
数据库操作快速学习
MySQL基础

一、DDL 操作
1.操作数据库
1.创建数据库
-- 创建数据库 --
create database 数据库名 character set utf8;
2.查看所有数据库
-- 查看所有数据库 --
show databases;
3.查看数据库结构
-- 查看数据库结构 --
show create database 数据库名;
4.删除数据库
-- 删除数据库 --
drop database 数据库名;
5.修改数据库字符集
-- 修改数据库字符集 --
alter database 数据库名 character set 字符集;6.使用数据库
-- 使用数据库 --
use 数据库名;
7.查询当前使用到数据库
-- 查询当前使用的数据库 --
select database();
2.操作表
1.常用的表数据类型
| 分类 | 数据类型 | 说明 |
| 数值类型 | int 整型 bigint 大数据整型 float(M,D) 单精度浮点 double (M,D) 双精度浮点 | 2的32次方 2的64次方 M指定长度,D指定小数位数 M指定长度,D指定小数位数 |
| 时间日期 | date 日期类型 datetime 日期时间 timestamp 时间戳 | 日期类型(YYYY-MM-DD (YYYY-MM-DD HH:MM:SS) 时间戳 |
| 文本二 | char(size) 固定字符文本 varchar(size) 可变字符文本 text 大文本类型 | 固定长度字符串 可变长度字符串 大文本 |
关于大文件:
一般数据库很少寸文件的内容,一般存储文件的路径。
2.约束
作用:保证用户从插入的数据是符合规范的。
| 约束 | 关键字 |
| 主键 | primary key |
| 唯一 | unique |
| 非空 | not null |
唯一:唯一约束,字段不能出现重复的数据。
非空:字段数据不能为空,必须要有数据。
主键:主键约束(非空+唯一),一般用于字段id。
主键可以增加自动增长 auto_increment ,主键自增。
3.查看所有表
-- 查看表 --
show tables;
4.查看表定义结构
-- 查看表结构 --
desc 表名;
5.查看表创建结构
-- 查看表结构 --
show create table 表名;
6.修改表
-- 增加一列:add --
alter table 表名 add 字段 类型 约束;
-- 修改列的名称:change --
alter table 表名 change 旧列名 新列名 类型 约束;
-- 修改列的类型约束:modify --
alter table 表名 modify 字段 类型 约束;
-- 删除一列:drop --
alter table 表名 drop 列名;
-- 修改表名 --
rename table 旧表名 to 新表名;
7.删除表
drop table 表名;二、DML操作表记录
1. 插入数据
方式一:插入指定的列
