
包教包会的零拷贝
这一篇的主题是零拷贝这个技术点!
我们接下来从下面这几个问题的角度来给全方面分析零拷贝这个技术点,一边读不懂的同学,赶紧收藏,读多几遍就懂了
还有还有,收藏起来,等以后忘记了或者快要面试的时候,可以逃出来熟悉熟悉
毕竟,好记性不如烂笔头的嘞
为什么要有 DMA 技术?
我们先来看一下在没有DMA技术之前的IO过程:
1、CPU发出对应的指令到磁盘系统,然后返回
2、磁盘系统收到指令,把数据放入到磁盘系统的内部缓冲区中,然后产生一个中断指令
3、CPU收到中断信号,停止当前工作,紧接着把磁盘系统缓冲区中的数据读到自己的寄存器内,然后把寄存器的数据写入到内存,在此数据传输期间CPU无法执行其它工作
画了一个图帮助大家理解
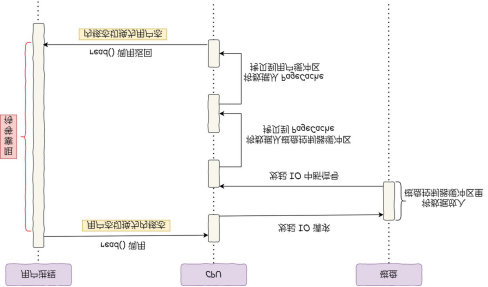
聪明的小伙伴已经发现其中的弊端了,就是数据传输期间,CPU无法执行其它命令
我们知道CPU是中央处理器,这个东西的性能能省就省,能扣着点用就扣着点用,毕竟整个机器都要用这家伙
简单的搬运几个字符数据肯定没啥问题,但是如果传输大量数据的时候都需要CPU来搬运,那就很糟糕了
于是,DMA技术就诞生了,就是直接内存访问技术Direct Memory Access
DMA技术,就是在进行IO设备和内存之间数据传输的时候,数据搬运的工作全部交给DMA控制器,而CPU不再参与任何和数据搬运相关的事情了,这样就把CPU空出来了
具体来看一下使用DMA控制器的流程
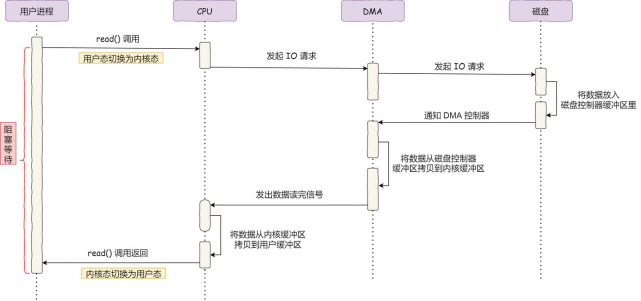
1、用户调用read,先操作系统发起IO请求,请求读取数据到自己的内存缓冲区,然后进入阻塞
2、操作系统收到请求,把IO请求发给了DMA,然后CPU执行其它任务,DMA发送给磁盘
3、磁盘收到IO请求,把数据放入到自己的缓冲区,磁盘系统缓冲区满的时候,向DMA发起中断指令
4、DMA收到中断指令,将磁盘缓冲区数据拷贝到内核缓冲区,不占用CPU
5、DMA读取了足够多数据,发送中断信号给CPU
6、CPU收到DMA信号,知道数据准备好了,将数据从内核拷贝到用户空间
看整个过程,发现CPU不再参与数据搬运的工作,而是由DMA完成的,但是呢,CPU在这个过程也是必不可少,因为传输什么,从哪里传输到哪里需要CPU来告诉DMA控制器
这就像创业公司,老板自己干活忙不过来了,就招了一个秘书,但是,这个秘书操作什么,如何操作,还是得听老板的指挥
早期 DMA 只存在在主板上,如今由于 I/O 设备越来越多,数据传输的需求也不尽相同,所以每个 I/O 设备里面都有自己的 DMA 控制器。

传统的传输文件
先来给大家简单说一下用户空间和内核空间,比如我们部署一个Java程序到一台Linux服务器上,我们可以认为JVM的区域就是用户空间,其余的空间就是内核空间,用户空间和内核空间对于系统文件的操作权限是不一样的
传统的文件传输的工作方式:数据读取和写入是从用户空间和内核空间来回复制,而内核空间的数据是通过操作系统层面的IO接口从磁盘读取或者写入
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len);write(socket, tmp_buf, len);
看这两行代码做了啥
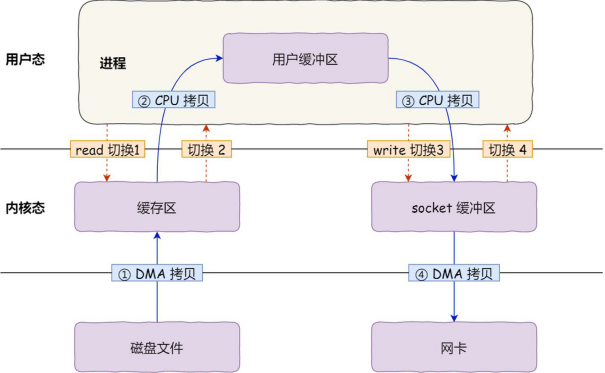
两次系统调用,发生了4次用户态和内核态的上下文切换,每次系统调用都得先从用户态切换到内核态,然后等内核态完成任务,再切换回到用户态
一次上下文的切换耗时几十纳秒到几微秒,时间看上去很短,但是在高并发的场景下,这类时间就会变得不可忽视,从而影响系统的性能
