
Tomcat 架构设计 25 年后依旧能打!我学到了什么?

点击上方蓝字关注我


你好,我是码哥,可以叫我靓仔。是一个拥抱硬核技术和对象,面向人民币编程的男人。友情提示:阅读本文前需要对 Tomcat 有一个全局架构认识,可先翻阅《Tomcat 架构深度解析》。
Tomcat 是 Sun 公司在 1998 年开发的。 当时开发 Tomcat 的目标是成为 Sun 公司的 Java Servlet 和 JSP 规范的参考实现。
如今已经成为业务开发首选的 Web 应用服务器,Spring Boot 直接将 Tomcat 内置作为 Web 应用启动,二十五年宝刀未老。 其中的架构设计思维值得我们深入学习和借鉴。
码哥今天带你深入探究,学会借鉴 Tomcat 的设计思想在工作中做好架构设计。
在 Tomcat 架构解析到设计思想借鉴 中我们学到 Tomcat 的总体架构,学会从宏观上怎么去设计一个复杂系统,怎么设计顶层模块,以及模块之间的关系;
Tomcat 实现的 2 个核心功能:
- 处理
Socket连接,负责网络字节流与Request和Response对象的转化。 - 加载并管理
Servlet,以及处理具体的Request请求。
所以 Tomcat 设计了两个核心组件连接器(Connector)和容器(Container),连接器负责对外交流,容器负责内部处理。
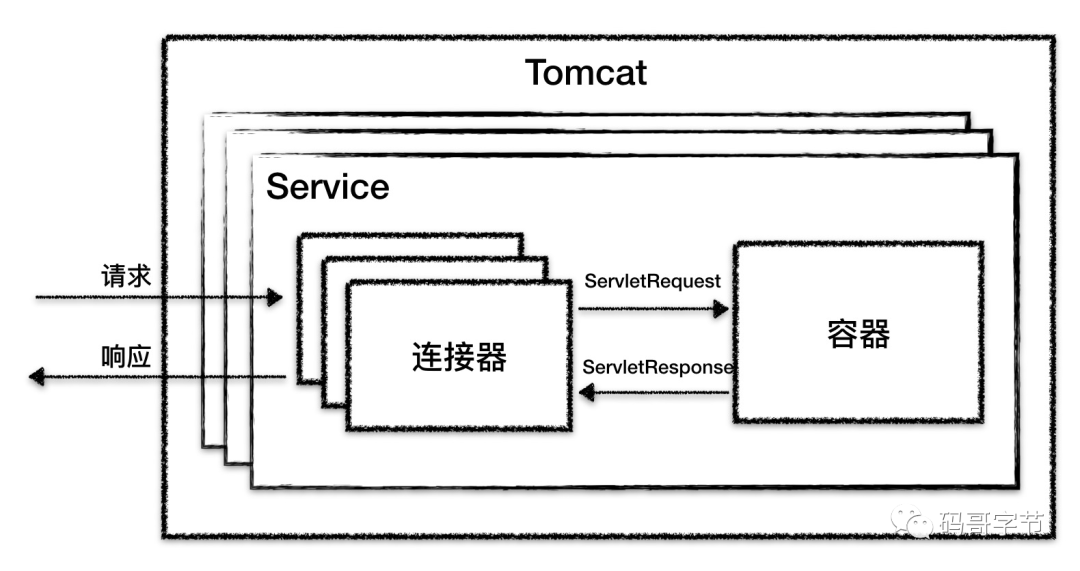 Tomcat整体架构
Tomcat整体架构
管理组件,运筹帷幄
本篇作为 Tomcat 系列的第三篇,带大家体会 Tomcat 是如何构建的?每个组件如何管理组件的?连接器和容器是如何被启动和管理的?
Tomcat 启动流程:startup.sh -> catalina.sh start ->java -jar org.apache.catalina.startup.Bootstrap.main()
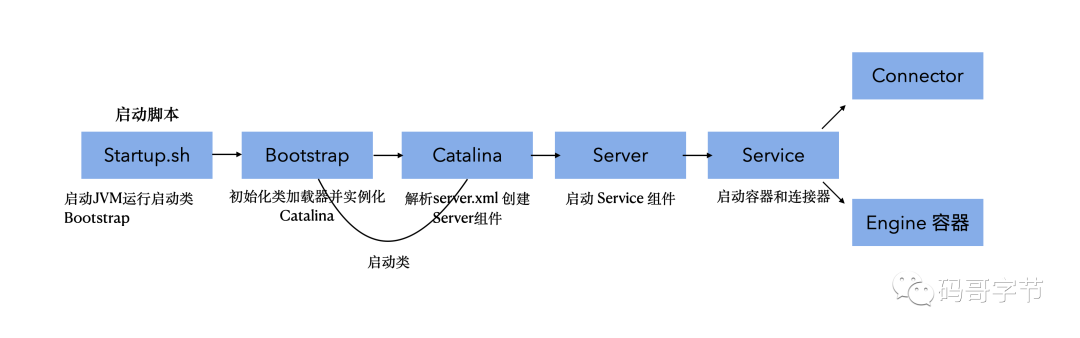 Tomcat 启动流程
Tomcat 启动流程
Bootstrap、Catalina、Server、Service、 Engine 都承担了什么责任?
