
100天搞定机器学习|Day63 彻底掌握 LightGBM
↓↓↓点击关注,回复资料,10个G的惊喜
100天搞定机器学习|Day61 手算+可视化,终于彻底理解了 XGBoost
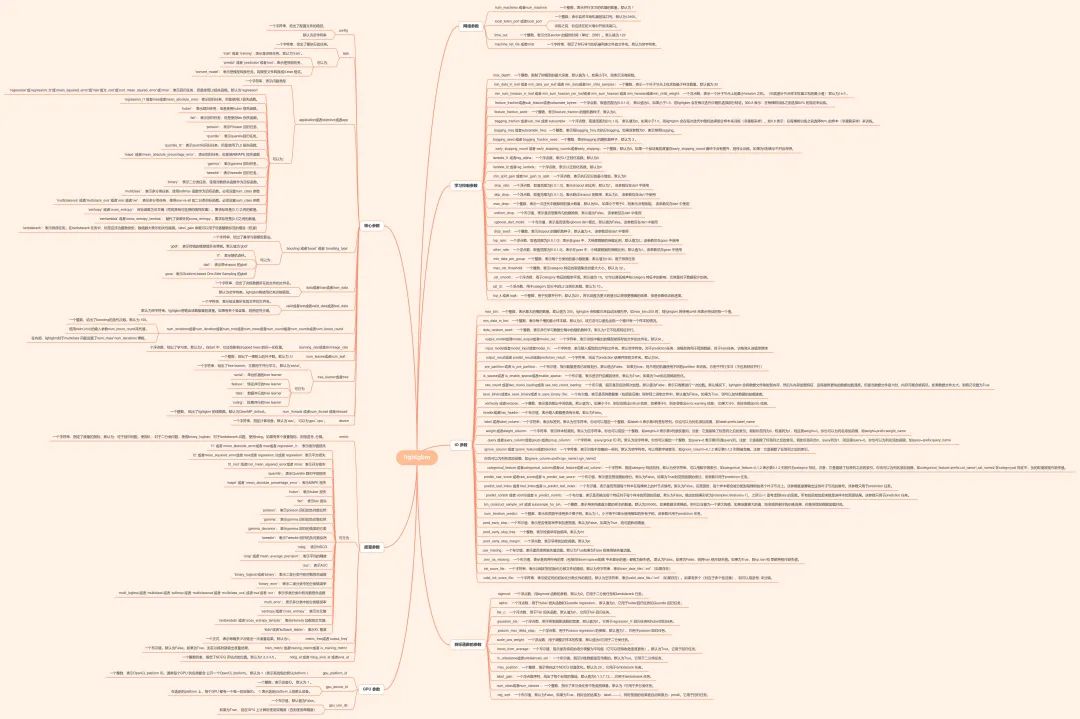
LightGBM
LightGBM 全称为轻量的梯度提升机(Light Gradient Boosting Machine),由微软于2017年开源出来的一款SOTA Boosting算法框架。
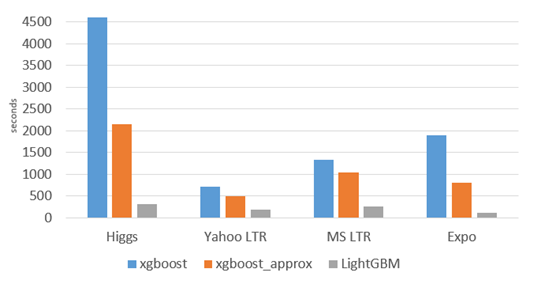
LightGBM 跟XGBoost一样,也是 GBDT 算法框架的一种工程实现,不过更加快速和高效:
更快的训练效率 低内存使用 更高的准确率 支持并行化学习 可处理大规模数据 支持直接使用category特征
LightGBM 模型原理
回顾一下XGBoost 构建决策树的算法基本思想:
首先,对所有特征都按照特征的数值进行预排序。
其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。
最后,找到一个特征的分割点后,将数据分裂成左右子节点。
这样的预排序算法的优点是:能精确地找到分割点。
缺点也很明显:计算量巨大、内存占用巨大、易产生过拟合
LightGBM 在 XGBoost 上主要有3方面的优化:
1,Histogram算法:直方图算法。
2,GOSS算法:基于梯度的单边采样算法。
3,EFB算法:互斥特征捆绑算法。
为方面理解,我们可以认为
LightGBM = XGBoost + Histogram + GOSS + EFB
Hitogram算法的作用是减少候选分裂点数量 GOSS算法的作用是减少样本的数量 EFB算法的作用是减少特征的数量
训练复杂度 = 树的棵数✖️每棵树上叶子的数量✖️生成每片叶子的复杂度
生成一片叶子的复杂度 = 特征数量✖️候选分裂点数量✖️样本的数量
