【CVPR2021】旷视研究院入选学术成果盘点
oral论文
Fully Convolutional Networks for Panoptic Segmentation

oral论文
FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation
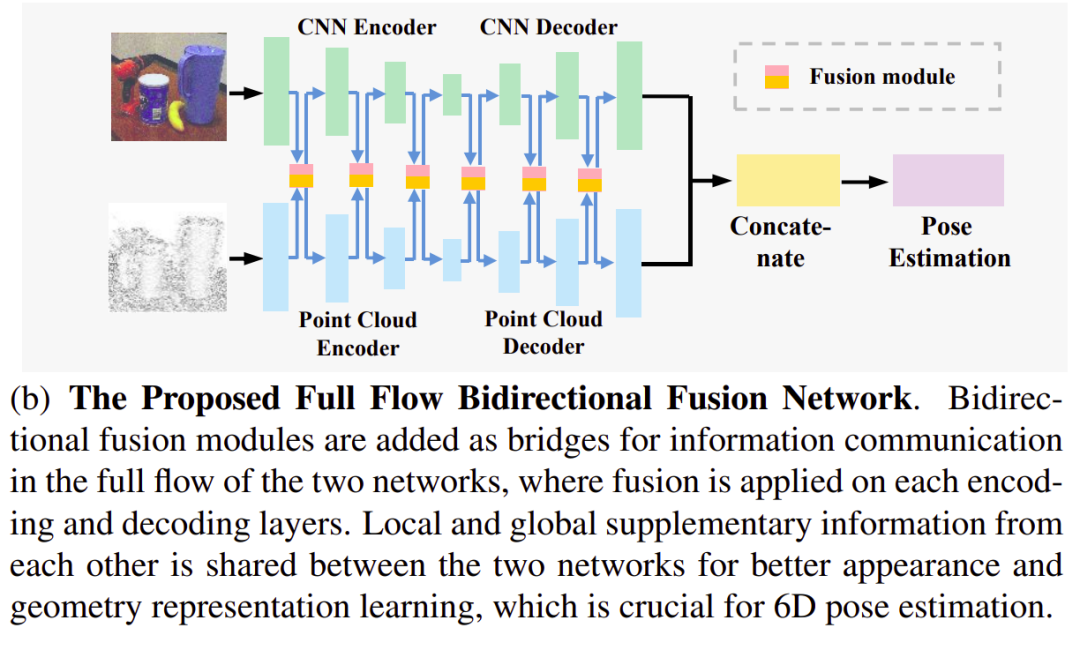
RepVGG: Making VGG-style ConvNets Great Again
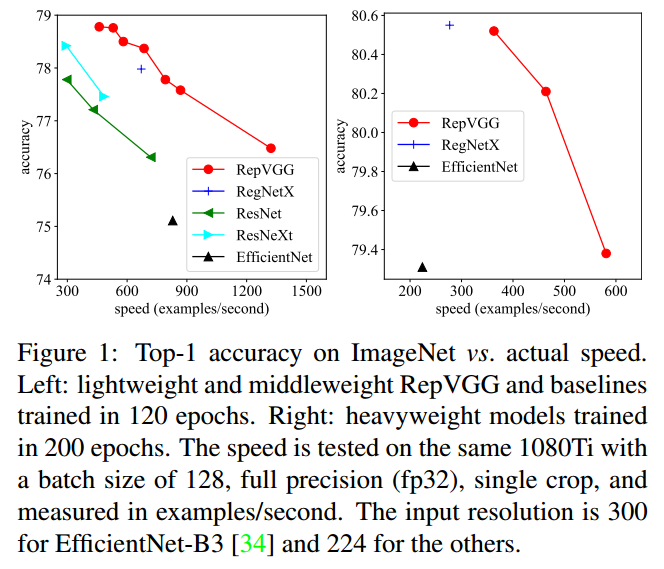
Dynamic Region-Aware Convolution
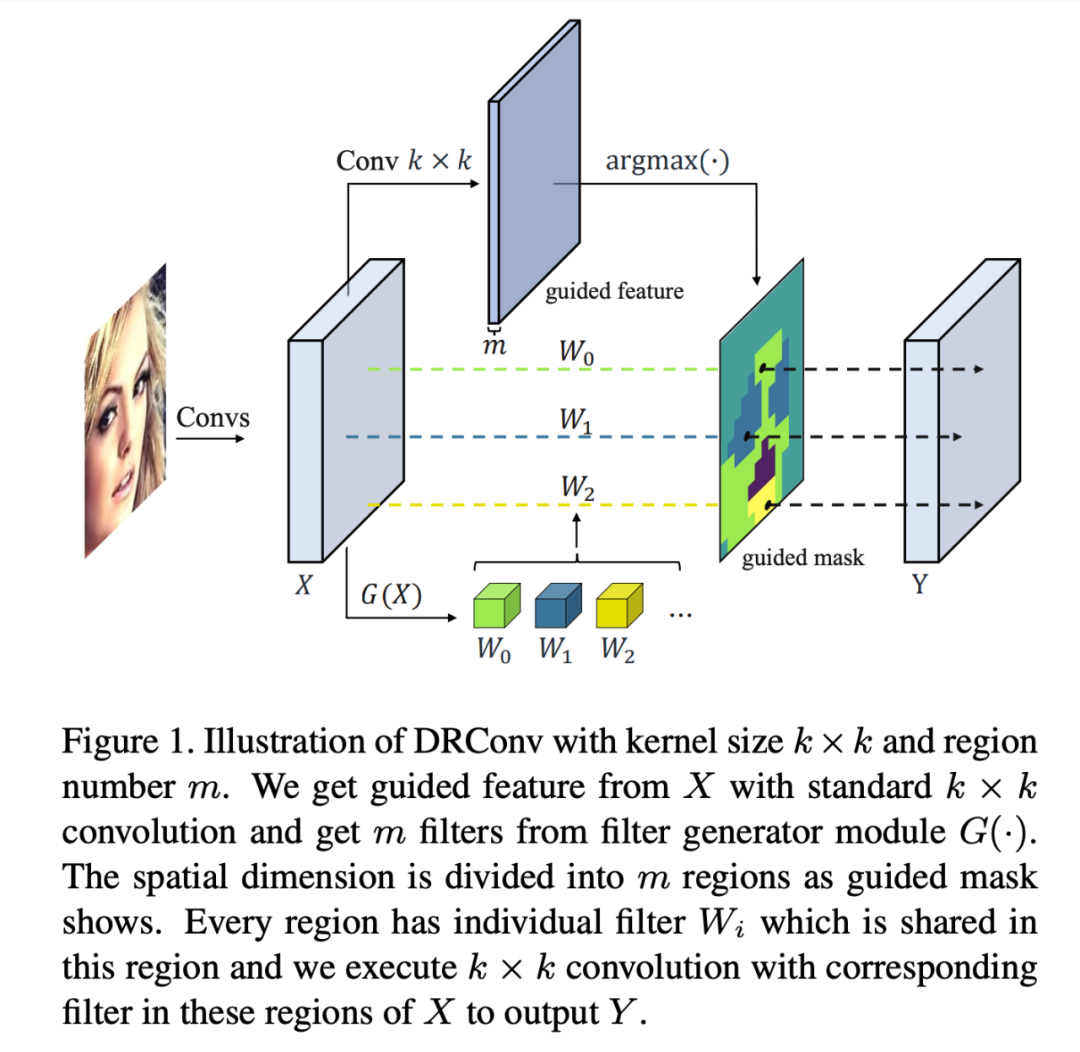