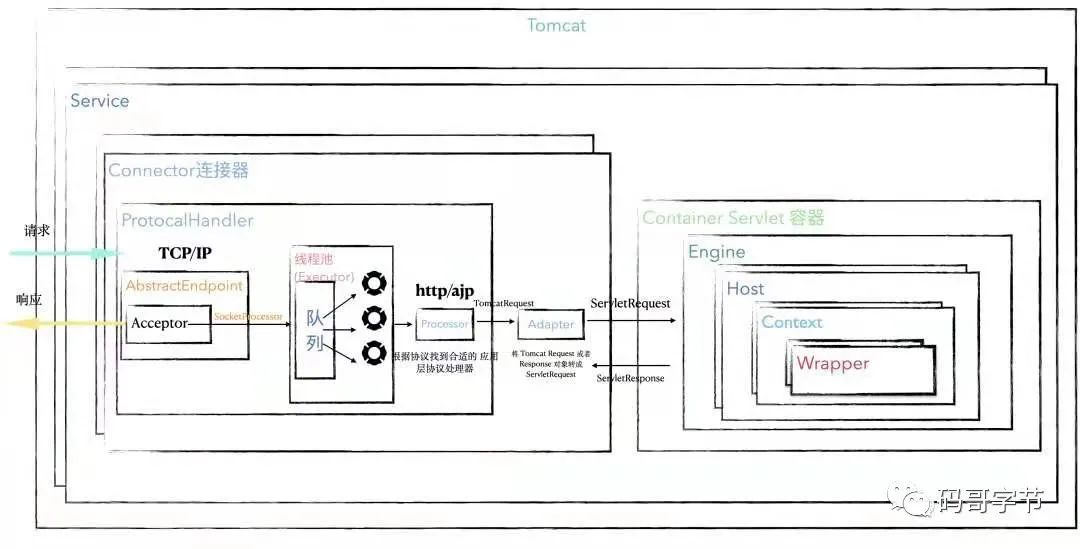
单独写一篇介绍他们是因为你可以看到这些启动类或者组件不处理具体请求,它们的任务主要是管理,管理下层组件的生命周期,并且给下层组件分配任务,也就是把请求路由到负责干活儿的组件。
他们就像一个公司的高层,管理整个公司的运作,将任务分配给专业的人。
我们在设计软件系统中,不可避免地会遇到需要一些管理作用的组件,就可以学习和借鉴 Tomcat 是如何抽象和管理这些组件的。
Bootstrap
当执行 startup.sh 脚本的时候,就会启动一个 JVM 运行 Tomcat 的启动类 Bootstrap 的 main 方法。
先看下他的成员变量窥探核心功能:
public final class Bootstrap {
ClassLoader commonLoader = null;
ClassLoader catalinaLoader = null;
ClassLoader sharedLoader = null;
}
它的主要任务就是初始化 Tomcat 定义的类加载器,同时创建 Catalina 对象。
Bootstrap 犹如女娲,女娲造人,它初始化了类加载器,加载万物。
关于为何自定义各种类加载器详情请查看码哥的 Tomcat 架构设计解析 类加载器部分。
初始化类加载器
如何WebAppClassLoader
假如我们在 Tomcat 中运行了两个 Web 应用程序,两个 Web 应用中有同名的 Servlet,但是功能不同,Tomcat 需要同时加载和管理这两个同名的 Servlet类,保证它们不会冲突,因此 Web 应用之间的类需要隔离。
Tomcat 的解决方案是自定义一个类加载器 WebAppClassLoader, 并且给每个 Web 应用创建一个类加载器实例。
我们知道,Context 容器组件对应一个 Web 应用。因此,每个 Context容器负责创建和维护一个 WebAppClassLoader加载器实例。
这背后的原理是,不同的加载器实例加载的类被认为是不同的类,即使它们的类名相同。
Tomcat 的自定义类加载器 WebAppClassLoader打破了双亲委托机制,它首先自己尝试去加载某个类,如果找不到则通过 ExtClassLoader 加载 JRE 核心类防止黑客攻击,无法加载再代理给 AppClassLoader 加载器,其目的是优先加载 Web 应用自己定义的类。
具体实现就是重写 ClassLoader的两个方法:findClass和 loadClass。
SharedClassLoader
假如两个 Web 应用都依赖同一个第三方的 JAR 包,比如 Spring,那 Spring的 JAR 包被加载到内存后,Tomcat要保证这两个 Web 应用能够共享,也就是说 Spring的 JAR 包只被加载一次。
SharedClassLoader 就是 Web 应用共享的类库的加载器,专门加载 Web 应用共享的类。
如果 WebAppClassLoader自己没有加载到某个类,就会委托父加载器 SharedClassLoader去加载这个类,SharedClassLoader会在指定目录下加载共享类,之后返回给 WebAppClassLoader,这样共享的问题就解决了。
CatalinaClassloader
如何隔离 Tomcat 本身的类和 Web 应用的类?
