
Python批量下载 抖音无水印视频
作者 | 我被狗咬了
来源 | Python乱炖
导读:本文介绍了如何使用简单的Python爬虫爬取抖音上你喜欢的拍客的所有视频(包含有水印和无水印两种)。代码已上传至公众号后台,回复:抖音 即可获得。

一、获取你喜欢的拍客的视频url
1. 获取主页链接
打开抖音,点进用户的主页面,点击右上角的三个点:
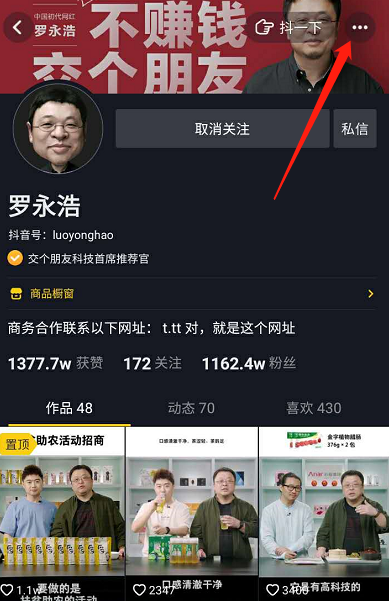
选择分享:
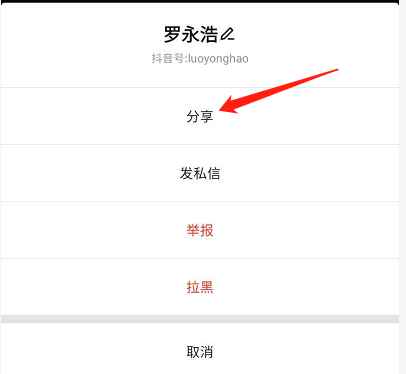
再点击复制链接即可,我们可以获取如下url:
https://v.douyin.com/JJ8b6Hq/
2. 获取重定向链接
我们只需要将上面这个链接粘贴到chrome浏览器,就可以获取到重定向链接
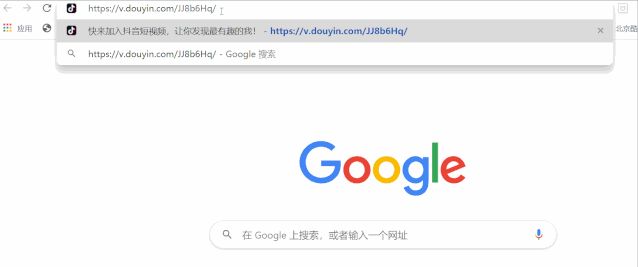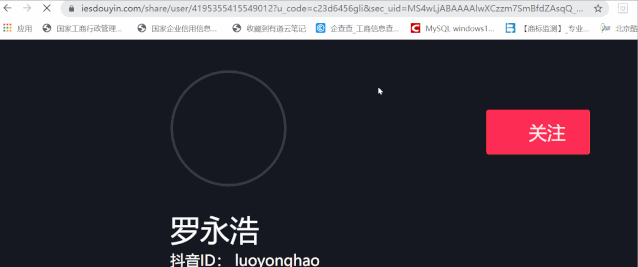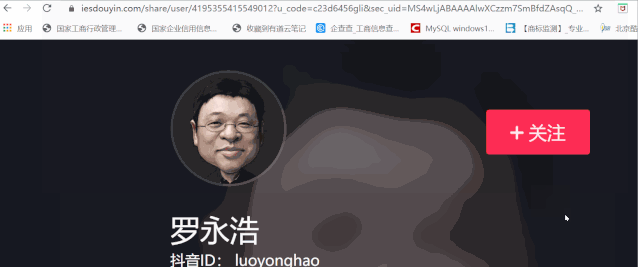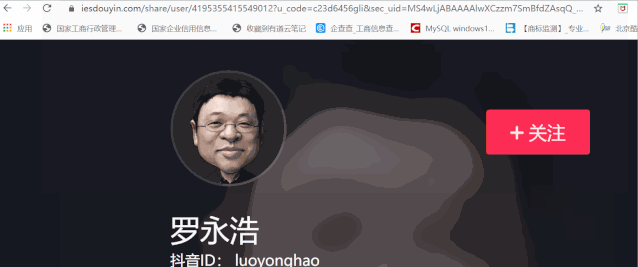
重定向后的链接:
https://www.iesdouyin.com/share/user/4195355415549012?u_code=c23d6456gli&sec_uid=MS4wLjABAAAAlwXCzzm7SmBfdZAsqQ_wVVUbpTvUSX1WC_x8HAjMa3gLb88-MwKL7s4OqlYntX4r×tamp=1590603009&utm_source=copy&utm_campaign=client_share&utm_medium=android&share_app_name=douyin