Diverse Branch Block: Building a Convolution as an Inception-like Unit
我们提出一种卷积网络基本模块(DBB),用以丰富模型训练时的微观结构而不改变其宏观架构,以此提升其性能。这种模块可以在训练后通过结构重参数化(structural re-parameterization)等效转换为一个卷积,因而不引入任何额外的推理开销。
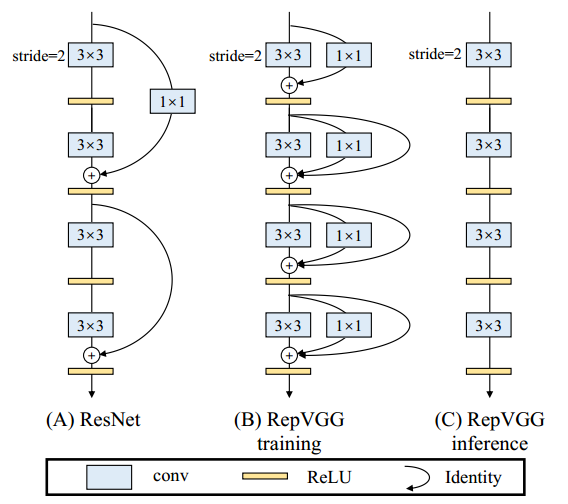
我们归纳了六种可以此种等效转换的结构,包括1x1-KxK连续卷积、average pooling等,并用这六种变换给出了一种代表性的形似Inception的DBB实例,在多种架构上均取得了显著的性能提升。我们通过实验确认了“训练时非线性”(而推理时是线性的,如BN)和“多样的链接”(比如1x1+3x3效果好于3x3+3x3)是DBB有效的关键。
