
深入分析NIO的零拷贝
有道无术,术尚可求也!有术无道,止于术!
本章还是关于NIO的概念铺底,有关NIO相关的代码,我还是希望大家闲余时间取网上找一下有关使用JDK NIO开发服务端、客户端的代码,我会取写这些,但是具体的代码我不会很详细的取介绍,下一章的话可能就要上代码了,具体的规划如下:
讲一下NIO基础API的使用、分析Netty的核心思想,使用Reactor模式仿写一个多线程版的Nio程序、再然后就是关于Netty的源码分析了!
回归正题,NIO的高性能除了体现在Epoll模型之外,还有很重要的一点,就是零拷贝!首先大家要先明白一点,所谓的0拷贝,并不是一次拷贝都没有,而是数据由内核空间向用户空间的相互拷贝被取消了,所以称之为零拷贝!
系统如何操作底层数据文件
在了解整个IO的读写的过程中,我们需要知道我们的应用程序是如何操作一些内存、磁盘数据的!
我们在开发中,假设要向硬盘中写入一段文本数据,我们并不需要操作太多的细节,而是只需要简单的将数据转为字节然后在告诉程序,我们要写入的位置以及名称就可以了,为什么这么简单呢?因为操作系统全部帮我们开发好了,我们只需要调用就可以了,但是我们想一下,如果我们的操作系统的全部权限,包括内存都可以让用户随意操作那是一个很危险的事情,例如某些病毒可以随意篡改内存中的数据,以达到某些不轨的目的,那就很难受了!所以,我们的操作系统就必须对这些底层的API进行一些限制和保护!
但是如何保护呢?一方面,我们希望外部系统能够调用我的系统API,另一方面我又不想外部随意访问我的API怎么办呢? 此时,我们就要引申出来一个组件叫做kernel,你可以把它理解为一段程序,他在机器启动的时候被加载进来,被用于管理系统底层的一些设备,例如硬盘、内存、网卡等硬件设备!当我们又了kernel之后,会发生什么呢?
我们还是以写出文件为例,当我们调用了一个write api的时候,他会将write的方法名以及参数加载到CPU的寄存器中,同时执行一个指令叫做 int 0x80的指令,int 0x80是 interrupt 128(0x80的10进制)的缩写,我们一般叫80中断,当调用了这个指令之后,CUP会停止当前的调度,保存当前的执行中的线程的状态,然后在中断向量表中寻找 128代表的回调函数,将之前写到寄存器中的数据(write /参数)当作参数,传递到这个回调函数中,由这个回调函数去寻找对应的系统函数write进行写出操作!
大家回想一下,当系统发起一个调用后不再是用户程序直接调用系统API的而是切换成内核调用这些API,所以内核是以这种方式来保护系统的而且这也就是 用户态切换到内核态!
传统的I/O读写
场景:读取一个图片通过socket传输到客户端展示。
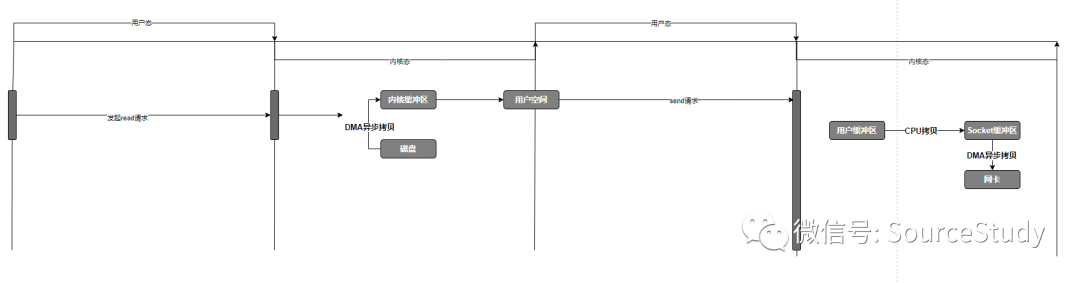
程序发起read请求,调用系统read api由用户态切换至内核态! CPU通过DMA引擎将磁盘数据加载到内核缓冲区,触发中止指令,CPU将内核缓冲区的数据拷贝到用户空间!由内核态切换至用户态! 程序 发起write调用,调用系统API,由用户态切换只内核态,CPU将用户空间的数据拷贝到Socket缓冲区!再由内核态切换至用户态! DMA引擎异步将Socket缓冲区拷贝到网卡通过底层协议栈发送至对端!
