
《性能优化》并发与并行
前言
性能优化系列第一篇主要给大家科普了一些性能相关的数字,为大家建立性能的初步概念。第二篇给大家介绍了支撑淘宝双十一这种达到百万QPS项目所需的相关核心技术。
本文带来的是性能优化中的第一利器:并发与并行。
除了核心原理介绍外,我将结合我自身的过去的实战经验,给出一些自己在使用上的建议,希望对大家有帮助。
不多废话,直接开怼。
正文
1、并发和并行?
并发和并行最关键的区别是:并行是同时执行,而并发不是同时。
这边使用 Joe Armstrong 排队使用咖啡机的例子来看并行和并发的区别,如下图所示:
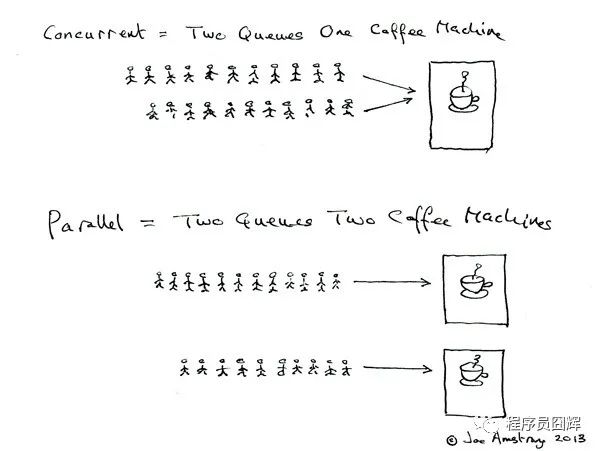
上半部分为并发:两个队伍交替使用咖啡机
下半部分为并行:两个队伍同时使用咖啡机
从和我们更相关的CPU的角度来看两者的区别。
并发是这样的:同一时刻只有一个任务执行。
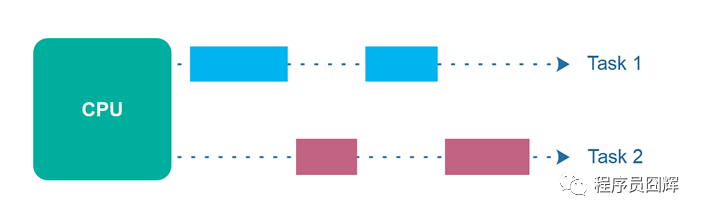
并行是这样的:同一时刻有多个任务执行。
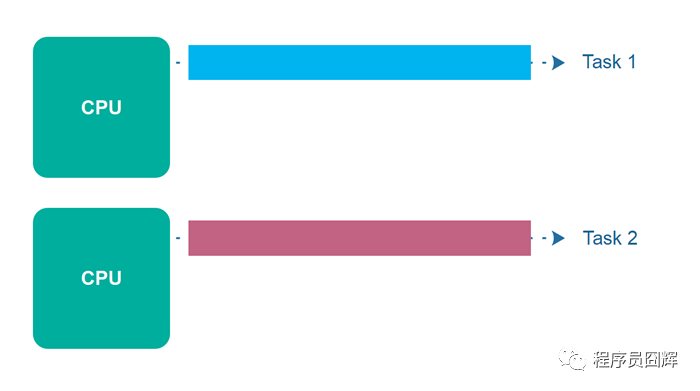
并发和并行结合起来是这样的:

2、并发一定能提升性能吗?
并行能提升性能大家不会有太多的疑问,但是并发是否一定能提升性能,估计还是有不少同学会有疑问。
答案是否定的,并发不一定能提升性能,但是在绝大多数场景都能提升性能。
什么场景下并发不能提升性能?
我们举个简单的例子:假设我们的服务器配置为单核CPU,要执行10个任务,10个任务都是CPU计算密集型任务,此时单线程执行效率理论上要比开10个线程执行要快。
在执行的整个过程中,基本都是CPU在运行,但是开十个线程会涉及到线程上下文切换,需要花费一些时间,导致反而更慢。
再举个更形象的例子:囧辉上语文开小差,被老师罚抄10篇课文,此时囧辉脑子里想到了两种方法。
方法1:先抄完第一篇,再抄第二篇,再抄第三篇,直到抄完第十篇。
方法2:先抄第一篇的第一段,再抄第二篇的第一段,...,再抄第十篇的第一段,再抄第一篇的第二段,直到抄完全部。
方法1为串行执行,方法2为并发执行,相信大家都能很容易看出方法二反而会更慢,因为我们在从切换不同文章时,需要先放好原来的文章,然后找新文章抄到哪个位置了,这个过程需要花费一些时间,这个过程就类似于线程上下文切换。
那什么场景下并发会提升性能了?
