
100天搞定机器学习|Day61 手算+可视化,终于彻底理解了 XGBoost
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
我们已经学习了XGBoost渊源及优点、模型原理及优化推导、模型参数解析:100天搞定机器学习|Day60 遇事不决,XGBoost,文章有点太枯燥,大家可能对其中的公式推导和参数还不甚理解。
今天我们以西瓜数据集为例,配合手算,拆开揉碎,深入理解公式与代码之间的内在联系,然后用可视化的方式更形象地看透 XGBoost 的原理!
本文又硬又干,欢迎同学们来个素质三连:在看、收藏、转发,没有关注的同学也来个关注下哈↓↓↓↓↓↓
#本文用到的库
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
from xgboost.sklearn import XGBClassifier
from xgboost import plot_tree
import matplotlib.pyplot as plt
from xgboost import plot_importance
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report, precision_recall_curve
西瓜数据集及预处理
def getDataSet():
dataSet = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, 1],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, 1],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, 1],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, 1],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, 1],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, 1],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, 1],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, 1],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, 0],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, 0],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, 0],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, 0],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, 0],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, 0],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, 0],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, 0],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, 0]
]
features = ['color', 'root', 'knocks', 'texture', 'navel', 'touch', 'density', 'sugar','good']
dataSet = np.array(dataSet)
df = pd.DataFrame(dataSet,columns=features)
for feature in features[0:6]:
le = preprocessing.LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
df.iloc[:,6:8]=df.iloc[:,6:8].astype(float)
df['good']=df['good'].astype(int)
return df
本文中,我们使用sklearn风格的接口,并使用sklearn风格的参数。xgboost.XGBClassifier实现了scikit-learn 的分类模型API:
xgboost.XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100,
silent=True, objective='binary:logistic', booster='gbtree', n_jobs=1,
nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1,
colsample_bytree=1, colsample_bylevel=1, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, base_score=0.5, random_state=0, seed=None,
missing=None, **kwargs)
为方便手算,我们设n_estimators=2,即XGBoost仅2棵树,正则项,系数=1,gamma=0。
#训练模型
df = getDataSet()
X, y = df[df.columns[:-1]],df['good']
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state=0)
sklearn_model_new = XGBClassifier(n_estimators=2,max_depth=5,learning_rate= 0.1, verbosity=1, objective='binary:logistic',random_state=1)
sklearn_model_new.fit(X_train, y_train)
model.fit(X_train, y_train)
XGBoost可视化
现在看一下XGBoost的内部结构,看看树的形状。XGBoost可视化可使用xgboost.plot_tree方法:
xgboost.plot_tree(booster, fmap='', num_trees=0, rankdir='UT', ax=None, **kwargs)
参数:
booster:一个Booster对象, 一个 XGBModel 对象
fmap:一个字符串,给出了feature map 文件的文件名
num_trees:一个整数,制定了要绘制的子数的编号。默认为 0
rankdir:一个字符串,它传递给graphviz的graph_attr
ax:一个matplotlib Axes 对象。特征重要性将绘制在它上面。如果为None,则新建一个Axes
kwargs:关键字参数,用于传递给graphviz 的graph_attr
XGBoost很多函数会用的一个参数fmap (也就是feature map),但是文档里面基本没解释这个fmap是怎么产生的,Kaggle上有好心人提供了解决方案: https://www.kaggle.com/mmueller/xgb-feature-importance-python
def ceate_feature_map(features):
outfile = open('xgb.fmap', 'w')
i = 0
for feat in features:
outfile.write('{0}\t{1}\tq\n'.format(i, feat))
i = i + 1
outfile.close()
ceate_feature_map(df.columns)
这个函数就是根据给定的特征名字(直接使用数据的列名称), 按照特定格式生成一个xgb.fmap文件, 这个文件就是XGBoost文档里面多次提到的fmap, 注意使用的时候, 直接提供文件名, 比如fmap='xgb.fmap'.