中间还发生了4次数据拷贝,其中两次是DMA的拷贝,DMA技术是优化IO设备到内核区的,另外两次是通过CPU拷贝用户缓冲区的
1、第一次拷贝,磁盘上的数据通过DMA技术拷贝到操作系统的内核区中
2、第二次拷贝,CPU把内核缓冲区数据拷贝到用户缓冲区中
3、第三次拷贝,CPU将用户缓冲区的数据搬运到内核缓冲区中
4、第四次拷贝,通过DMA技术把内核数据搬运到网卡的缓冲区中
问题:我们搬运一次数据,中间却复制了4次,过多的上下文切换和过多的数据拷贝都会降低系统性能,所以,如果想提高文件传输的性能,就需要减少用户态和内核态的上下文切换和内容拷贝的次数
优化思路
减少用户态和内核态之间的上下文切换
之所以发生上下文的切换,是因为用户空间没有权限操作磁盘或者网卡,内核的权限最高,这些操作设备的过程都需要交给操作系统的内核来完成,一次系统调用也就意味着必然发生2次上下文的切换,首先从用户态切换到内核态,内核态执行完任务之后再切换到用户态执行相应进程的代码指令
所以,要减少上下文切换的次数,就需要减少系统调用的次数
减少数据拷贝的次数
数据传输的4次拷贝,其中内核拷贝到用户缓冲区,再从用户缓冲区拷贝到内核缓冲区,这两个过程是没必要的,因为在文件传输的应用场景中,在用户空间我们并不会对数据再加工,所以这个数据没必要搬运到用户空间

如何实现零拷贝?
零拷贝技术实现的方式通常有 2 种:
mmap + write(三次拷贝+两次系统调用)Sendfile(三次拷贝+一次系统调用)
下面就谈一谈,它们是如何减少「上下文切换」和「数据拷贝」的次数。
mmap + write
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);write(sockfd, buf, len);
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
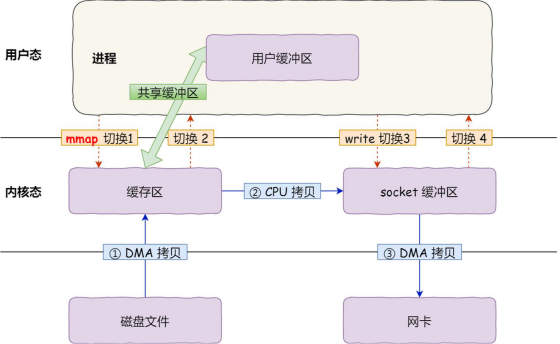
具体过程如下:
1、应用调用了mmap(),DMA把磁盘数据拷贝到内核缓冲区,此时,应用进程和内核会共享这个内核缓冲区
2、应用系统调用write(),操作系统直接把内核缓冲区数据拷贝到网络缓冲区中,这个也是属于内核态,内核中的拷贝,由CPU来操作
3、第三次拷贝,通过DMA技术把网络缓冲区数据拷贝到网卡的缓冲区中
我们可以得知,通过使用mmap()来代替 read(),可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
Sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#includessize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
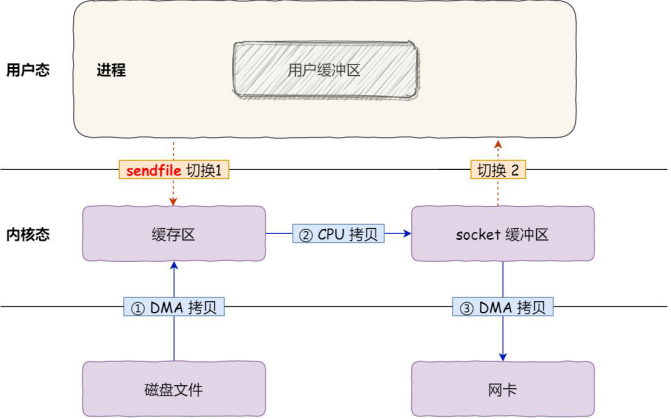
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。
如下图
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gatherscatter-gather: on
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
1、DMA直接将磁盘上的数据拷贝到内核缓冲区中
2、缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
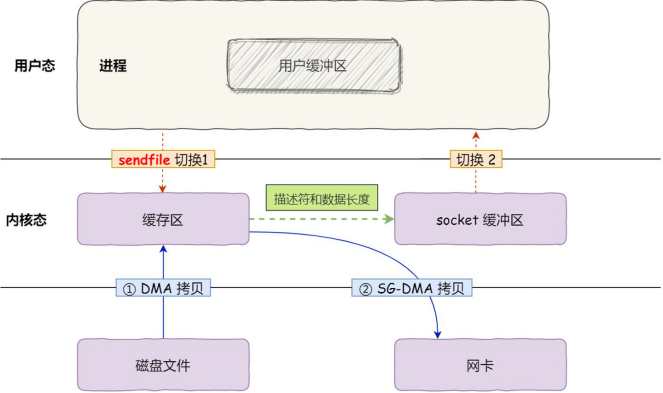