我们可以了解一下,这当中发生了4次上下文的切换和4次数据拷贝!我们大致分析一下,那些数据拷贝是多余的:
磁盘文件拷贝到内核缓冲区是必须的不能省略,因为这个数据总归要读取出来的! 内核空间拷贝到用户空间,如果我们不准备对数据做修改的话,好像没有必要呀,直接拷贝到Socket缓冲区不就可以了! Socket到网卡,好像也有点多余,为什么这么说呢?因为我们直接从内核空间里面直接怼到网卡里面,中间不就少了很多的拷贝和上下文的切换看吗?
sendfile
我们通过Centos man page指令查看该函数的定义!
也可以通过该链接下载:sendfile()函数介绍
基本介绍:
sendfile——在文件描述符之间传输数据
描述
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);sendfile()在一个文件描述符和另一个文件描述符之间复制数据。因为这种复制是在内核中完成的,所以sendfile()比read(2)和write(2)的组合更高效,后者需要在用户空间之间来回传输数据。
in_fd应该是打开用于读取的文件描述符,而out_fd应该是打开用于写入的文件描述符。
如果offset不为NULL,则它指向一个保存文件偏移量的变量,sendfile()将从这个变量开始从in_fd读取数据。当sendfile()返回时,这个变量将被设置为最后一个被读取字节后面的字节的偏移量。如果offset不为NULL,则sendfile()不会修改当前值
租用文件偏移in_fd;否则,将调整当前文件偏移量以反映从in_fd读取的字节数。
如果offset为NULL,则从当前文件偏移量开始从in_fd读取数据,并通过调用更新文件偏移量。
count是要在文件描述符之间复制的字节数。
in_fd参数必须对应于支持类似mmap(2)的操作的文件(也就是说,它不能是套接字)。
在2.6.33之前的Linux内核中,out_fd必须引用一个套接字。从Linux 2.6.33开始,它可以是任何文件。如果是一个常规文件,则sendfile()适当地更改文件偏移量。
简单来说,sendfile函数可以将两个文件描述符里面的数据来回复制,再Linux中万物皆文件!内核空间和Socket也是一个个的对应的文件,sendfile函数可以将两个文件里面的数据来回传输,这也造就了,我们后面的零拷贝优化!
sendfile - linux2.4之前
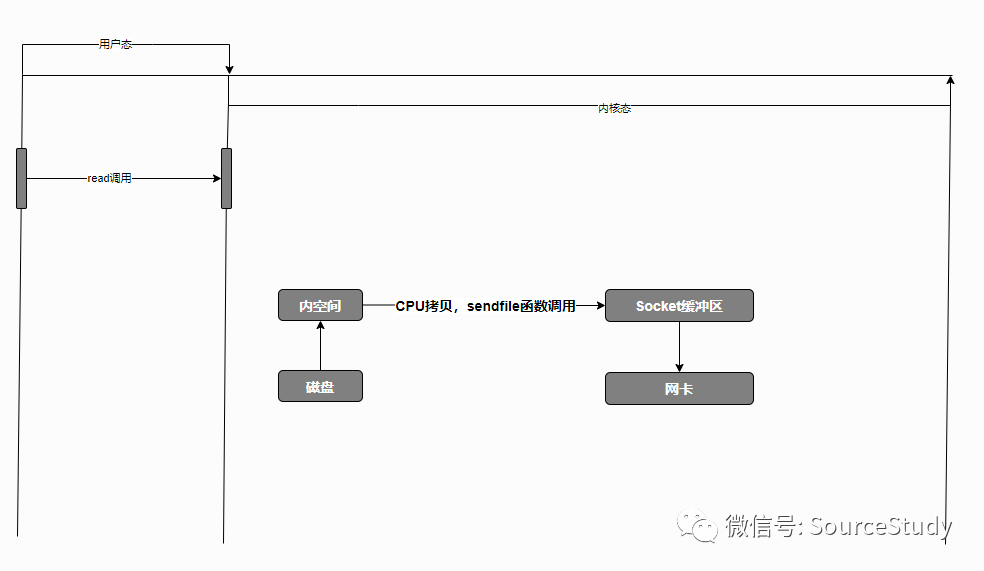
用户程序发起read请求,程序由用户态切换至内核态! DMA引擎将数据从磁盘拷贝出来到内核空间! 调用sendfile函数将内核空间的数据直接拷贝到Socket缓冲区! 上下文从内核态切换至用户态 Socket缓冲区通过DMA引擎,将数据拷贝到网卡,通过底层协议栈发送到对端!