有了fmap, 在调用plot_tree函数的时候, 直接指定fmap文件即可:
plot_tree(fmap='xgb.fmap')
调整清晰度需要使用plt.gcf()方法
plot_tree(sklearn_model_new,fmap='xgb.fmap',num_trees=0)
fig = plt.gcf()
fig.set_size_inches(150, 100)
plt.show()
plot_tree(sklearn_model_new,fmap='xgb.fmap',num_trees=1)
fig = plt.gcf()
fig.set_size_inches(150, 100)
plt.show()
重头戏分割线————手算
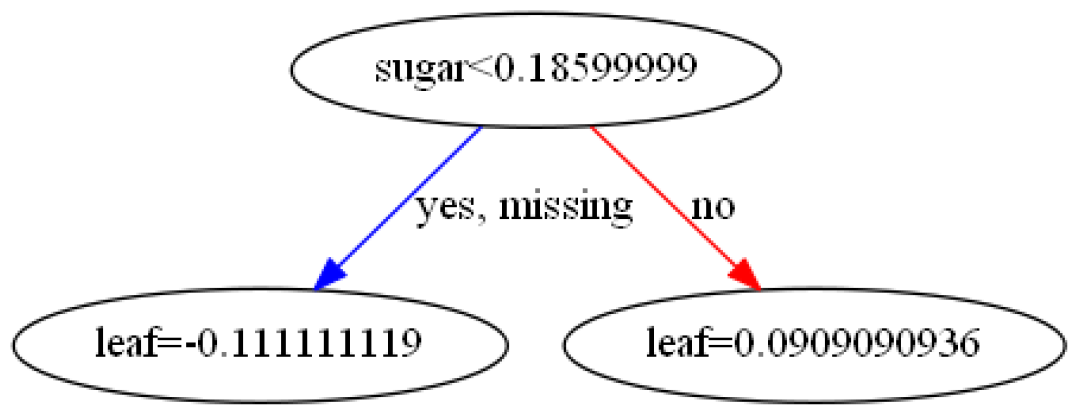
先看看X_train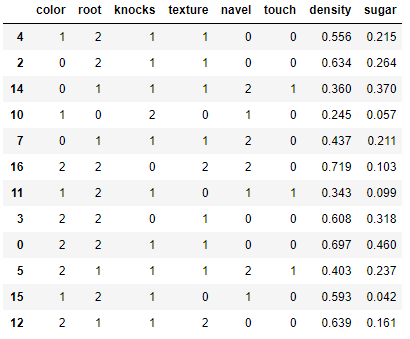 第一棵树仅以含糖率为分割点,对其排序,分割点为两点间的均值
第一棵树仅以含糖率为分割点,对其排序,分割点为两点间的均值

 0.186为何可以成为根节点呢?这个咱们待会儿再算。
0.186为何可以成为根节点呢?这个咱们待会儿再算。
那我们就算一下,不过在此之前还要再复习一下损失函数 logloss:
由于后面需要用到logloss的一阶导数以及二阶导数,这里先简单推导一下。
其中
在一阶导的基础上再求一次有(其实就是sigmod函数求导)
base_score初始值 0.5 ,我们计算每个样本的一阶导数值和二阶导数值
样本的一阶导数值:
样本的二阶导数值:
=2.5
=-2.5
=1.25
=1.75
计算最优的权重:
所以:
=-0.111111111
=0.090909091
tips:上述结果直接计算与图中不符,这里要记得乘以学习率:0.1
第一棵树即为:
回答开头的问题,第一棵树为何以含糖率的0.1856为根节点?必然是所有特征中此处分割的 gain 最大!看一下这个公式
计算结果为5.0505,其他特征的gain小于它,原理类似这里就不挨个算了。
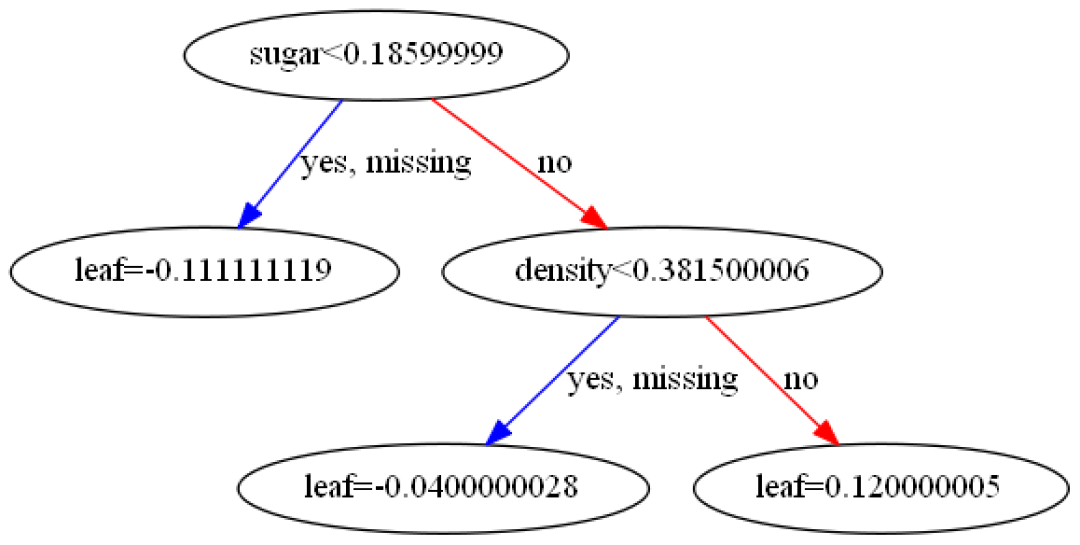
另一个问题,为何分裂到此怎么就停了呢?
