
CVPR 2021 速览 | 旷视研究院22篇入选学术成果盘点

极市导读
日前,CVPR 2021论文接收情况正式出炉。此次,旷视研究院共入选论文22篇,其中Oral论文2篇,研究领域涵盖激活函数、神经网络、神经网络架构搜索、光流估计、无监督学习、人体姿态估计、目标检测等。>>加入极市CV技术交流群,走在计算机视觉的最前沿

01 Neural Architecture Search with Random Labels

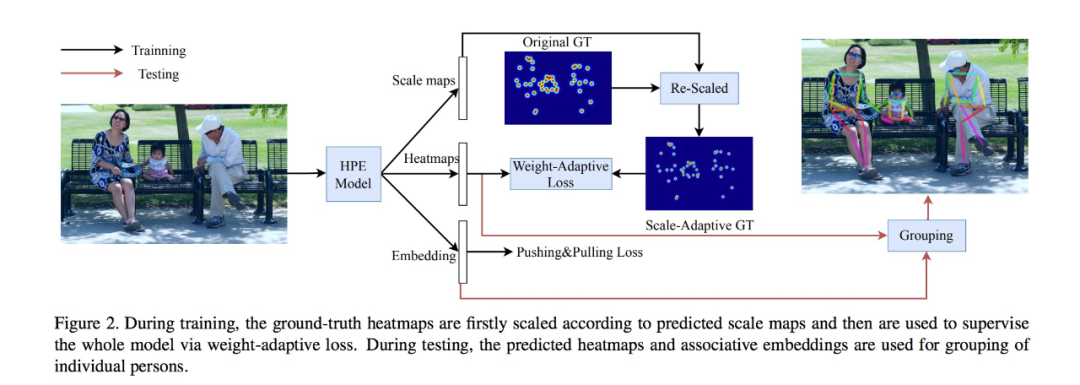
02 Rethinking the Heatmap Regression for Bottom-up Human Pose Estimation
03 General Instance Distillation for Object Detection