insert into 表(列,列...) values(值,值...);
如果没有把列写出来,则自动赋值null
方式二:插入所有列
insert into 表 values(值,值...);
主键自增的话可以赋值为null,其他所有字段必须赋值。
2. 更新记录
update 表名 set 字段=值... where 条件;
3. 删除记录
可以使用2种方式删除
使用 delete
使用 truncate
delete 和 truncate的区别:
delete:删除表中的数据,表结构还在,记录可以找回。
truncate:直接把表drop掉,再创建一个同样的新表。
-- 删除表数据 --
delete table 表名 where 条件;;
-- 删除整张表再重新创建表 --
truncate table 表名;
在工作中的删除:
物理删除:真正删除,数据不在。
逻辑删除:假删除,数据还在,做个标记,1启用,0禁用。
三、 DQL查询表记录
1. 单表查询
1.1 简单查询
-- 条件查询 --
select * from 表名 where 条件;
-- 查询某张表特定列 --
select 字段,字段... from 表名 where 条件;
-- 去重查询(如果有重复的数据只留1个) --
select distinct 字段 from 表名 where 条件;
-- 别名查询 (as可省略)--
select 字段 as 别名 from 表名 where 条件;
-- 运算查询(+,-,*,/等列运算) --
select 字段 = 字段-2 from 表名 where 条件;
注意:去重查询distinct前面不可有字段,否则会报错。
如果要查询多个字段的去重查询,则:
-- 多个字段去重查询(如果有重复的数据只留1个) --
select distinct 字段,字段... from 表名 where 条件;
1.2 条件查询
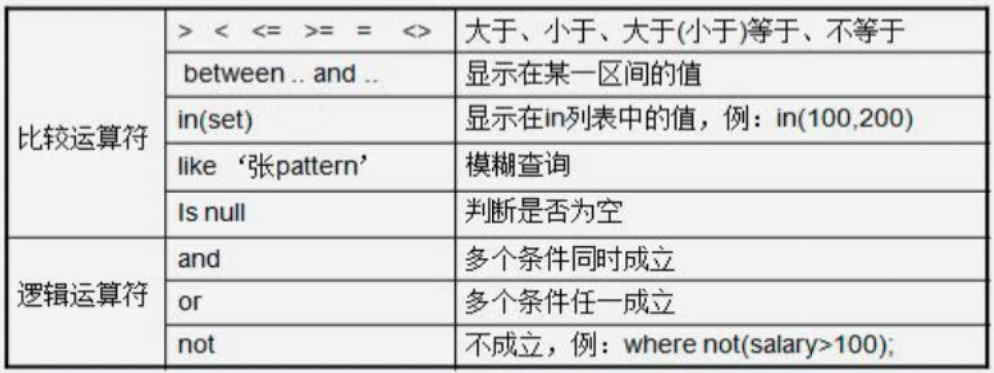
2.排序查询
使用 order by 排序子句
排序语法:
asc 升序
desc 降序 (默认)
2.1 单列排序
语法:只按照某个字段进行排序。
如果有条件,要写在排序前面。
-- 单列排序 --
select * from 表名 order by 字段 desc;
2.2 组合排序
同时对多个字段进行排序,如果第1个的字段值相等,则按照第2个字段排序。
-- 组合排序 --
select * from 表名 order by 字段1 desc,字段2 asc;
3. 聚合函数
常用聚合函数:
| 聚合函数 | 作用 |
| max(字段) | 求这列的最大值 |
| min(字段) | 求这列的最小值 |
| avg(字段) | 求这列的平均值 |
| count(字段) | 统计这一列有多少条记录 |
| sum(字段) | 求这列总和 |
语法:
聚合函数是纵向查询,它是对一列的值进行计算,返回一个结果值,聚合函数会忽略空值null。
-- 聚合函数语法 --
select 聚合函数(字段) from 表名 where 条件;