XGBClassifier参数min_child_weight默认值 1 ,是叶子节点包含样本的所有二阶偏导数之和,代表子节点的权重阈值。它刻画的是:对于一个叶子节点,当对它采取划分之后,它的所有子节点的权重之和的阈值。如果它的所有子节点的权重之和小于该阈值,则该叶子节点不值得继续分裂。
本例中如再以0.344处或其他特征某处分裂则必有>1,所以就不分裂了。min_child_weight的值较大时,可以避免模型学习到局部的特殊样本。本例如将其值改为0.2,就会发现还会分裂(如下图):
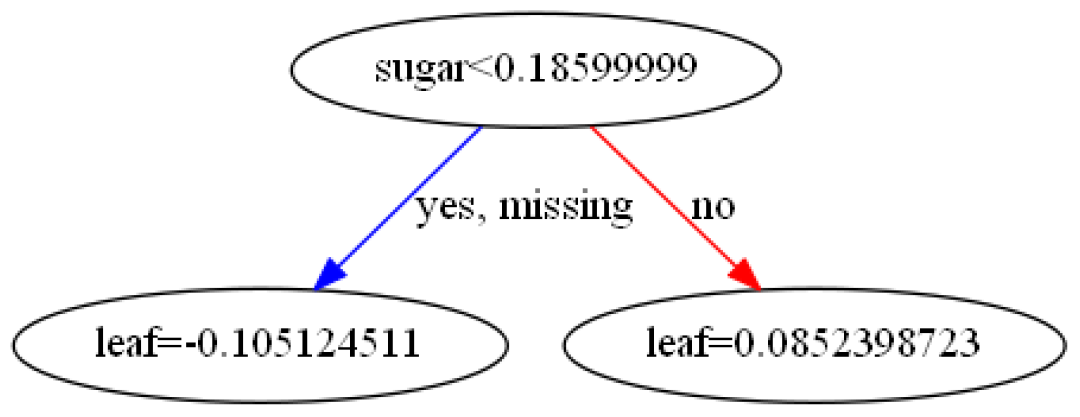
还以min_child_weight默认值为 1,然后,生成第二棵树,此处仅需按第一棵树的预测结果更新base_score的值,注意:预测结果要经过sigmod映射,即当预测为0时,base_score更新为
当预测为0时,base_score更新为
 进一步计算,和,大家可以试一下,结果如图。
进一步计算,和,大家可以试一下,结果如图。
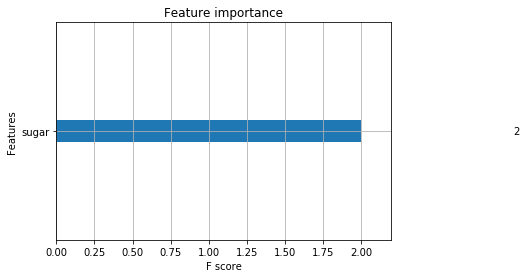
因为我们只有两棵树,特征选择仅使用了含糖率,分裂了两次,so,特征重要性为2
plot_importance(sklearn_model_new)
XGBoost网格搜索调参
参数调整是机器学习中的一门暗艺术,模型的最优参数可以依赖于很多场景。所以要创建一个全面的指导是不可能的。XGBoost使用sklearn风格的接口,并使用网格搜索类GridSeachCV来调参,非常方便。gsCv.best_params_获取最优参数,添加新的参数进来,然后再次GridSearchCV。
也可以一把梭哈,把重要参数一次怼进去。
gsCv = GridSearchCV(sklearn_model_new,
{'max_depth': [4,5,6],
'n_estimators': [5,10,20],
'learning_rate ': [0.05,0.1,0.3,0.5,0.7],
'min_child_weight':[0.1,0.2,0.5,1]
})
gsCv.fit(X_train,y_train)
print(gsCv.best_params_)
{'learning_rate ': 0.05, 'max_depth': 4, 'min_child_weight': 0.1, 'n_estimators': 5} 以此参数重新训练即可。
也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
所以,机器学习和深度学习的区别是什么? 机器学习避坑指南:训练集/测试集分布一致性检查 机器学习深度研究:特征选择中几个重要的统计学概念 老铁,三连支持一下,好吗?↓↓↓