👉关键词:结构重参数化,无推理开销,无痛提升
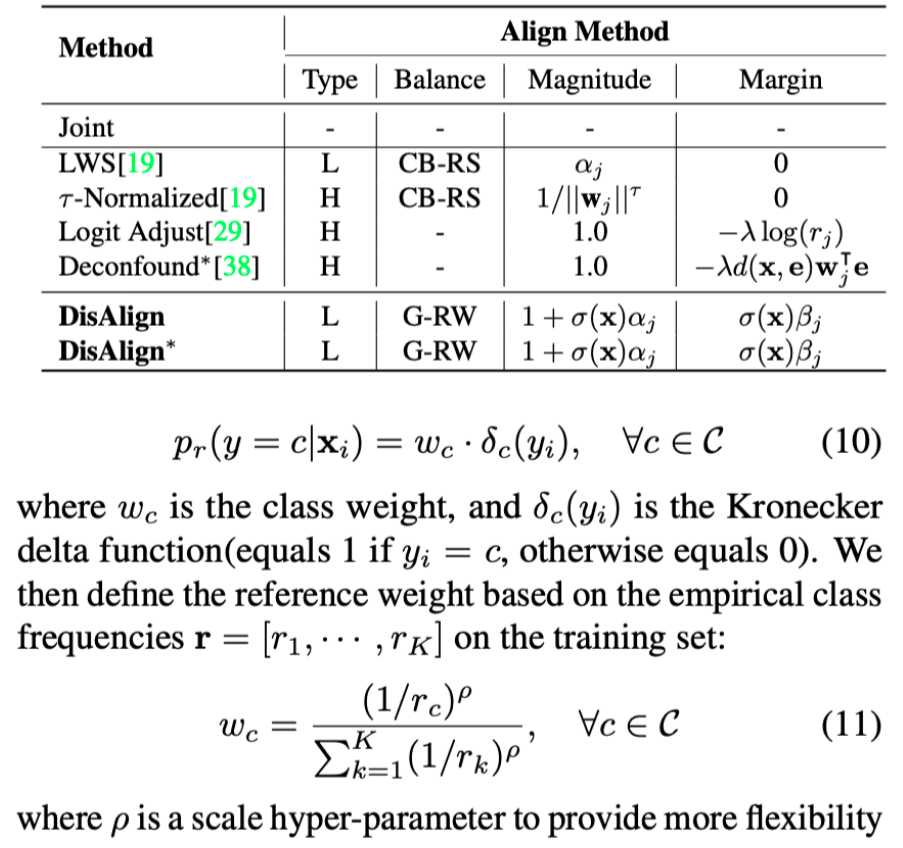
Distribution Alignment: A Unified Framework for Long-tail Visual Recognition
End-to-End Object Detection with Fully Convolutional Network
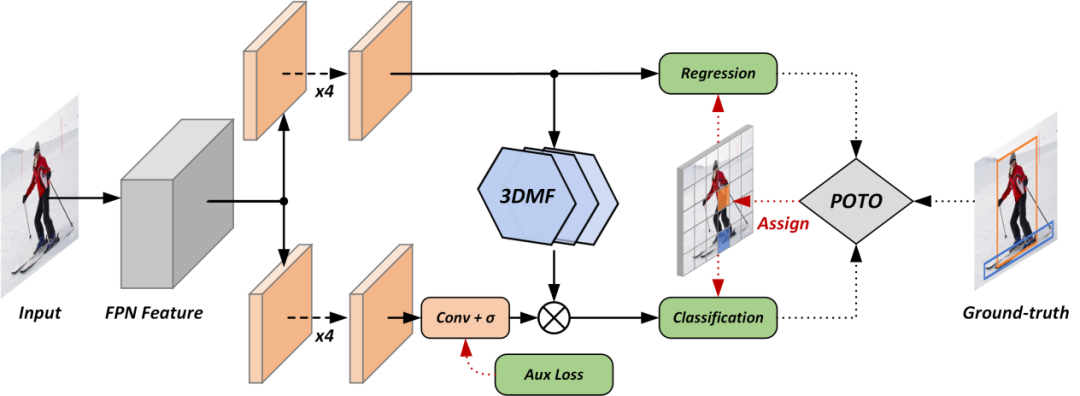
本文首次在全卷积目标检测器上去除了NMS(非极大值抑制)后处理,做到了端到端训练。我们分析了主流一阶段目标检测方法,并发现传统的一对多标签分配策略是这些方法依赖NMS的关键,并由此提出了预测感知的一对一标签分配策略。此外,为了提升一对一标签分配的性能,我们提出了增强特征表征能力的模块,和加速模型收敛的辅助损失函数。