这个优化不可谓不狠,上下文切换次数变为两次,数据拷贝变为两次,这基本符合了我们上面的优化要求,但是我们还是会发现,从内核空间到Socket缓冲区,然后从内核缓冲区到网卡似乎也有点鸡肋,所以,Linux2.4之后再次进行了优化!
sendfile - linux2.4之后
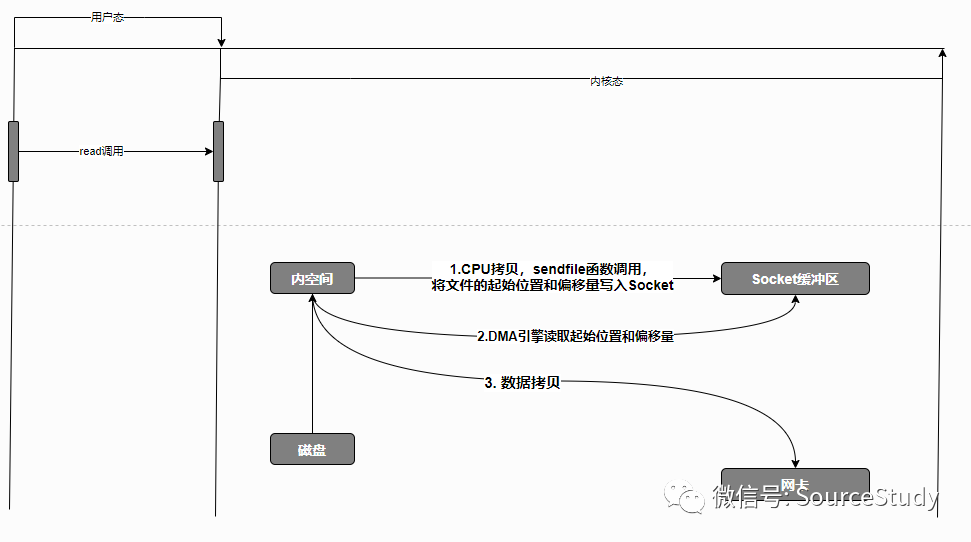
用户程序发起read请求,程序由用户态切换至内核态! DMA引擎将数据从磁盘拷贝出来到内核空间! 调用sendfile函数将内核空间的数据再内存中的起始位置和偏移量写入Socket缓冲区!然后内核态切换至用户态! DMA引擎读取Socket缓冲区的内存信息,直接由内核空间拷贝至网卡!
这里的优化是原本将内核空间的数据拷贝至Socket缓冲区的步骤,变成了只记录文件的起始位置和偏移量!然后程序直接返回,由DMA引擎异步的将数据从内核空间拷贝到网卡!
