
别再乱用 Prometheus 联邦了,分享一个 Prometheus 高可用新方案

前言
我看到很多人会这样使用联邦:联邦 prometheus 收集多个采集器的数据 实在看不下下去了,很多小白还在乱用 prometheus的联邦其实很多人是想实现 prometheus 数据的可用性,数据分片保存,有个统一的查询地方(小白中的联邦 prometheus) 而且引入 m3db 等支持集群的 tsdb 可能比较重 具体问题可以看我之前写的文章 m3db 资源开销,聚合降采样,查询限制等注意事项[1] m3db-node oom 追踪和内存分配器代码查看[2] 今天写篇文章分析下联邦的问题,并给出一个基于全部是 prometheus 的 multi_remote_read方案
架构图
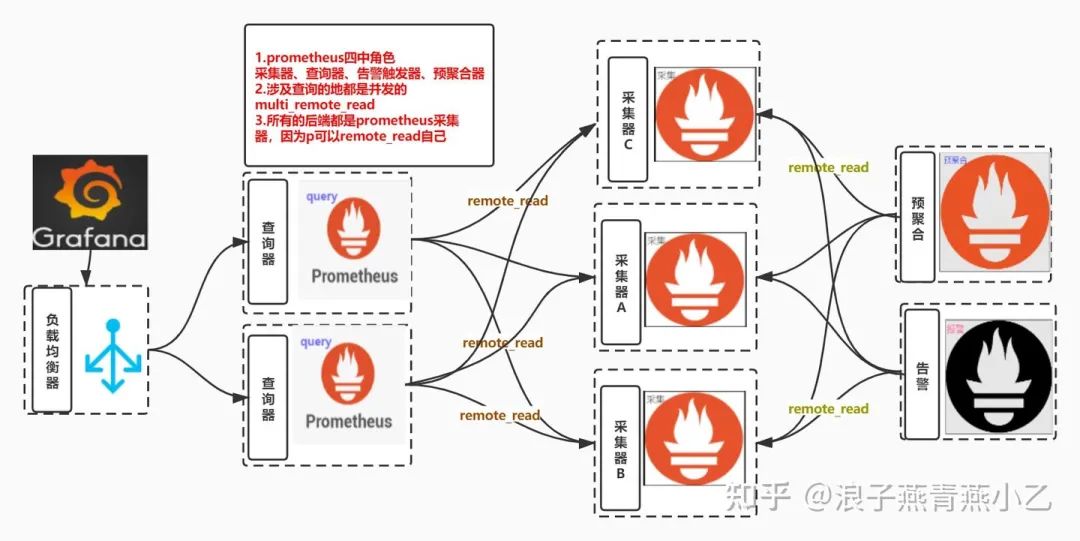
联邦问题
联邦文档地址[3]
联邦使用样例
本质上就是采集级联 说白了就是 a 从 b,c,d 那里再采集数据过来 可以搭配 match 指定只拉取某些指标 下面就是官方文档给出的样例
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'
看上面的样例配置怎么感觉是采集的配置呢
不用怀疑就是,下面看看代码分析一下 从上述配置可以看到采集的 path 是 /federate
// web.go 的 federate Handler
router.Get("/federate", readyf(httputil.CompressionHandler{
Handler: http.HandlerFunc(h.federation),
}.ServeHTTP))
分析下联邦函数 说白了就是读取本地存储数据处理
func (h *Handler) federation(w http.ResponseWriter, req *http.Request) {
// localstorage 的query
q, err := h.localStorage.Querier(req.Context(), mint, maxt)
defer q.Close()
// 最终发送的Vector 数组
vec := make(promql.Vector, 0, 8000)
hints := &storage.SelectHints{Start: mint, End: maxt}
var sets []storage.SeriesSet
set := storage.NewMergeSeriesSet(sets, storage.ChainedSeriesMerge)
// 遍历存储中的full series
for set.Next() {
s := set.At()
vec = append(vec, promql.Sample{
Metric: s.Labels(),
Point: promql.Point{T: t, V: v},
})
for _, s := range vec {
nameSeen := false
globalUsed := map[string]struct{}{}
protMetric := &dto.Metric{
Untyped: &dto.Untyped{},
}
// Encode方法根据请求类型编码
if protMetricFam != nil {
if err := enc.Encode(protMetricFam); err != nil {
federationErrors.Inc()
level.Error(h.logger).Log("msg", "federation failed", "err", err)
return
}
}
}
protMetric.TimestampMs = proto.Int64(s.T)
protMetric.Untyped.Value = proto.Float64(s.V)
protMetricFam.Metric = append(protMetricFam.Metric, protMetric)
}
//
if protMetricFam != nil {
if err := enc.Encode(protMetricFam); err != nil {
federationErrors.Inc()
level.Error(h.logger).Log("msg", "federation failed", "err", err)
}
}
}
最终调用压缩函数压缩
type CompressionHandler struct {
Handler http.Handler
}
// ServeHTTP adds compression to the original http.Handler's ServeHTTP() method.