我们的方法在无NMS的情况下达到了与主流一阶段目标检测方法相当的性能。在密集场景上,我们的方法的召回率超过了依赖NMS的目标检测方法的理论上限。
👉关键词:端到端检测,标签分配,全卷积网络
https://arxiv.org/abs/2012.03544
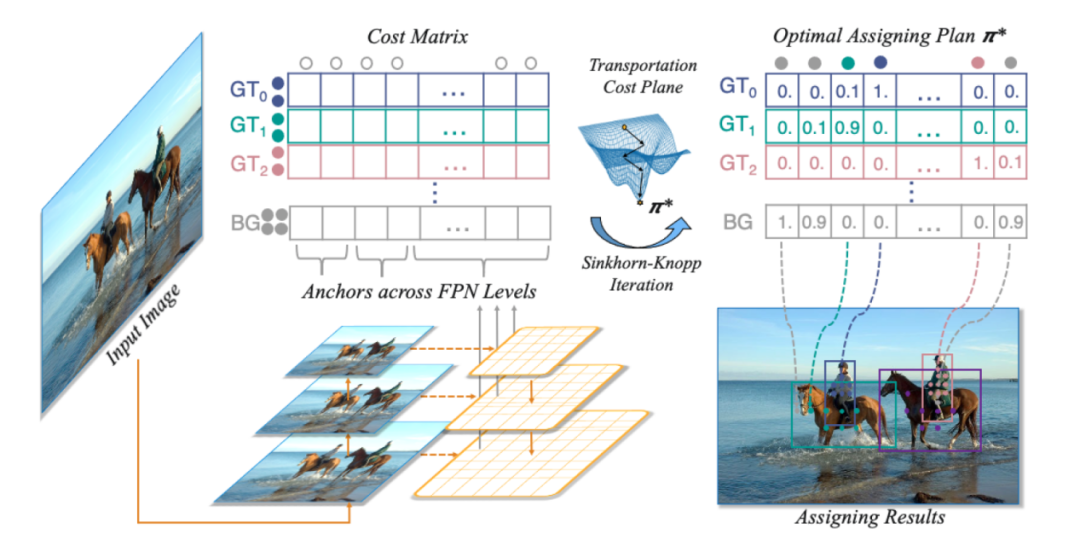
OTA: Optimal Transport Assignment for Object Detection
IQDet: Instance-wise Quality Distribution Sampling for Object Detection
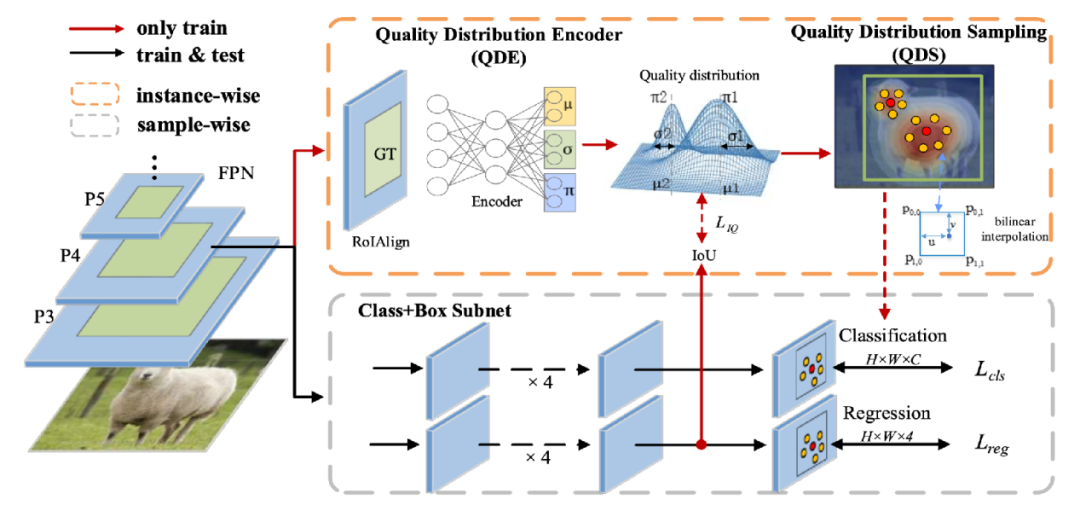