为什么不是直接拷贝,而是多了一步记录文件信息的步骤呢?因为相比于内核空间,网卡的读取速率实在是太慢了,这一步如果由CPU来操作的话,会严重拉低CPU的运行速度,所以要交给DMA来做,但是因为是异步的,DMA引擎又不知道为这个Socket到底发送多少数据,所以要在Socket上记录文件起始量和数据长度,再由DMA引擎读取这些文件信息,将文件发送只网卡数据!
mmap
我们通过Centos man page指令查看该函数的定义!
mmap()函数介绍
名字
mmap, munmap -将文件或设备映射到内存中
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
int munmap(void *addr, size_t length);描述:
mmap()在调用进程的虚拟地址空间中创建一个新的映射。新映射的起始地址在addr中指定。length参数指定映射的长度,如果addr为空,则内核选择创建映射的地址;这是创建新映射的最可移植的方法。如果addr不为空,则内核将其作为提示!关于在哪里放置映射;在Linux上,映射将在附近的页面边界创建。新映射的地址作为调用的结果返回。
mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。
什么叫区域共享,这个不能被理解为我们的应用程序就可以直接到内核空间读取数据了,而是我们在用户空间里面再开辟一个空间,将内核空间的数据的起始以及偏移量映射到用户空间!简单点说 **也就是用户空间的内存,持有对内核空间这一段内存区域的引用!**这样用户空间在操作读取到的数据的时候,就可以像直接操作自己空间下的数据一样操作内核空间的数据!
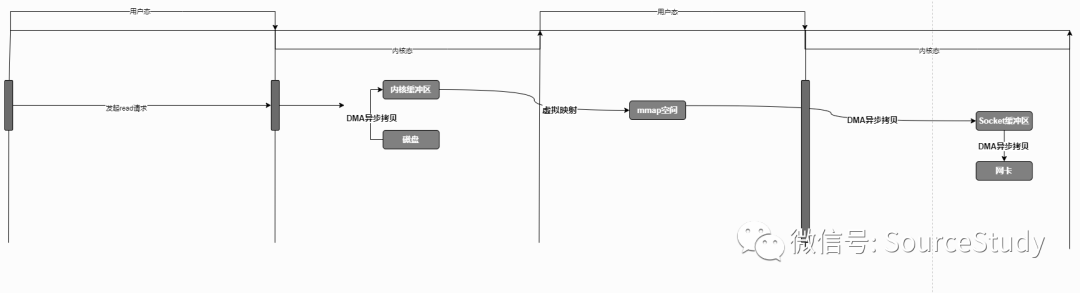
用户程序发起read请求,然后上下文由用户态切换至内核态! cpu通知DMA,由DMA引擎异步将数据读取至内核区域,同时在用户空间建立地址映射! 上下文由内核态切换至用户态 发起write请求,上下文由用户态切换至内核态! CPU通知DMA引擎将数据拷贝至Socket缓存!程序切换至用户态! DMA引擎异步将数据拷贝至网卡!
很明白的发现mmap函数在read数据的时候,少了异步由内核空间到用户空间的数据复制,而是直接建立一个映射关系,操作的时候,直接操作映射数据,但是上下文的切换没有变!
mmap所建立的虚拟空间,空间量事实上可以远大于物理内存空间,假设我们想虚拟内存空间中写入数据的时候,超过物理内存时,操作系统会进行页置换,根据淘汰算法,将需要淘汰的页置换成所需的新页,所以mmap对应的内存是可以被淘汰的(若内存页是"脏"的,则操作系统会先将数据回写磁盘再淘汰)。这样,就算mmap的数据远大于物理内存,操作系统也能很好地处理,不会产生功能上的问题。
sendfile: 只经历两次上线文的切换和两次数据拷贝,但是缺点也显而易见,你无法对数据进行修改操作!适合大文件的数据传输!而且是没有没有修改数据的需求!
mmap: 经历4次上下文的切换、三次数据拷贝,但是用户操作读取来的数据,异常简单!适合小文件的读写和传输!