现在我们需要记住url中/user后面的一串数字,也就是4195355415549012,这是我们的用户id。以后只要有了这样的用户ID,直接替换进url即可(时间戳也需要修改一下)
二、获取用户下面的所有的视频id
我们刚刚获取了视频主页的链接,现在我们要通过主页链接来获取当前页面下的所有视频。为了方便我们观看和调试,我们将Chrome开成iPhone模式。
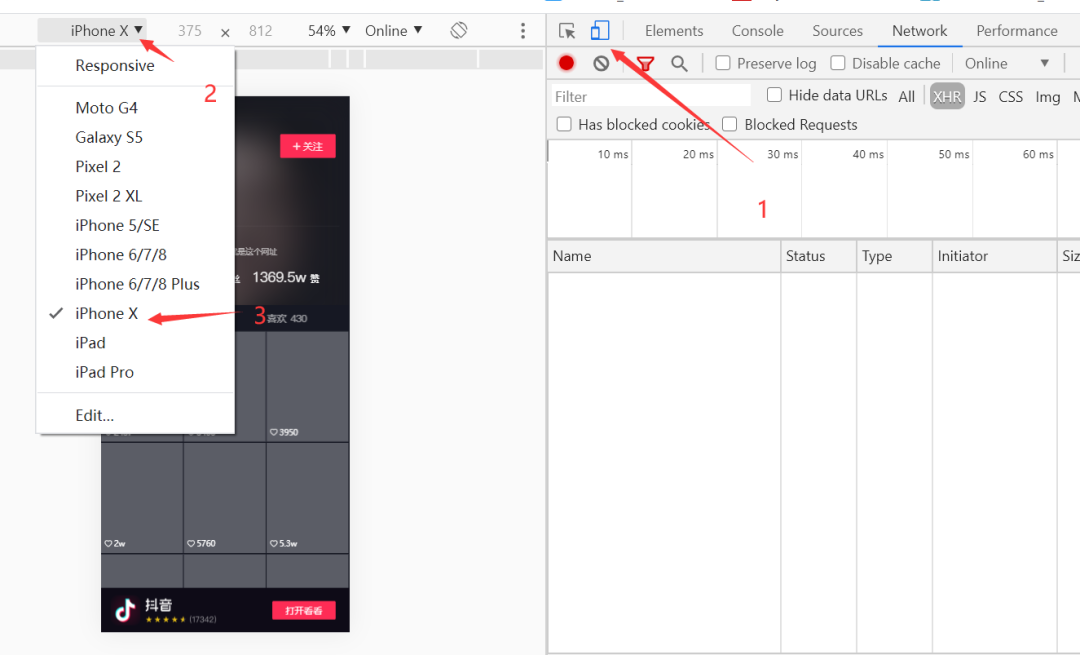
1. 获取请求链接
将Network设置成XHR,重新刷新一下页面,获取请求内容:
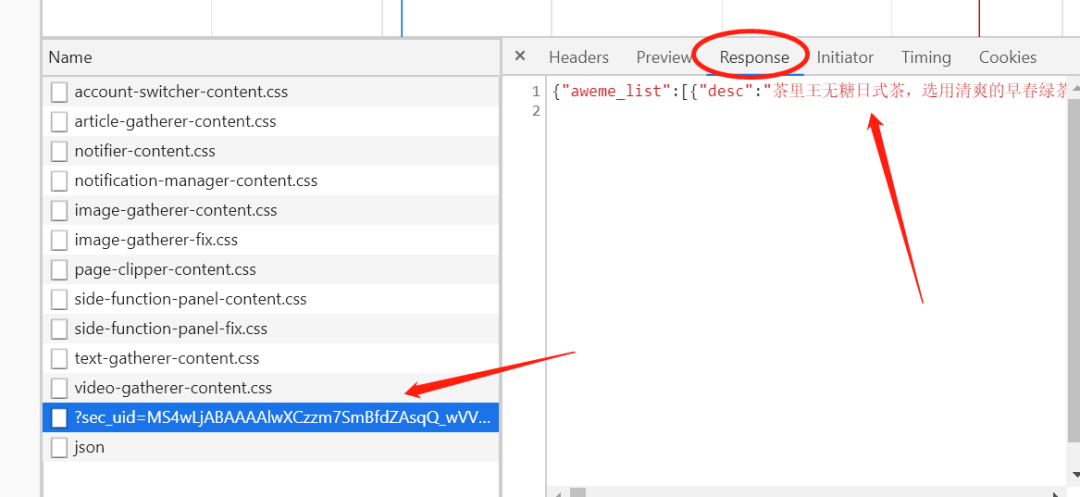
我们可以看到上面选中的那个请求,返回的是一串json,我们将内容复制下来看看,搜索返回的json中有关video的字段,通过下图我们就可以看到video里面有个url_list,里面有两个不同的url,这两个url其实就是视频相关的地址了,但是还有点问题,这两个url点进去并不能直接看到视频。
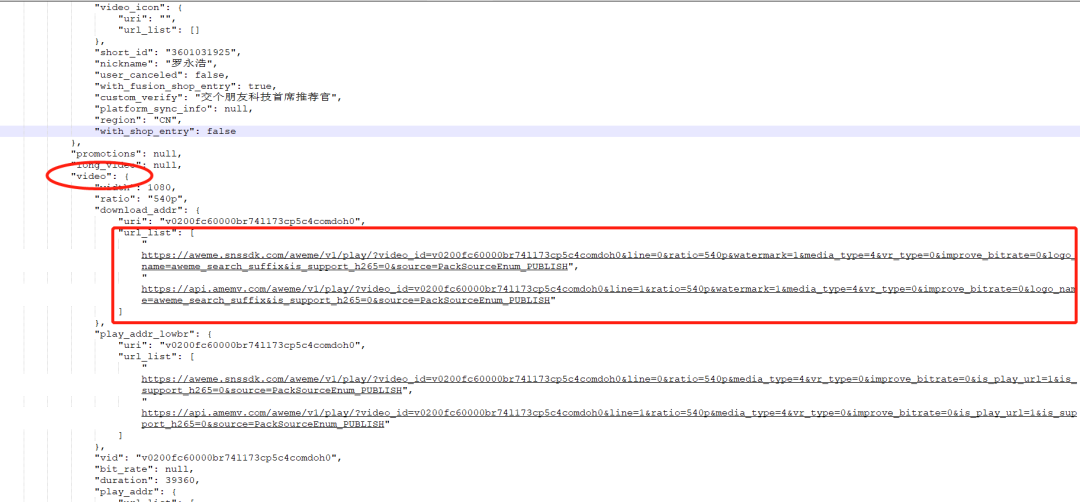
2. 获取视频链接
这里我们需要将url做一点点修改。我们将/play修改成/playmw就可以了,这个时候我们发现,这两个视频地址被重定向成正常的视频地址了。(下面来说为什么要加mw,这个代表什么)