通过这3个算法的引入,LightGBM生成一片叶子需要的复杂度大大降低了,从而极大节约了计算时间。
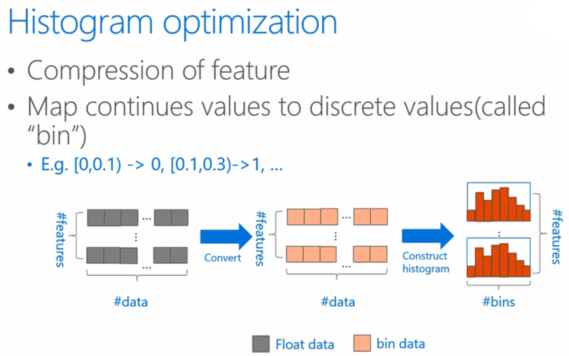
直方图
直方图算法是把连续特征离散化为 k 个整数,也是采用了分箱的思想,不同的是直方图算法根据特征所在的 bin 对其进行梯度累加和个数统计。
在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分裂点。
下例对比 xgboost 的预排序,可以更形象地理解直方图算法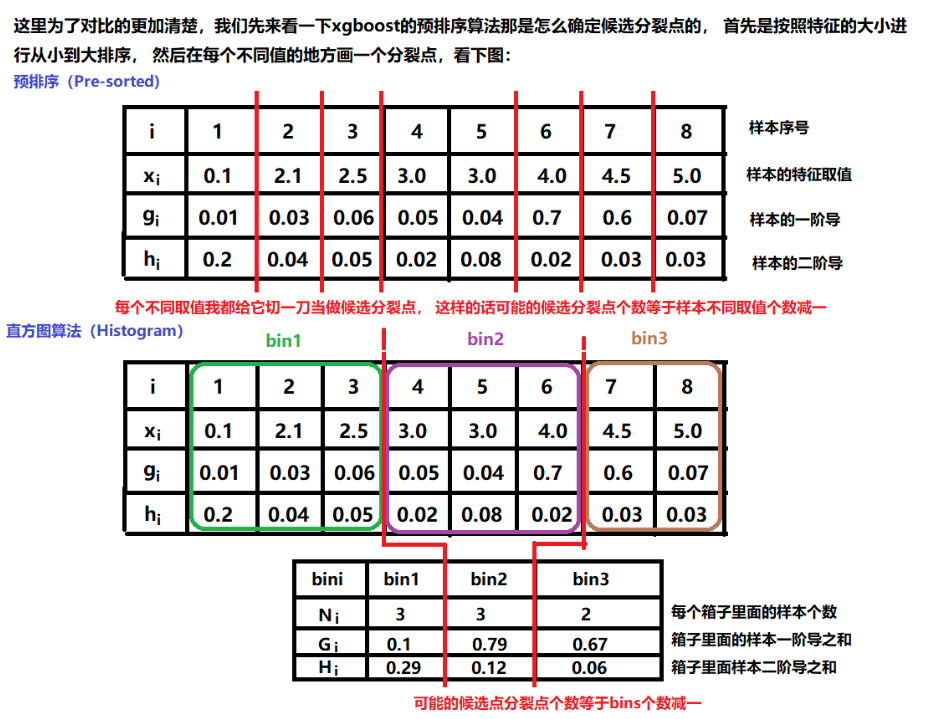
直方图做差
LightGBM 另一个优化是直方图做差加速,一个叶子的直方图可以由它的父亲节点的直方图与它兄弟的直方图做差得到。
利用这个方法,LightGBM可以在构造一个叶子的直方图后,仅需遍历直方图的k个桶,无需遍历该叶子上的所有数据,在速度上可以提升一倍。

Histogram算法并不完美,由于特征被离散化,找到的并不是精确的分割点,所以会对结果产生影响。但在不同的数据集上的结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也有正则化的效果,可以有效地防止过拟合;即使单棵树的训练误差比精确分割的算法稍大,但在梯度提升(Gradient Boosting)的框架下没有太大的影响。
GOSS算法
GOSS是一种在减少数据量和保证精度上平衡的算法。
GOSS是通过区分不同梯度的实例,保留较大梯度实例同时对较小梯度随机采样的方式减少计算量,从而达到提升效率的目的。
为了抵消对数据分布的影响,计算信息增益的时候,GOSS对小梯度的数据引入常量乘数。GOSS首先根据数据的梯度绝对值排序,选取top a个实例。然后在剩余的数据中随机采样b个实例。接着计算信息增益时为采样出的小梯度数据乘以(1-a)/b,这样算法就会更关注训练不足的实例,而不会过多改变原数据集的分布。