func (c CompressionHandler) ServeHTTP(writer http.ResponseWriter, req *http.Request) {
compWriter := newCompressedResponseWriter(writer, req)
c.Handler.ServeHTTP(compWriter, req)
compWriter.Close()
}
如果没有过滤那么只是一股脑把分片的数据集中到了一起,没意义。很多时候是因为数据量太大了,分散在多个采集器的数据是不能被一个联邦消化的。
正确使用联邦的姿势
使用 match 加过滤,将采集数据分位两类
第一类需要再聚合的数据,通过联邦收集在一起
只收集中间件的数据的联邦 只收集业务数据的联邦 举个例子
其余数据保留在采集器本地即可
这样可以在各个联邦上执行
预聚合和alert,使得查询速度提升
默认 prometheus 不支持降采样
可以在联邦配置 scrape_interval 的时候设置的大一点来达到 模拟降采样的目的 真实的降采样需要 agg 算法支持的,比如 5 分钟的数据算平均值、最大值、最小值保留,而不是这种把采集间隔调大到 5 分钟的随机选点逻辑
正确实现统一查询的姿势
什么是 remote_read
简单说就是 prometheus 意识到自己本地存储不具备高可用性,所以通过支持第三方存储来补足这点的手段 配置文档地址[4]
读写都支持的存储
AWS Timestream Azure Data Explorer Cortex CrateDB Google BigQuery Google Cloud Spanner InfluxDB[5] IRONdb M3DB[6] PostgreSQL/TimescaleDB QuasarDB Splunk Thanos TiKV
但是这个和我们今天聊的问题关联在哪里?,往下看你就知道了
multi_remote_read
如果我们配置了多个 remote_read 接口的话即可实现 multi
remote_read:
- url: "http://172.20.70.205:9090/api/v1/read"
read_recent: true
- url: "http://172.20.70.215:9090/api/v1/read"
read_recent: true
上述配置代表并发查询两个后端存储,并可以对查询的结果进行 merge
merge 有啥用:你们的查询 promql 或者 alert 配置文件就无需关心数据到底存储在哪个存储里面 ,可以直接使用全局的聚合函数
prometheus 可以 remote_read prometheus 自己
感觉这个特点很多人不知道,以为 remoteread 必须配置第三方存储如 m3db 等,其实 p 也可以 remote_wirte 自己,只不过需要开启 --enable-feature=remote-write-receiver
高可用方案
所以结合上述两个特点就可以用多个采集的 prometheus + 多个无状态的 prometheus query 实现 prometheus 的高可用方案
监控数据存储在多个采集器的本地,可以是机器上的 prometheus 也可以是 k8s 中的 prometheus statefulset prometheus query remote_read 填写多个 prometheus的/api/v1/read/地址
数据重复怎么办
不用管,上面提到了 query 会做 merge,多个数据只会保留一份
可以利用这个特点模拟副本机制:
重要的采集 job 由两个以上的采集 prometheus 采集 查询的时候 merge 数据 可以避免其中一个挂掉时没数据的问题
这种方案的缺点
并发查询必须要等最慢的那个返回才返回,所以如果有个慢的节点会导致查询速度下降,举个例子:
有个美东的节点,网络基础延迟是 1 秒,那么所有查询无论返回多快都必须叠加 1 秒的延迟。
应对重查询时可能会把 query 打挂。
但也正是这个特点,会很好的保护后端存储分片,重查询的基数分散给多个采集器了。
由于是无差别的并发 query,也就是说所有的 query 都会打向所有的采集器,会导致一些采集器总是查询不存在他这里的数据
那么一个关键性的问题就是,查询不存在这个 prometheus 的数据的资源开销到底是多少?据我观察,新版本速度还是很快的说明资源开销不会在很深的地方才判断出不属于我的数据。
m3db 有布隆过滤器来防止这个问题。
如果想精确把 query 打向数据它的存储分片可以参考我之前写的 route 方案:开源项目 : prome-route:使用反向代理实现 prometheus 分片[7]
主要哦,需要特征标签支持,并且数据天然就是分开的!!
忘了说了,这个方案还有个缺点就是重查询没控制好容易把你的采集器打挂了。
脚注
m3db 资源开销,聚合降采样,查询限制等注意事项: https://zhuanlan.zhihu.com/p/359551116
[2]m3db-node oom 追踪和内存分配器代码查看: https://zhuanlan.zhihu.com/p/183815841
[3]联邦文档地址: https://prometheus.io/docs/prometheus/latest/federation/
[4]配置文档地址: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_read
[5]InfluxDB: https://docs.influxdata.com/influxdb/v1.8/supported_protocols/prometheus/
[6]M3DB: https://m3db.io/docs/integrations/prometheus/
[7]开源项目 : prome-route:使用反向代理实现 prometheus 分片: https://zhuanlan.zhihu.com/p/231914857
原文链接:https://zhuanlan.zhihu.com/p/368868988


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