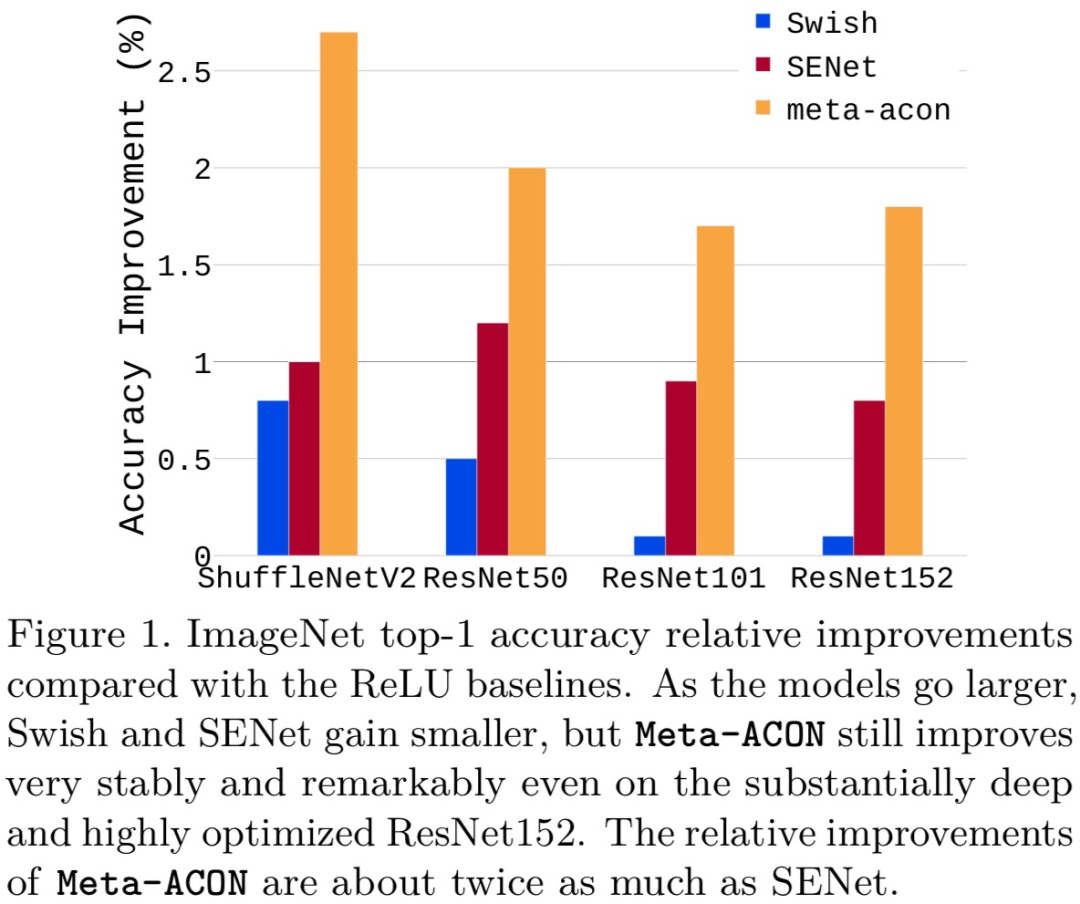
04 Activate or Not: Learning Customized Activation
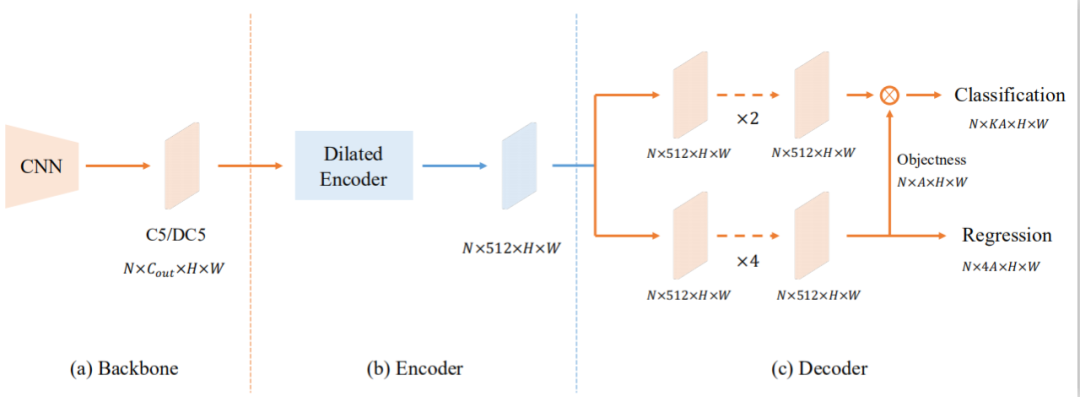
05 You Only Look One-level Feature
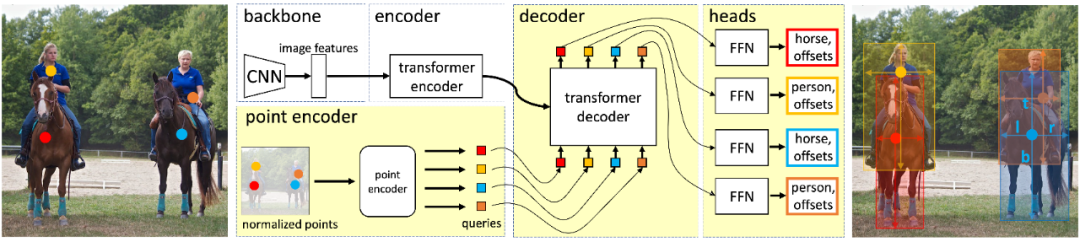
06 Points as Queries: Weakly Semi-supervised Object Detection by Points
07 Practical Wide-Angle Portraits Correction with Deep Structured Models

08 UPFlow:Upsampling Pyramid for Unsupervised Optical Flow Learning

09 NBNet: Noise Basis Learning for Image Denoising with Subspace Projection

10 Dynamic Metric Learning: Towards a Scalable Metric Space to Accommodate Multiple Semantic Scales

推荐阅读
2021-03-18

2021-03-16

2021-03-15


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论