 GOSS的算法步骤如下:
GOSS的算法步骤如下:
1、根据数据的梯度绝对值将训练降序排序。
2、保留top a个数据实例,作为样本A。
3、对于剩下的(1-a)%数据,随机抽取b*100%的数据作为样本B。
4、计算信息增益的时候,放大样本B中的梯度(1-a)/b倍
EFB算法
EFB是通过特征捆绑的方式减少特征维度(其实是降维技术)的方式,来提升计算效率。
通常被捆绑的特征都是互斥的(一个特征值为零,一个特征值不为零),这样两个特征捆绑起来才不会丢失信息。
如果两个特征并不是完全互斥(部分情况下两个特征都是非零值),可以用一个指标对特征不互斥程度进行衡量,称之为冲突比率,当这个值较小时,我们可以选择把不完全互斥的两个特征捆绑,而不影响最后的精度。
EFB算法的关键点有两个:
1、如何判定哪些特征可以进行捆绑?
2、特征如何捆绑?捆绑之后的特征值如何计算?
如何判定哪些特征可以捆绑?
EFB 算法利用特征和特征间的关系构造一个加权无向图,并将其转换为图着色算法。图着色是个 NP-Hard 问题,故采用贪婪算法得到近似解,具体步骤如下:
构造一个加权无向图,顶点是特征,边的权重是两个特征的总冲突值,即两个特征上同时不为0的样本个数
根据节点的度进行降序排序,度越大,表示与其他特征的冲突越大
对于每一个特征,通过遍历已有的特征簇(没有则新建一个),如果该特征加入到特征簇中的冲突值不超过某个阈值,则将该特征加入到该簇中。如果该特征不能加入任何一个已有的特征簇,则新建一个簇,并加入该特征。
EFB 算法允许特征并不完全互斥来增加特征捆绑的数量,在具体计算的时候需要设置一个最大互斥率指标γ,一般情况下这个指标设置会相对较小,此时算法的精度和效率之间会有一个最优值。
Greedy bundle 算法的伪代码如下:

上面的过程存在一个缺点:在特征数量特征多的时候,第一步建立加权无向图会影响效率,此时可以直接统计特征之间非零样本的个数,因为非零值越多,互斥的概率会越大。
特征如何捆绑?