要共享可以通过父子关系,要隔离那就需要兄弟关系了。
兄弟关系就是指两个类加载器是平行的,它们可能拥有同一个父加载器,基于此 Tomcat 又设计一个类加载器 CatalinaClassloader,专门来加载 Tomcat 自身的类。
这样设计有个问题,那 Tomcat 和各 Web 应用之间需要共享一些类时该怎么办呢?
老办法,还是再增加一个 CommonClassLoader,作为 CatalinaClassloader和 SharedClassLoader 的父加载器。
CommonClassLoader能加载的类都可以被 CatalinaClassLoader和 SharedClassLoader 使用。
Catalina
Catalina 就好像是一个帝王,管理天下。就是它创建 Server 以及所有子组件。
Catalina 的主要任务就是创建 Server,解析 server.xml 把里面配置的各个组件创建出来,并调用每个组件的 init和 start方法,将整个 Tomcat 启动,这样整个帝国就在正常运作了。
我们可以根据 Tomcat 配置文件来直观感受下:
<Server port="8005" shutdown="SHUTDOWN"> // 顶层组件,可包含多个 Service,代表一个 Tomcat 实例
<Service name="Catalina"> // 顶层组件,包含一个 Engine ,多个连接器
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- Define an AJP 1.3 Connector on port 8009 -->
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> // 连接器
// 容器组件:一个 Engine 处理 Service 所有请求,包含多个 Host
<Engine name="Catalina" defaultHost="localhost">
// 容器组件:处理指定Host下的客户端请求, 可包含多个 Context
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
// 容器组件:处理特定 Context Web应用的所有客户端请求
<Context></Context>
</Host>
</Engine>
</Service>
</Server>
作为帝王,Catalina 还需要处理国家的各种异常情况,比如有人抢公章(执行了 Ctrl + C 关闭 Tomcat)。
Tomcat 要如何清理资源呢?
通过向 JVM 注册一个「关闭钩子」,具体关键逻辑详见
org.apache.catalina.startup.Catalina#start 源码:
- Server 不存在则解析
server.xml创建; - 创建失败则报错;
- 启动 Server;
- 创建并注册「关闭钩子」;
- await 方法监听停止请求。
/**
* Start a new server instance.
*/
public void start() {
// 如果 Catalina 持有的 Server 为空则解析 server.xml 创建
if (getServer() == null) {
load();
}
if (getServer() == null) {
log.fatal("Cannot start server. Server instance is not configured.");
return;
}
// Start the new server
try {
getServer().start();
} catch (LifecycleException e) {
// 省略部分代码
}
// 创建钩子并注册
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
}
// 监听停止请求,内部调用 Server 的 stop
if (await) {
await();
stop();
}
}
当我们需要在 JVM 关闭做一些清理工作,比如将缓存数据刷到磁盘或者清理一些文件,就可以向 JVM 注册一个「关闭钩子」。
它其实就是一个线程,当 JVM 停止前尝试执行这个线程的 run 方法。
org.apache.catalina.startup.Catalina.CatalinaShutdownHook
protected class CatalinaShutdownHook extends Thread {
@Override
public void run() {
try {
if (getServer() != null) {
Catalina.this.stop();
}
} catch (Throwable ex) {
// 省略部分代码....
