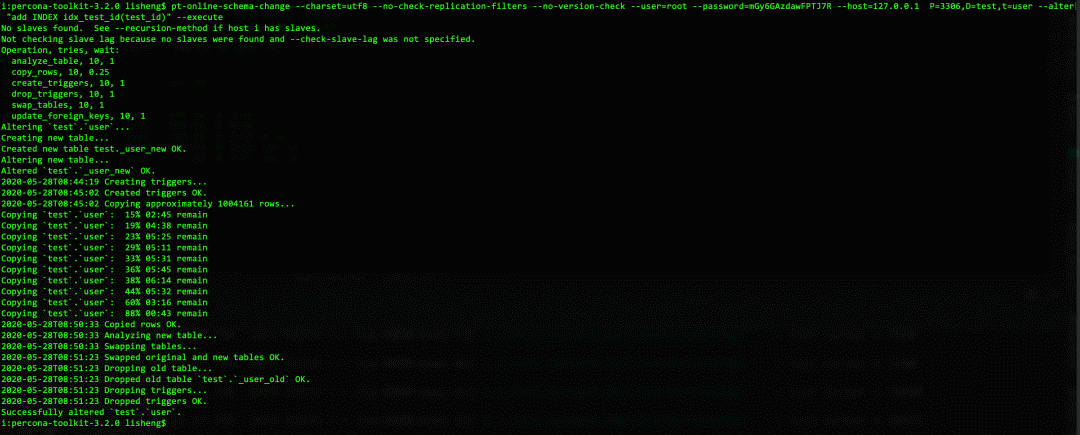 pt-osc执行图
pt-osc执行图
这里我们看到,pt-osc创建触发器的时候卡在那了。实际上这里也是在等待锁。
最终成功了,但是整个过程时间比较久。过程中我们也发现了一些死锁的日志。
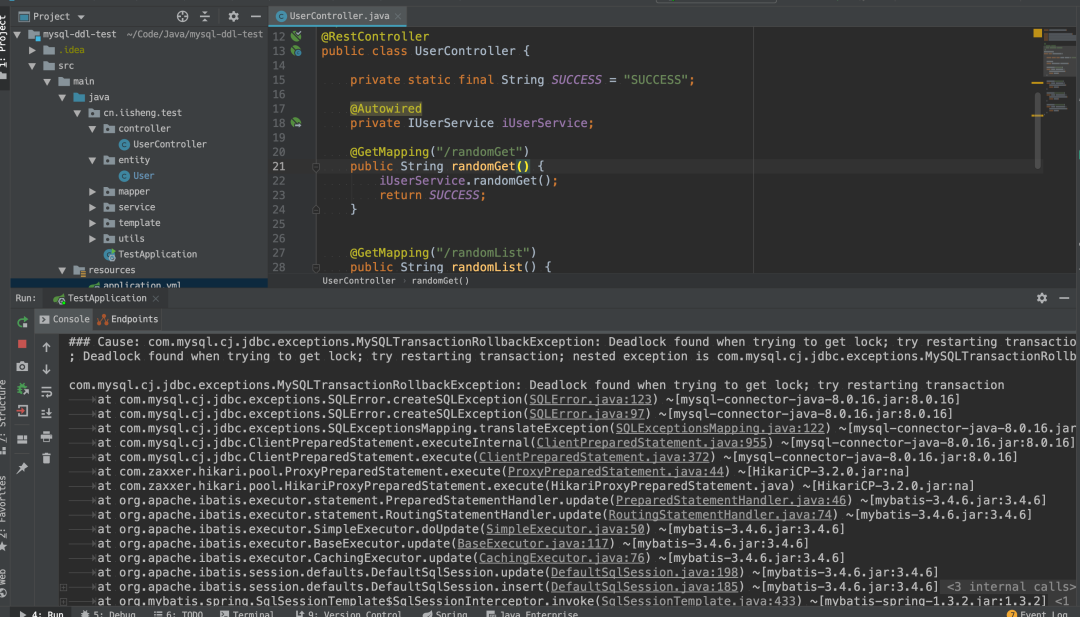 pt-osc死锁日志
pt-osc死锁日志
其实,这个跟我的代码有一定的关系,我的测试代码随机数生成的范围是[0, 20000],然后我根据生成的随机数,去查询数据库,锁的冲突会比较多。把范围修改为[0, 1000000]会好很多。
再看Online DDL
因为刚才我们发现了,自己代码写的有一些问题,所以我们刚才的结论也有一些影响。我们把随机数的范围改到100万,重新测试一遍。
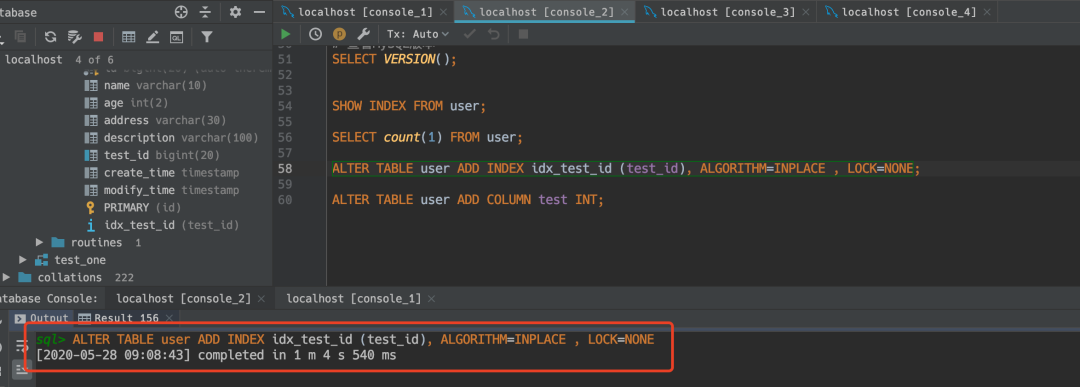 Online DDL 成功
Online DDL 成功
这次Online DDL也成功了。但是也是有一些连接超时的日志。之前的测试如果一直执行下去,也会成功,只不过堵塞时间太长,对用户影响太大,我就停止算执行失败了。
❝实际效果跟机器性能也是有一些关系的,这里的关键点在于拿
❞MDL写锁的等待时间,这个时间稍微久一些就会对用户造成很大的影响。
pt-osc执行过程
- 创建一个和原表表结构一样的临时表(
_tablename_new),执行alter修改临时表表结构。 - 在原表上创建3个与
insertdeleteupdate对应的触发器,用于copy数据的过程中,在原表的更新操作,更新到新表。 - 从原表拷贝数据到临时表,拷贝过程中在原表进行的写操作都会更新到新建的临时表。
rename原数据表为old表,把新表rename为原表名,并将old表删除。- 删除触发器。
这里面创建、删除触发器和rename表的时候都会尝试获取DML写锁,如果获取不到会等待。就是我们看到的Waiting for table metadata lock。
所以,这些时间段如果长时间获取不到锁,就会一直堵塞,还是会出现问题的。
Online DDL执行过程
- 拿
MDL写锁 - 降级成
MDL读锁 - 真正做
DDL - 升级成
MDL写锁 - 释放
MDL锁
1、4如果没有锁冲突,执行时间非常短。第3步占用了DDL绝大部分时间,这期间这个表可以正常读写数据,因此称为online。