nio的堆外内存
堆外内存的实现类是DirectByteBuffer, 我们查看SocketChannel再向通道写入数据的时候的代码:
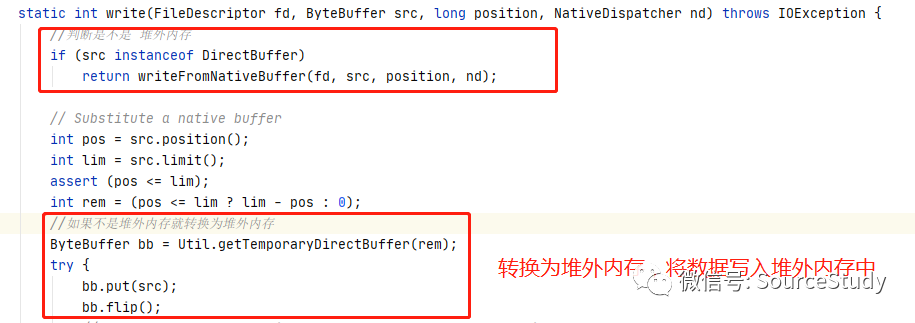
这段代码是当你调用SocketChannel.write的时候的源代码,我们从代码中可以得知,无论你是否使用的是不是堆外内存,在内部NIO都会将其转换为堆外内存,然后在进行后续操作,那么堆外内存究竟有何种魔力呢?
何为堆外内存,要知道我们的JAVA代码运行在了JVM容器里面,我们又叫做Java虚拟机,java开发者为了方便内存管理和内存分配,将JVM的空间与操作系统的空间隔离了起来,市面上所有的VM程序都是这样做的,VM程序的空间结构和操作系统的空间结构是不一样的,所以java程序无法直接的将数据写出去,必须先将数据拷贝到C的堆内存上也就是常说的堆外内存,然后在进行后续的读写,在NIO中直接使用堆外内存可以省去JVM内部数据向本次内存空间拷贝的步骤,加快处理速度!
而且NIO中每次写入写出不在是以一个一个的字节写出,而是用了一个Buffer内存块的方式写出,也就是说只需要告诉CPU 我这个数据块的数据开始的索引以及数据偏移量就可以直接读取,但是JVM通过垃圾回收的时候,通过会做垃圾拷贝整理,这个时候会移动内存,这个时候如果内存地址改变,就势必会出现问题,所以我们要想一个办法,让JVM垃圾回收不影响这个数据块!
总结来说:它可以使用Native 函数库直接分配堆外内存,然后通过一个存储在Java 堆里面的DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java 堆和Native 堆中来回复制数据。
能够避免JVM垃圾回收过程中做内存整理,所产生的的问题,当数据产生在JVM内部的时候,JVM的垃圾回收就无法影响这部分数据了,而且能够变相的减轻JVM垃圾回收的压力!因为不用再管理这一部分数据了!
他的内存结构看起来像这样:
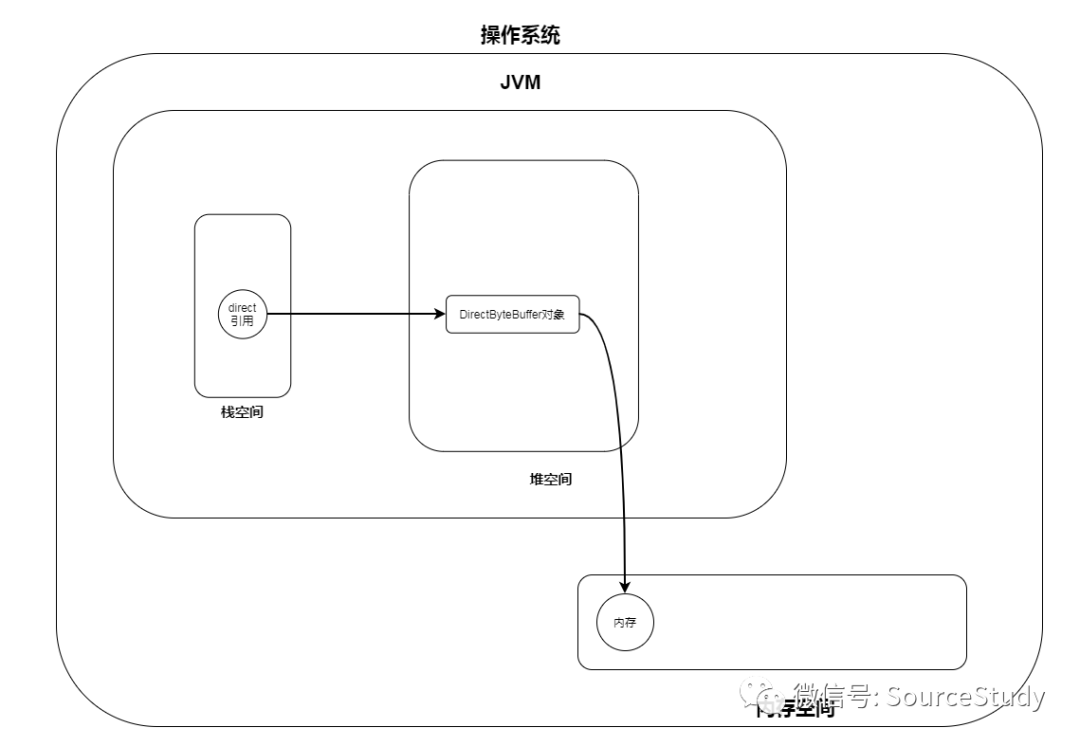
为什么DirectByteBuffer就能够直接操作JVM外的内存呢?我们看下他的源码实现:
DirectByteBuffer(int cap) {
.....忽略....
try {
//分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
....忽略....
}
....忽略....
if (pa && (base % ps != 0)) {