Merge Exclusive Features 算法将 bundle 中的特征合并为新的特征,合并的关键是原有的不同特征值在构建后的 bundle 中仍能够识别。
由于基于直方图的方法存储的是离散的 bin 而不是连续的数值,因此可以通过添加偏移的方法将不同的 bin 值设定为不同的区间。
举个例子:特征 A 和特征 B 可以实现特征捆绑,A 特征的原始取值区间是 [0,10) ,B 特征的原始取值是[0,20)。如果直接进行特征值的相加,那么 5 这个值我们不能分清它是出自特征 A 还是特征 B。此时可以给特征 B 加一个偏移量 10 将取值区间转换成 [10,30),这时进行特征捆绑就可以分清来源。
MEF 特征合并算法的伪代码如下:

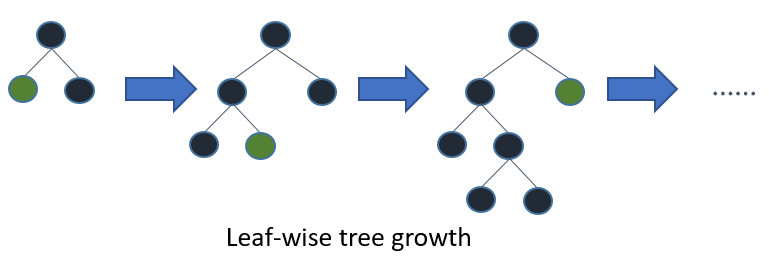
leaf-wise
在Histogram算法之上,LightGBM进行进一步的优化。首先它抛弃了大多数GBDT工具使用的按层生长 (level-wise)的决策树生长策略,而使用了带有深度限制的按叶子生长 (leaf-wise)算法。
leaft-wise 的做法是在当前所有叶子节点中选择分裂收益最大的节点进行分裂,如此递归进行,很明显 leaf-wise 这种做法容易过拟合,因为容易陷入比较高的深度中,因此需要对最大深度做限制,从而避免过拟合。

LightGBM 极简实例
LightGBM两种使用方式,区别不大
1、原生形式使用LightGBM
import LightGBM as lgb
2、Sklearn接口形式使用LightGBM
from LightGBM import LGBMRegressor
下面代码为 Sklearn 接口形式 LightGBM 具体用法,虽说是极简,但完全涵盖模型应用的全部过程。
from LightGBM import LGBMRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
# 划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 模型训练
gbm = LGBMRegressor(objective='regression', num_leaves=31, learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
# 模型存储
joblib.dump(gbm, 'loan_model.pkl')
# 模型加载
gbm = joblib.load('loan_model.pkl')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
# 特征重要度
print('Feature importances:', list(gbm.feature_importances_))
# 网格搜索,参数优化
estimator = LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(X_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
LightGBM调参小技巧
LightGBM 参数很多,但是最常用的不多:
num_leaves:控制了叶节点的数目,控制树模型复杂度的主要参数。 max_depth, default=-1, type=int,树的最大深度限制,防止过拟合 min_data_in_leaf, default=20, type=int, 叶子节点最小样本数,防止过拟合 feature_fraction, default=1.0, type=double, 0.0 < feature_fraction < 1.0,随机选择特征比例,加速训练及防止过拟合 feature_fraction_seed, default=2, type=int,随机种子数,保证每次能够随机选择样本的一致性 bagging_fraction, default=1.0, type=double, 类似随机森林,每次不重采样选取数据 lambda_l1, default=0, type=double, L1正则 lambda_l2, default=0, type=double, L2正则 min_split_gain, default=0, type=double, 最小切分的信息增益值 top_rate, default=0.2, type=double,大梯度树的保留比例 other_rate, default=0.1, type=int,小梯度树的保留比例 min_data_per_group, default=100, type=int,每个分类组的最小数据量 max_cat_threshold, default=32, type=int,分类特征的最大阈值
针对更快的训练速度:
通过设置 bagging_fraction 和 bagging_freq 参数来使用 bagging 方法 通过设置 feature_fraction 参数来使用特征的子抽样 使用较小的 max_bin 使用 save_binary 在未来的学习过程对数据加载进行加速
获取更好的准确率:
使用较大的 max_bin (学习速度可能变慢) 使用较小的 learning_rate 和较大的 num_iterations 使用较大的 num_leaves (可能导致过拟合) 使用更大的训练数据 尝试 dart
缓解过拟合:
使用较小的 max_bin 使用较小的 num_leaves 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf 通过设置 bagging_fraction 和 bagging_freq 来使用 bagging 通过设置 feature_fraction 来使用特征子抽样 使用更大的训练数据 使用 lambda_l1, lambda_l2 和 min_gain_to_split 来使用正则 尝试 max_depth 来避免生成过深的树
总结
最后做个总结,也是面试中最常被问到的:
xgboost和LightGBM的区别和适用场景?