}
}
}
其实就是执行了 Catalina 的 stop 方法,通过它将整个 Tomcat 停止。
Server
Server 组件的职责就是管理 Service 组件,负责调用持有的 Service 的 start 方法。
他就像是帝国的丞相,负责管理多个事业部,每个事业部就是一个 Service。
它管理两个部门:
- Connector 连接器:对外市场营销部,推广吹牛写 PPT 的。
- Container 容器:研发部门,没有性生活的 996 社畜 。
实现类是 org.apache.catalina.core.StandardServer,Server 继承 org.apache.catalina.util.LifecycleMBeanBase,所以他的生命周期也被统一管理,Server 的子组件是 Service,所以还需要管理 Service 的生命周期。
也就是说在启动和关闭 Server 的时候会分别先调用 Service 的 启动和停止方法。
这就是设计思想呀,抽象出生命周期 Lifecycle 接口,体现出接口隔离原则,将生命周期的相关功能内聚。
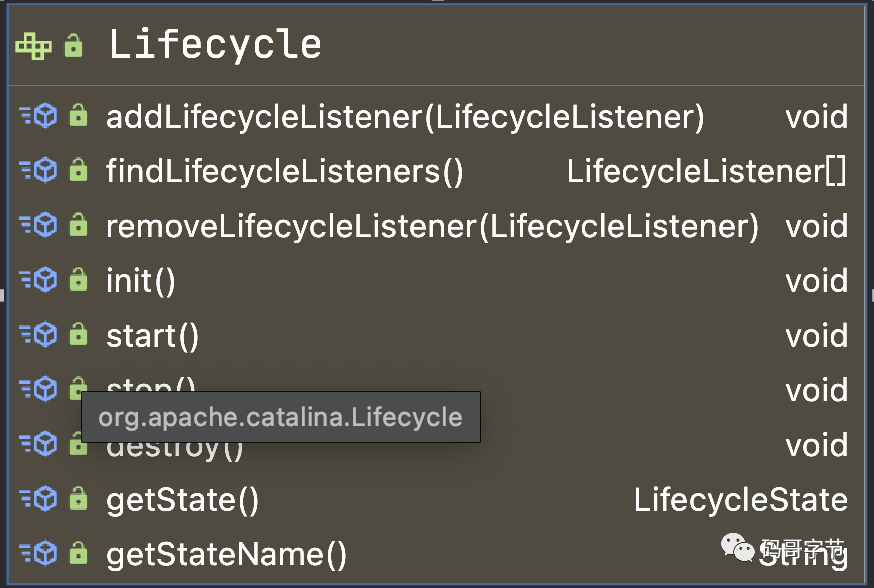
我们接着看 Server 如何管理 Service 的,核心源码如下 org.apache.catalina.core.StandardServer#addService:
public void addService(Service service) {
service.setServer(this);
synchronized (servicesLock) {
// 创建 长度 +1 的数组
Service results[] = new Service[services.length + 1];
// 将旧的数据复制到新数组
System.arraycopy(services, 0, results, 0, services.length);
results[services.length] = service;
services = results;
// 启动 Service 组件
if (getState().isAvailable()) {
try {
service.start();
} catch (LifecycleException e) {
// Ignore
}
}
// 发送事件
support.firePropertyChange("service", null, service);
}
}
在添加 Service 过程中动态拓展数组长度,为了节省内存。
除此之外,Server 组件还有一个重要的任务是启动一个 Socket 来监听停止端口,这就是为什么你能通过 shutdown 命令来关闭 Tomcat。
不知道你留意到没有,上面 Caralina 的启动方法的最后一行代码就是调用了 Server 的 await 方法。
在 await 方法里会创建一个 Socket 监听 8005 端口,并在一个死循环里接收 Socket 上的连接请求,如果有新的连接到来就建立连接,然后从 Socket 中读取数据;如果读到的数据是停止命令“SHUTDOWN”,就退出循环,进入 stop 流程。
Service
他的职责就是管理 Connector 连接器 和 顶层容器 Engine,会分别调用他们的 start 方法。至此,整个 Tomcat 就算启动完成了。
Service 就是事业部的话事人,管理两个职能部门对外推广部(连接器),对内研发部(容器)。
Service 组件的实现类是org.apache.catalina.core.StandardService,直接看关键的成员变量。
public class StandardService extends LifecycleMBeanBase implements Service {
// 名字
private String name = null;
// 所属的 Server 实例
private Server server = null;
// 连接器数组
protected Connector connectors[] = new Connector[0];
private final Object connectorsLock = new Object();
// 对应的 Engine 容器
private Engine engine = null;
// 映射器及其监听器
protected final Mapper mapper = new Mapper();
protected final MapperListener mapperListener = new MapperListener(this);
}
继承 LifecycleMBeanBase 而 LifecycleMBeanBase 又继承 LifecycleBase,这里实际上是模板方法模式的运用,org.apache.catalina.util.LifecycleBase#init,org.apache.catalina.util.LifecycleBase#start,org.apache.catalina.util.LifecycleBase#stop 分别是对应的模板方法,内部定义了整个算法流程,子类去实现自己内部具体变化部分,将变与不变抽象出来实现开闭原则设计思路。
那为什么还有一个 MapperListener?这是因为 Tomcat 支持热部署,当 Web 应用的部署发生变化时,Mapper 中的映射信息也要跟着变化,MapperListener 就是一个监听器,它监听容器的变化,并把信息更新到 Mapper 中,这是典型的观察者模式。