//对齐page 计算地址并保存
address = base + ps - (base & (ps - 1));
} else {
//计算地址并保存
address = base;
}
//释放内存的回调
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
....忽略..
}
我们主要关注:unsafe.allocateMemory(size);
public native long allocateMemory(long var1);
我们可以看到他调用的是 native方法,这种方法通常由C++实现,是直接操作内存空间的,这个是被jdk进行安全保护的操作,也就是说你通过Unsafe.getUnsafe()是获取不到的,必须通过反射,具体的实现,自行翻阅浏览器!
如此NIO就可以通过本地方法去操作JVM外的内存,但是大家有没有发现一点问题,我们现在是能够让操作系统直接读取数据了,而且也能够避免垃圾回收所带来的影响了还能减轻垃圾回收的压力,可谓是一举三得,但是大家有没有考虑过一个问题,这部分空间不经过垃JVM管理了,他该什么时候释放呢?JVM都管理不了了,那么堆外内存势必会导致OOM的出现,所以,我们必须要去手动的释放这个内存,但是手动释放对于编程复杂度难度太大,所以,JVM对堆外内存的管理也做了一部分优化,首先我们先看一下上述DirectByteBuffer中的cleaner = Cleaner.create(this, new Deallocator(base, size, cap));,这个对象,他主要用于堆外内存空间的释放;
public class Cleaner extends PhantomReference<Object> {....}
虚引用
Cleaner继承了一个PhantomReference,这代表着Cleaner是一个虚引用,有关强软弱虚引用的使用,请大家自行百度,Netty更新完成之后,我会写一篇文章做单独的介绍,这里就不一一介绍了,这里直接说PhantomReference虚引用:
public class PhantomReference<T> extends Reference<T> {
public T get() {
return null;
}
public PhantomReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}
虚引用的构造函数中要求必须传递的两个参数,被引用对象、引用队列!