注意:
聚合函数会忽略null值,如果如果在统计个数的时候计算其他数值,则要把null的也加进去,需要使用 ifnull(字段,默认值) 函数,如果值不为null,则取原来的数,如果为null,则取默认值。
-- 有null值的函数 --
select 聚合函数(ifnull(字段,默认值)) from 表名 where 条件;
4. 分组查询
是指使用 group by 语句对查询信息进行分组。
如何分组的?
将分组字段中相同内容作为一组,并返回每组的第一条数据,比如将性别分两组。
目的:
分组就是为了统计,不然没啥意义,一般要和聚合函数一起使用。
语法:
-- 分组查询 --
select 字段1,字段2... from 表名 [where 条件] group by 字段 [having 条件];
注意:
having是对分组之后的结果进行筛选,要写在后面。
where 和having的区别?【面试】
where:对查询结果进行分组前将不符合的行去掉,即先过滤再分组。
having:作用是筛选满足条件的组,即在分组后进行数据过滤,先分组再过滤。
前者where后面不可使用聚合函数,
后者后面可以使用聚合函数。
5.分页查询
limit 是限制的意思,作用是限制查询记录的条数,作为分页查询。
语法:
-- 分页查询 --
select * from 表名 limit 起始行数,查询条数;
规律:
-- 规律 --
select * from 表名 limit (页码-1)*每页显示的总条数,每页显示的总条数;
MySQL进阶
1.外键约束
外键约束作用:维护多表之间的关系。
外键:一张从表中的某个字段引用主表的主键。
主表:约束别人。
从表:使用别人的数据被别人约束。
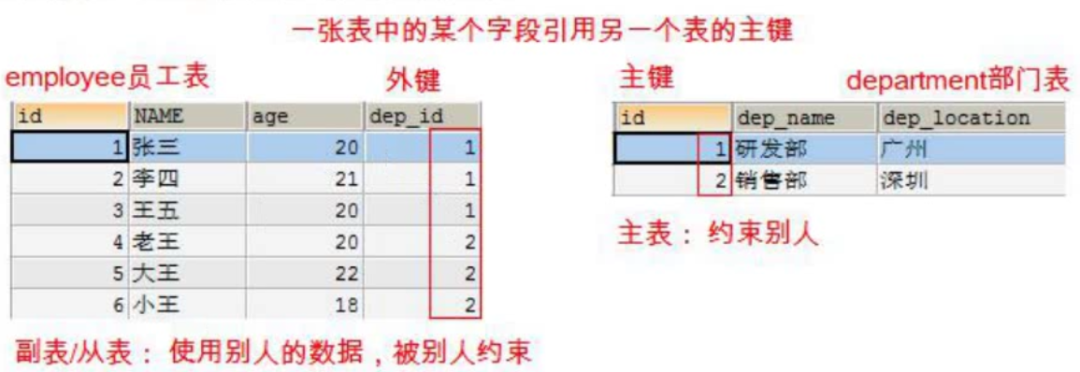
外键的语法
添加外键
1.创建表的时候添加外键约束
-- 添加外键 --
create table 表名(
...
...
constraint 外键名 foreign key(外键字段名) references 主表名(主键)
)
2.给已有表添加外键
-- 添加外键 --
alter table 表名 add constraint 外键名 foreign key(外键字段名) references 主表名(主键);
注意:为已有的表设置外键约束,那么外 键字段中的值一定要合法,不能是非法数据,否则添加外键约束失败。(也就是说,外键的值是主键的值才可以成功设置外键)
删除外键
-- 删除外键 --
alter table 表名 drop foreign key 外键约束名;
注意:外键约束名是创建外键时的约束名而不是外键字段。
外键级联
什么是级联操作?
在修改和删除主表的主键时,同时更新或删除副表的外键值。
(主键修改,外键也会跟着修改)
on update cascade 级联更新,主键发生更新时,外键也会更新
on delete cascade 级联删除,主键发生删除时,外键也会删除
在外键约束后添加即可:
-- 设置外键约束,并同时设置外键级联操作 --