作为“管理”角色的组件,最重要的是维护其他组件的生命周期。
此外在启动各种组件时,要注意它们的依赖关系,也就是说,要注意启动的顺序。我们来看看 Service 启动方法:
protected void startInternal() throws LifecycleException {
//1. 触发启动监听器
setState(LifecycleState.STARTING);
//2. 先启动 Engine,Engine 会启动它子容器
if (engine != null) {
synchronized (engine) {
engine.start();
}
}
//3. 再启动 Mapper 监听器
mapperListener.start();
//4. 最后启动连接器,连接器会启动它子组件,比如 Endpoint
synchronized (connectorsLock) {
for (Connector connector: connectors) {
if (connector.getState() != LifecycleState.FAILED) {
connector.start();
}
}
}
}
这里启动顺序也很讲究,Service 先启动了 Engine 组件,再启动 Mapper 监听器,最后才是启动连接器。
这很好理解,因为内层组件启动好了才能对外提供服务,产品没做出来,市场部也不能瞎忽悠,研发好了才能启动外层的连接器组件。
而 Mapper 也依赖容器组件,容器组件启动好了才能监听它们的变化,因此 Mapper 和 MapperListener 在容器组件之后启动。
组件停止的顺序跟启动顺序正好相反的,也是基于它们的依赖关系。
Engine
他是最顶层的容器组件。继承 Container,所有的容器组件都继承 Container,这里实际上运用了组合模式统一管理。
他的实现类是 org.apache.catalina.core.StandardEngine,继承 ContainerBase。
public class StandardEngine extends ContainerBase implements Engine {
}
他的子容器是 Host,所以持有 Host 容器数组,这个属性每个容器都会存在,所以放在抽象类中
protected final HashMap<String, Container> children = new HashMap<>();
ContainerBase 用 HashMap 保存了它的子容器,并且 ContainerBase 还实现了子容器的“增删改查”,甚至连子组件的启动和停止都提供了默认实现,比如 ContainerBase 会用专门的线程池来启动子容器。
org.apache.catalina.core.ContainerBase#startInternal
// Start our child containers, if any
Container children[] = findChildren();
List<Future<Void>> results = new ArrayList<>();
for (Container child : children) {
results.add(startStopExecutor.submit(new StartChild(child)));
}
Engine 在启动 Host 子容器时就直接重用了这个方法。
容器组件最重要的功能是处理请求,而 Engine 容器对请求的“处理”,其实就是把请求转发给某一个 Host 子容器来处理,具体是通过 Valve 来实现的。
每一个容器组件都有一个 Pipeline,而 Pipeline 中有一个基础阀(Basic Valve),透过构造方法创建 Pipeline。
public StandardEngine() {
super();
pipeline.setBasic(new StandardEngineValve());
// 省略部分代码
}
Engine 容器的基础阀定义如下:
final class StandardEngineValve extends ValveBase {
public final void invoke(Request request, Response response)
throws IOException, ServletException {
// 拿到请求中的 Host 容器
Host host = request.getHost();
if (host == null) {
return;
}
// 调用 Host 容器中的 Pipeline 中的第一个 Valve
host.getPipeline().getFirst().invoke(request, response);
}
}
这个基础阀实现非常简单,就是把请求转发到 Host 容器。
从代码中可以看到,处理请求的 Host 容器对象是从请求中拿到的,请求对象中怎么会有 Host 容器呢?
这是因为请求到达 Engine 容器中之前,Mapper 组件已经对请求进行了路由处理,Mapper 组件通过请求的 URL 定位了相应的容器,并且把容器对象保存到了请求对象中。
今天的知识就分享到这,想要拥抱硬核技术和对象,面向人民币编程就关注公众号「码哥字节」设置星标。
最后,点赞加关注,求支持。加我微信备注「加群」,进入专属技术群一起飞。
往期推荐

点分享

点收藏

点点赞

点在看