这两个参数的用意是什么呢,看个图
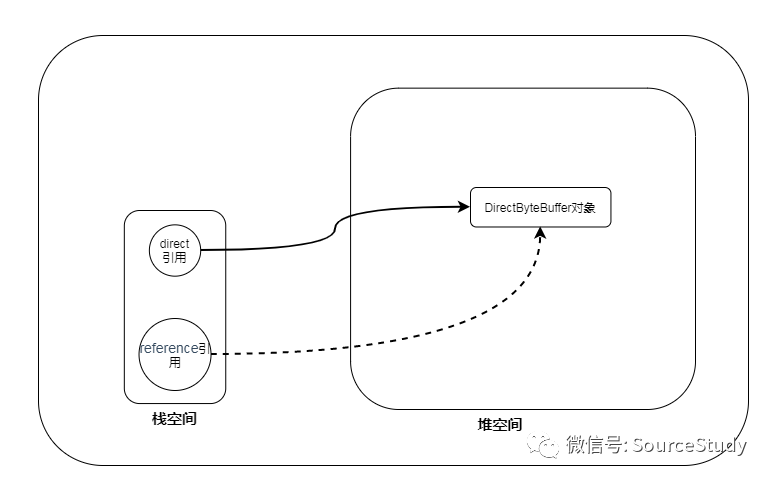
JVM中判断一个对象是否需要回收,一般都是使用可达性分析算法,什么是可达性分析呢?就是从所谓的方法区、栈空间中找到被标记为root的节点,然后沿着root节点向下找,被找到的都任务是存活对象,当所有的root节点寻找完毕后,剩余的节点也就被认为是垃圾对象;
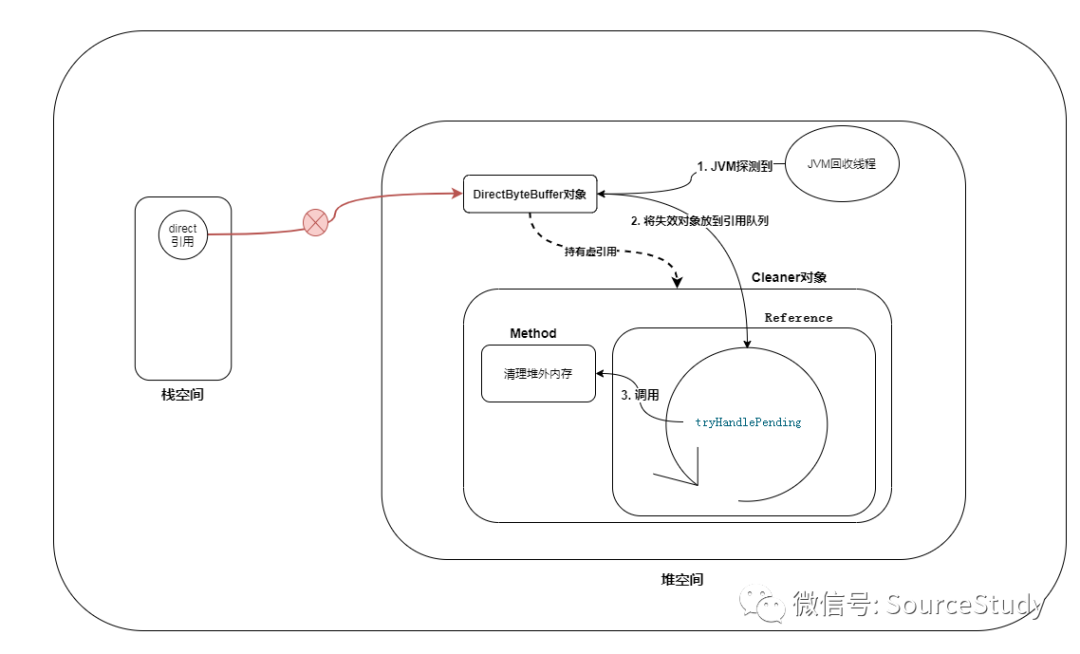
依据上图,我们明显发现栈空间中持有对direct的引用,我们将该对象传递给弱引用和,弱引用也持有该对象,现在相当于direct引用和ref引用同时引用堆空间中的一块数据,当direct使用完毕后,该引用断开:
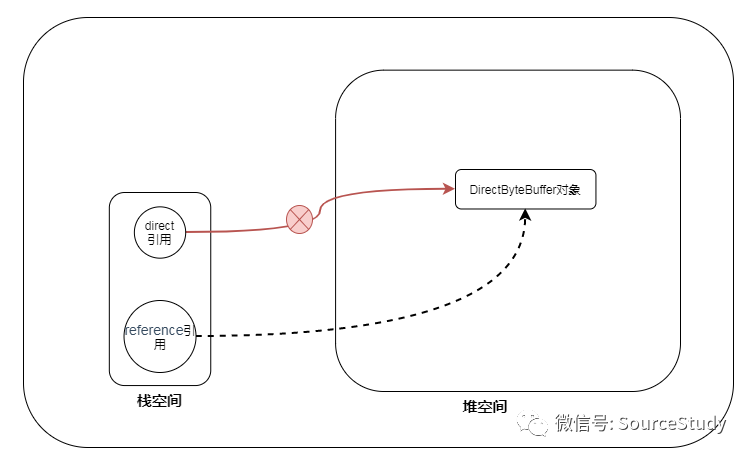
JVM通过可待性分析算法,发现除了 ref引用之外,其余的没有人引用他,因为ref是虚引用,所以本次垃圾回收一定会回收它,回收的时候,做了一件什么事呢?