(1)xgboost采用的是level-wise的分裂策略,而lightGBM采用了leaf-wise的策略,区别是xgboost对每一层所有节点做无差别分裂,可能有些节点的增益非常小,对结果影响不大,但是xgboost也进行了分裂,带来了务必要的开销。leaft-wise的做法是在当前所有叶子节点中选择分裂收益最大的节点进行分裂,如此递归进行,很明显leaf-wise这种做法容易过拟合,因为容易陷入比较高的深度中,因此需要对最大深度做限制,从而避免过拟合。
(2)LightGBM使用了基于histogram的决策树算法,这一点不同与xgboost中的 exact 算法,histogram算法在内存和计算代价上都有不小优势。
1)内存上优势:很明显,直方图算法的内存消耗为(#data* #features * 1Bytes)(因为对特征分桶后只需保存特征离散化之后的值),而xgboost的exact算法内存消耗为:(2 * #data * #features* 4Bytes),因为xgboost既要保存原始feature的值,也要保存这个值的顺序索引,这些值需要32位的浮点数来保存。
2)计算上的优势,预排序算法在选择好分裂特征计算分裂收益时需要遍历所有样本的特征值,时间为(#data),而直方图算法只需要遍历桶就行了,时间为(#bin)
(3)直方图做差加速,一个子节点的直方图可以通过父节点的直方图减去兄弟节点的直方图得到,从而加速计算。
(4)LightGBM支持直接输入categorical 的feature,在对离散特征分裂时,每个取值都当作一个桶,分裂时的增益算的是”是否属于某个category“的gain。类似于one-hot编码。
(5)xgboost在每一层都动态构建直方图,因为xgboost的直方图算法不是针对某个特定的feature,而是所有feature共享一个直方图(每个样本的权重是二阶导),所以每一层都要重新构建直方图,而LightGBM中对每个特征都有一个直方图,所以构建一次直方图就够了。
其适用场景根据实际项目和两种算法的优点进行选择。
reference
https://mp.weixin.qq.com/s/i_pHsnwK738d9TTfXOkK8A
https://LightGBM.apachecn.org/#/docs/6
https://mp.weixin.qq.com/s/iPX0PwRnNMmouNfc6OA7SA
https://www.biaodianfu.com/LightGBM.html
http://www.mianshigee.com/question/12398exk/
https://www.cnblogs.com/chenxiangzhen/p/10894306.html
https://www.kaggle.com/prashant111/LightGBM-classifier-in-python
推荐阅读
用Python学线性代数:自动拟合数据分布 Python 用一行代码搞事情,机器学习通吃 Github 上最大的开源算法库,还能学机器学习! JupyterLab 这插件太强了,Excel灵魂附体 终于把 jupyter notebook 玩明白了 一个超好用的 Python 标准库,666 几百本编程中文书籍(含Python)持续更新