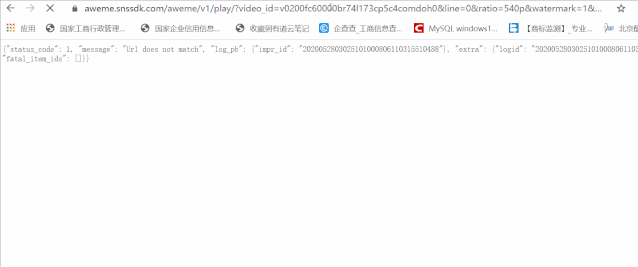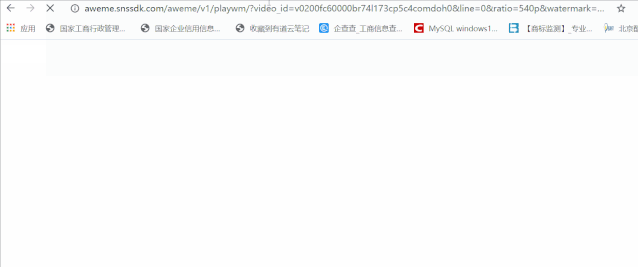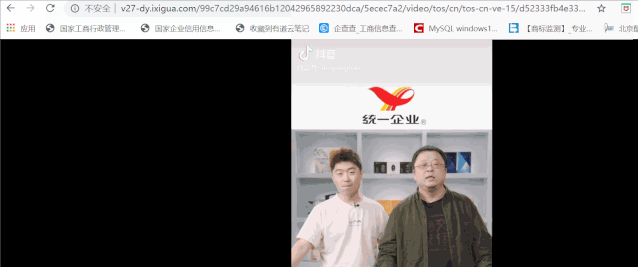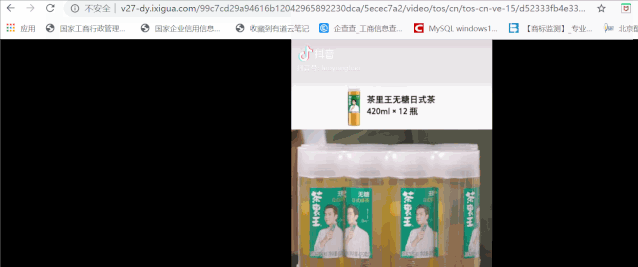
这样我们就相当于顺利拿到视频的地址了,我们可以去json中获取所有的视频url链接:
pattern = re.compile('"(https://aweme.snssdk.com/aweme/v1/play/.*?)"')
result = pattern.findall(data)
result = [i.replace("/play/", "/playwm/") for i in result]
for i in result:
print(i)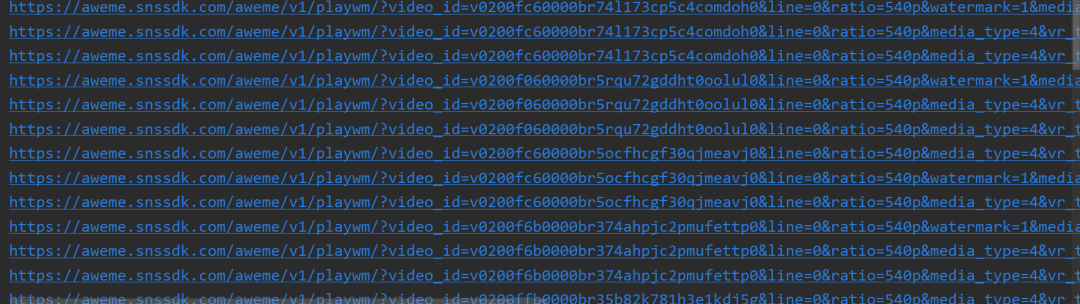
3. 水印问题
关于水印问题,看了简书上有篇文章有介绍,水印与无水印之间的区别,这边我就不作详细介绍了。其实我们一开始拿到的url就是无水印的,但是链接本身并没重定向到无水印的视频,加上wm之后,url会重定向到有水印的视频。
简书参考链接:
https://www.jianshu.com/p/af02f00729c5
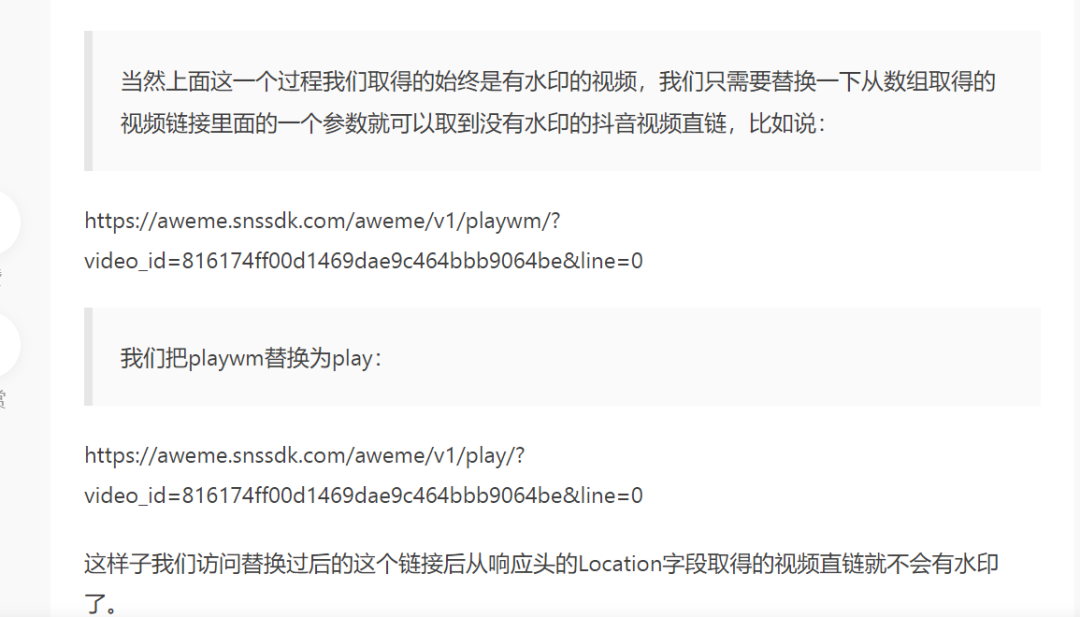
水印链接:
https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200fc60000br74l173cp5c4comdoh0&line=0
无水印链接:
https://aweme.snssdk.com/aweme/v1/play/?video_id=v0200fc60000br74l173cp5c4comdoh0&line=0