再举个例子:囧辉要烧10壶水,一壶水烧开的时间为1分钟。
串行执行:囧辉先烧第一壶,第一壶烧开了后接着烧第二壶,直到烧完第十壶,这个方法烧完十壶水大概需要10分钟。
并发执行:囧辉先烧第一壶,没等第一壶烧开,接着烧第二壶,就这样,囧辉一下子将十壶水都放到灶台上同时烧,这个方法烧完十壶水大概需要1分钟。
在这个场景里,并发执行就体现了很大的优化,性能提升了接近10倍。
在我们实际项目中,大部分应用场景都是第二类,因此并发大多时候能提升性能,而哪些动作是“烧开水”了,这个其实在性能优化第一篇里提到了,最常见的“烧开水”操作就是I/O操作,最常见的如:调用其他服务的RPC接口查询数据、查询MySQL数据库获取数据等等。
3、实现方式
并发/并行的实现方式通常有两种,如下。
1)开线程直接怼,每循环一次都会新建一个线程来执行,例如下面代码,
public static void test() throws InterruptedException {CountDownLatch countDownLatch = new CountDownLatch(10);for (int i = 0; i < 10; i++) {new Thread(() -> {// 烧水boilingWater();countDownLatch.countDown();}).start();}// 等待处理结束countDownLatch.await();}
2)使用线程池,例如下面代码。
public static void test() {List<Future> futureList = new ArrayList<>();for (int i = 0; i < 10; i++) {futureList.add(THREAD_POOL_EXECUTOR.submit(() -> {// 烧开水boilingWater();}));}for (Future future : futureList) {try {// 等待处理结束future.get();} catch (Exception e) {e.printStackTrace();}}}
1是反例,实际项目中不要使用,就算只开1个线程,也要用线程池,因为每次创建和回收线程都是需要开销的。
下面用一个简单的demo来模拟“烧开水”的例子
public class BoilingWaterTest {/*** CPU的核数*/private static final int NCPUS = Runtime.getRuntime().availableProcessors();/*** 创建线程池*/private static final ThreadPoolExecutor THREAD_POOL_EXECUTOR = new ThreadPoolExecutor(NCPUS,NCPUS * 2,30,TimeUnit.MINUTES,new LinkedBlockingDeque<>(1000),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());public static void main(String[] args) throws Exception {serial();concurrent();}public static void serial() {// 串行执行long start = System.currentTimeMillis();for (int i = 0; i < 10; i++) {boilingWater();}System.out.println("serial cost:" + (System.currentTimeMillis() - start));}public static void concurrent() throws InterruptedException {// 并发执行CountDownLatch countDownLatch = new CountDownLatch(10);long start = System.currentTimeMillis();for (int i = 0; i < 10; i++) {THREAD_POOL_EXECUTOR.execute(() -> {boilingWater();countDownLatch.countDown();});}// 等待任务全部执行完毕countDownLatch.await();System.out.println("concurrent cost:" + (System.currentTimeMillis() - start));}public static void boilingWater() {try {// 烧开一壶水需要1秒Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}}
执行该方法输出如下,符合我们的预期。
serial cost:10091concurrent cost:1048
此时并发执行的流程就如下图,从一个task拆出多个task,然后由每个CPU负责处理1个,因此处理时间接近于1个任务的处理时间。

4、线程池的参数设置
1)线程数
之前的线程池面试文章里有介绍过线程数的设置,这边直接复制过来:
要想合理的配置线程池大小,首先我们需要区分任务是计算密集型还是I/O密集型。
对于计算密集型,设置 线程数 = CPU数 + 1,通常能实现最优的利用率。
对于I/O密集型,网上常见的说法是设置 线程数 = CPU数 * 2 ,这个做法是可以的,但个人觉得不是最优的。