我们在创建这个虚引用的时候传入了一个队列,在这个对象被回收的时候,被引用的对象会进入到这个回调!
public class MyPhantomReference {
static ReferenceQueue<Object> queue = new ReferenceQueue<>();
public static void main(String[] args) throws InterruptedException {
byte[] bytes = new byte[10 * 1024];
//将该对象被虚引用引用
PhantomReference<Object> objectPhantomReference = new PhantomReference<Object>(bytes,queue);
//这个一定返回null 因为实在接口定义中写死的
System.out.println(objectPhantomReference.get());
//此时jvm并没有进行对象的回收,该队列返回为空
System.out.println(queue.poll());
//手动释放该引用,将该引用置为无效引用
bytes = null;
//触发gc
System.gc();
//这里返回的还是null 接口定义中写死的
System.out.println(objectPhantomReference.get());
//垃圾回收后,被回收对象进入到引用队列
System.out.println(queue.poll());
}
}
基本了解了虚引用之后,我们再来看DirectByteBuffer对象,他在构造函数创建的时候引用看一个虚引用Cleaner!当这个DirectByteBuffer使用完毕后,DirectByteBuffer被JVM回收,触发Cleaner虚引用!JVM垃圾线程会将这个对象绑定到Reference对象中的pending属性中,程序启动后引用类Reference类会创建一条守护线程:
static {
ThreadGroup tg = Thread.currentThread().getThreadGroup();
for (ThreadGroup tgn = tg;
tgn != null;
tg = tgn, tgn = tg.getParent());
Thread handler = new ReferenceHandler(tg, "Reference Handler");
//设置优先级为系统最高优先级
handler.setPriority(Thread.MAX_PRIORITY);
handler.setDaemon(true);
handler.start();
//.......................
}
我们看一下该线程的定义:
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
//......忽略
c = r instanceof Cleaner ? (Cleaner) r : null;
pending = r.discovered;
r.discovered = null;
} else {
//队列中没有数据结阻塞 RefQueue入队逻辑中有NF操作,感兴趣可以自己去看下
if (waitForNotify) {
lock.wait();
}
// retry if waited
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
//发生OOM之后就让出线程的使用权,看能不能内部消化这个OOM
Thread.yield();
return true;
} catch (InterruptedException x) {
// 线程中断的话就直接返回
return true;
}
// 这里是关键,如果虚引用是一个 cleaner对象,就直接进行清空操作,不在入队
if (c != null) {
//TODO 重点关注
c.clean();
return true;
}
//如果不是 cleaner对象,就将该引用入队
ReferenceQueue<? super Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}
那我们此时就应该重点关注**c.clean();**方法了!
this.thunk.run();
重点关注这个,thunk是一个什么对象?我们需要重新回到 DirectByteBuffer创建的时候,看看他传递的是什么。
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
我们可以看到,传入的是一个 Deallocator对象,那么他所调用的run方法,我们看下逻辑:
public void run() {
if (address == 0) {
// Paranoia
return;
}
//释放内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
重点关注**unsafe.freeMemory(address);**这个就是释放内存的!
至此,我们知道了JVM是如何管理堆外内存的了!
才疏学浅,如果文章中理解有误,欢迎大佬们私聊指正!欢迎关注作者的公众号,一起进步,一起学习!
❤️「转发」和「在看」,是对我最大的支持❤️