但是,如果拿锁的时候没拿到,或者升级MDL写锁不能成功,就会等待,我们又会看到Waiting for table metadata lock,然后就接着的一系列问题了。
总结
加个索引,说难也难,说不难也不难。如果数据量大,又存在长事务,加索引的过程又有用户访问,Online DDL和pt-osc都不能保证对业务没有影响。但是如果我们SQL的执行时间比较短,或者我们加索引的时候,对应的业务没有多少请求。那么我们就可以很快的加完索引。
加字段也是类似的过程,但是如果我们能保证没有慢SQL,那么就不会存在长事务,那么执行时间就会很快,对用户就可以做到几乎没有影响。至于选择Online DDL还是pt-osc就要看他们的一些限制以及自己的场景需求了。感兴趣的同学,自己尝试一下。
最后想说
当万丈高楼崩塌的时候,超人也不能将它复原。我们应该做的,是有一个好的规范,好的认知,好的监控,在问题没有出现的时候,就将问题扼杀在摇篮中。而不是让问题,日渐壮大,大到覆水难收...
参考文献:
[1]:《MySQL实战45讲》
[2]: https://dev.mysql.com/doc/refman/5.7/en/
[3]: https://www.percona.com/doc/percona-toolkit/3.0/pt-online-schema-change.html

文末福利
分享一套Springboot开发的博客系统源码,为了让更多的Java读者能详细理解这个项目,作者把开发这个项目过程写成了文档。
从0到1一步一步带你从搭建项目框架,各种细节调整,以及如何开发各个模块的功能,比如即时通知,群聊,分布式实时搜索等功能,一共写了10+篇详细的开发设计文档,一步一步,一行一行代码,让你了解整个开发项目的过程,理解项目作者开发过程中的所有思考.

另外,长达17小时的eblog完整讲解视频已在上线啦,非常详细,一起来学eblog。
如何获取项目地址与详细的开发文档?
我把它放在我的Java开发宝典里了,大家扫一下下面的二维码,关注后回复关键字:eblog,即可获取项目,以及作者的详细开发文档、以及完整项目讲解视频!无任何套路!
扫描上面二维码,回复关键字:eblog
希望大家拿去好好学习,如果觉得不错,也可以把文章分享给其他小伙伴,一起学习!
点赞是最大的支持 ![]()