在我们日常的开发中,我们的任务几乎是离不开I/O的,常见的网络I/O(RPC调用)、磁盘I/O(数据库操作),并且I/O的等待时间通常会占整个任务处理时间的很大一部分,在这种情况下,开启更多的线程可以让 CPU 得到更充分的使用,一个较合理的计算公式如下:
线程数 = CPU数 * CPU利用率 * (任务等待时间 / 任务计算时间 + 1)
例如我们有个定时任务,部署在4核的服务器上,该任务有100ms在计算,900ms在I/O等待,则线程数约为:4 * 1 * (1 + 900 / 100) = 40个。
当然,具体我们还要结合实际的使用场景来考虑。如果要求比较精确,可以通过压测来获取一个合理的值。
上述是比较理想的线程数计算方式,在实际项目使用中,如果无法很准确的计算,那么可以先用我上面的线程池配置,也就是:
corePoolSize = CPU核数
maximumPoolSize = CPU核数 * 2
这个参数设置可能不是最理想的,但在大多数情况下都是一个还不错的选择,比较合适。
2)keepAliveTime、TimeUnit
这两个参数一起决定了非核心线程空闲后的存活时间。
这两个参数说实话并不是非常重要,实际使用过程中不要设置太离谱的值一般问题不大,我个人一般使用5分钟或30分钟。
3)workQueue
工作队列,当核心线程处理不过来时,任务会堆积在队列里。
常见的队列有 ArrayBlockingQueue 和 LinkedBlockingQueue,两者的主要区别在于 ArrayBlockingQueue 占用空间会更小,而 LinkedBlockingQueue 在生产者和消费者使用了不同的锁性能会好一点。
通常情况下,两者的区别微乎其微,除非你要处理的任务量非常非常大,此时你需要仔细考虑使用哪个更合适,否则通常情况下两个随便选都可以。
常见的坑:使用 LinkedBlockingQueue 时没设置队列大小,也就是使用了无界队列(Integer.MAX_VALUE),任务处理不过来,不断积压在队列里,最终造成内存溢出。
线程池使用不当导致内存溢出的case我已经见过很多次了,这个经验大家一定要铭记在心:使用 LinkedBlockingQueue 一定要设置队列大小。
另外,这边给大家介绍下另一个我常用的工作队列:SynchronousQueue。
SynchronousQueue 不是一个真正的队列,而是一种在线程之间移交的机制。要将一个元素放入 SynchronousQueue 中,必须有另一个线程正在等待接受这个元素。如果没有线程等待,并且线程池的当前大小小于 maximumPoolSize,那么线程池将创建一个线程,否则根据拒绝策略,这个任务将被拒绝。使用直接移交将更高效,因为任务会直接移交给执行它的线程,而不是被放在队列中,然后由工作线程从队列中提取任务。只有当线程池是无界的或者可以拒绝任务时,该队列才有实际价值,Executors.newCachedThreadPool使用了该队列。
上述内容里提到了:当线程池是无界的或者可以拒绝任务时,该队列才有实际价值。
使用无界的线程池说实话挺危险的,我强烈建议不要使用,特别是经验不太丰富的新人。因此我们在使用 SynchronousQueue 的时候可以理解为一定会出现任务被拒绝的情况,因此要选择好合适的拒绝策略。
SynchronousQueue 我一般会搭配 CallerRunsPolicy 使用,个人觉得这2个是个绝佳组合,这个组合起到的效果是:当线程池处理不过来时,直接交由调用者线程(往线程池里添加任务的主线程)来执行,此时任务不会被积压在队列里,同时调用者线程无法继续提交任务。
简单来说:任务处理非常高效,没有任务积压的概念不会有内存溢出的风险,同时在线程池处理不过来时具有控制任务提交速度的效果。
4)ThreadFactory
线程工厂,这个没啥好说的,通常使用默认的就行。
常见的改动场景是:给线程设置个自定义的名字,方便区分。
这种场景下,可以使用一些工具类提供的现有方法,也可以将 DefaultThreadFactory 拷贝出来自己修改一下。
5)RejectedExecutionHandler
拒绝策略,线程池处理不过来时的策略。默认有4种策略,其中3种我个人比较常用到。
AbortPolicy:默认的策略,直接抛出异常,没有特殊需求直接使用该策略即可。
CallerRunsPolicy:调用者线程执行策略,该策略上面提到了,我一般是配合 SynchronousQueue 使用,起到一个控制任务提交速度的效果。
DiscardPolicy:抛弃策略,直接丢掉要提交的任务,这个策略一般在线程池执行的是不太重要的任务时使用。
5、并发并行适用于哪种场景
典型的适合使用并发并行的场景通常有以下特点:
1)存在I/O操作,并且I/O操作有多次,最典型的就是RPC调用和查询数据库
2)I/O操作比较耗时,越耗时越有优化价值
3)多次I/O操作之间没有依赖关系,可以同时调用
总结
并发和并行是性能优化中非常常用的手段,使用起来非常简单,并且带来的性能提升通常非常明显,很容易就有几倍几倍的提升,快在自己的项目中用起来吧。
最后
我是囧辉,一个坚持分享原创技术干货的程序员,如果觉得本文对你有帮助,欢迎一键三连。
推荐阅读
最近我将面试:阿里、字节、美团、快手、拼多多等大厂的高频面试整理出来,并按大厂的标准给出自己的解析。
群里有不少同学看完拿下了阿里、美团等大厂 Offer,希望能助你一臂之力,早日拿下大厂 Offer。
获取方式:关注公众号回复【面试】即可领取,更多大厂面试真题解析 PDF 整理中。