(多余的参数忽略,不管他)

三、下载视频
有了视频链接和获取有无水印的方法之后,我们就可以直接下载视频了。
import json
import re
import requests
import os
data = json.dumps(data)
pattern = re.compile('"(https://aweme.snssdk.com/aweme/v1/play/.*?)"')
result = pattern.findall(data)
result = [i.split("&ratio")[0] for i in result]
result2 = [i.replace("/play/", "/playwm/") for i in result]
for i in result:
print(i)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
if not os.path.exists("无水印"):
os.mkdir("无水印")
if not os.path.exists("水印"):
os.mkdir("水印")
count = 0
for res1 in result:
count += 1
videoBin = requests.get(res1, timeout=5, headers=headers)
with open(f'无水印/{count}.mp4', 'wb') as fb:
fb.write(videoBin.content)
count = 0
for res2 in result2:
count += 1
videoBin = requests.get(res2, timeout=5, headers=headers)
with open(f'水印/{count}.mp4', 'wb') as fb:
fb.write(videoBin.content)
关于单个视频下载,如果你想下载某单个无水印视频,可以直接通过分享链接进行下载:
url = "https://v.douyin.com/JJ8kVTc/" # 分享链接
session = requests.Session()
req = session.get(url, timeout=5, headers=HEADERS)
print(req.text)
video = re.findall(r'playAddr: "([\S]*?)"', req.text)[0]
vid = re.findall(r'vid=([\S]*?)&', video)[0]
addr = video.replace("/playwm/", "/play/") # 去除水印
print(addr)
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
}
videoBin = session.get(addr, timeout=5, headers=headers)
with open('test.mp4', 'wb') as fb:
fb.write(videoBin.content)本文首先通过分享链接来获取接口数据,之后在接口数据中查找视频数据,找到视频内容之后再完成视频下载。爬取过程非常的简单,主要就是查找ID会比较吃力。适合爬虫的新手。