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
CPU属于参与了,但没完全参与,DMA操作需要CPU指挥,描述符和数据长度需要CPU发送
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
我们通常说的这个零拷贝技术中的这个零,指的是内核态和用户态之间的拷贝次数,变成了0
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
PageCache
上面说的第一步是先把磁盘文件数据拷贝到内核缓冲区中,这个内核缓冲区就是磁盘高速缓冲区PageCache,内存速度比磁盘速度快,但是内存空间比磁盘要小
我们需要把此时的热点数据放入到缓存中,因为这是最近需要频繁访问的,空间不足的时候淘汰掉那些访问频率低的数据
缓存这些道理大家应该都懂,零拷贝也使用了缓存技术,读取数据的时候,优先在PageCache中找,找到直接返回,找不到去磁盘中读取,然后缓存到PageCache中
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
缓存最近被访问的数据;预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能,一个大文件直接占满,导致某些热点小文件无法使用,性能就降低了
所以,针对大文件的传输,不应该使用 PageCache,也就是说不应该使用零拷贝技术,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,这样在高并发的环境下,会带来严重的性能问题。
对于大文件传输,可以通过异步IO和绕开PageCache的IO来代替零拷贝技术
在 nginx 中,我们可以用如下配置,来根据文件的大小来使用不同的方式:
location /video/ {sendfile on;aio on;directio 1024m;}
当文件大小大于 directio 值后,使用「异步 I/O + 直接 I/O」,否则使用「零拷贝技术」。

总结
1、早期IO,内核数据需要IO进行复制,2次系统调用,4次上下文切换,4次数据的拷贝,CPU拷贝数据期间不能执行其它命令
2、引入DMA技术,DMA可以代替CPU进行磁盘到内核区域数据的复制,这个期间CPU可执行其它命令,改善了性能
3、零拷贝技术:mmap+write,2次系统调用,4次上下文切换,3次数据的拷贝,减少了读取期间内核区域到用户区域的数据复制,原因是两者共享了内核区域的缓冲区
4、零拷贝技术:Sendfile,1次系统调用,2次上下文切换,3次数据的拷贝,直接指定了原文件和目标文件,替代了原来的两次系统调用,直接一次完成
5、真正的零拷贝技术:网卡支持 SG-DMA技术,数据从磁盘系统读取到内核缓冲区之后,不需要复制到相应的socket缓冲区即可,只需要发送描述符和数据长度即可,这个期间经历了1次系统调用,2次上下文切换,2次数据拷贝,没有在内核层面去进行数据的拷贝
6、零拷贝技术引用PageCache缓存技术,缓存技术用于加速热点文件的查询速度,但是不适用于大文件,大文件可以通过异步IO和绕开PageCache的IO来代替零拷贝技术
参考文献:https://zhuanlan.zhihu.com/p/258513662
结束语
感谢大家能够做我最初的读者和传播者,请大家相信,只要你给我一份爱,我终究会还你们一页情的。
左耳君会持续更新技术文章,和生活中的暴躁文章,欢迎大家关注,我们一起乘千里风、破万里浪
哦对了,后续所有的文章都会更新到这里
https://github.com/DayuMM2021/Java