由于一阶段检测器的标签分配有静态、没有考虑目标框的全局信息等不足,我们提出了一种基于目标质量分布采样的目标检测器。在本文中,我们提出质量分布编码模块QDE和质量分布采样模块QDS,通过提取目标框的区域特征,并基于高斯混合模型来对预测框的质量分布进行建模,来动态的选择检测框的正负样本分配。本方法只涉及训练阶段标签分配,就可以在COCO等多个数据集上实现当前最佳结果。
👉关键词:标签分配
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding
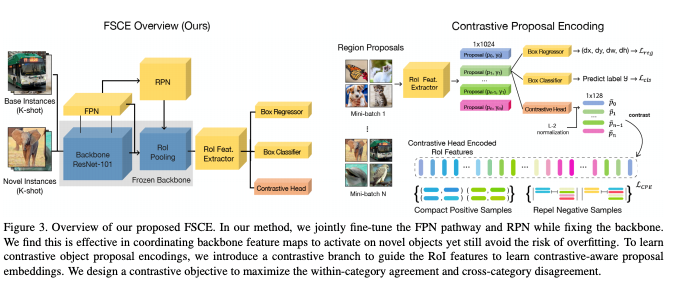 👉关键词:小样本目标检测,对比学习
👉关键词:小样本目标检测,对比学习 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的,文章版权归原作者所有。如有不妥,请联系删除。