alter table 表名 add constraint 外键名 foreign key(外键字段名) references 主表名(主键) on update cascade on delete cascade;
也就是说,主表在进行更新或者删除记录时,从表外键的记也会自动更新或删除。
2. 多表间关系
分析:下订单(t_order)-->谁下(t_user)-->买了啥(t_product)
老师和学生,部门和员工等。
设计表有三种关系:
一对多
多对多
一对一
一对多(1:n):
例如:班级和学生,部门和员工,客户和订单。
一的一方:班级、部门、客户
多的一方:学生、员工、订单
一对多建表原则:
在从表(多的一方)创建一个字段,字段作为外键指向主表(一方)的主键。

多对多(m:n):
例如:老师和学生、学生和课程、用户和角色
一个老师可以有多个学生,一个学生有多个老师
一个学生可以选多门课程,一门课程可以由多个学生选择
一个用户可以有多个角色,一个角色也可以有多个用户
多对多关系建表原则:
需要创建第三张表,中间表至少有2个字段,这2个字段分别作为外键指向各自一方的主键。
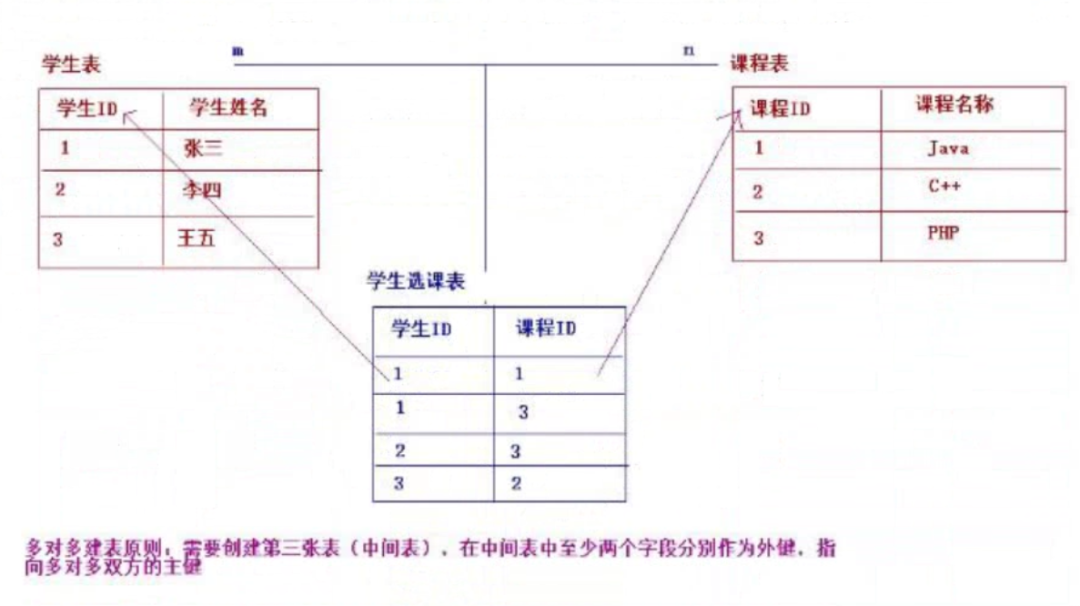
一对一(1:1):
这个没啥好说的。
两种建表原则:
外键唯一:主表的主键和从表的外键,形成主外键关系,外键unique
外键是主键:主表的主键和从表的主键,形成主外键关系
一般在开发中创建一张表即可。
3.多表查询【重点】
1. 交叉查询(连接查询)
交叉查询把若干张表没有条件的连接在一起
-- 连接查询 --
select .... from 表1,表2;
//或者选择性的选择要显示的字段
select 表1.*,表2.某个字段 from 表1,表2;
左表的每条数据和右表的每条数据组合,效果称为笛卡尔积。
注意:
交叉查询其实是一种错误,大部分数据是无用数据,叫笛卡尔积,所以交叉查询不是重点。
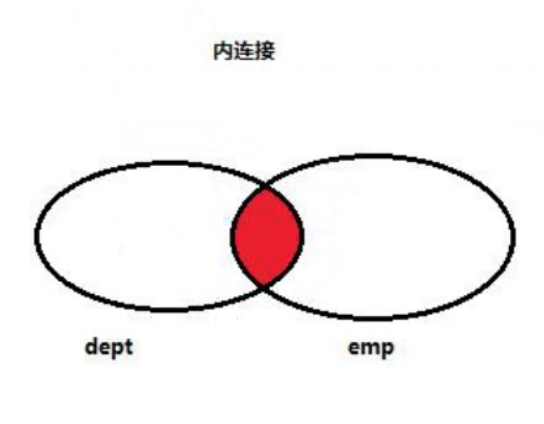
2. 内连接查询【重点】
交叉查询的结果不是我们想要的,去除不想要的记录,是通过条件过滤。
通常要查询的多个表之间都存在关联关系,那么就通过关联关系(主外键关系) 去除笛卡尔积。
内连接查询出来的数据一定是有关联的,查询出的数据是公共部分,满足连接条件(主外键关系)的部分,没有关联的数据是查不出的。
隐式内连接查询
-- 隐式内连接查询(一般外键字段=主键的值) --
select .... from 表1,表2 where 条件
显式内连接查询
-- 显式内连接查询 ,如果有其他条件,后面可加 where --
select .... from 表1 inner join 表2 on 条件;
提示:inner可以省略不写,只写join也可。
注意:条件为
表1.主键 = 表2.外键 ;小结:
使用内连接的关键点:
使用主外键关系作为条件去除无用信息,得到想要的数据。
显式内连接里面,on只能用主外键作为条件,如果有其他条件后面加where。
3. 外连接查询【重点】
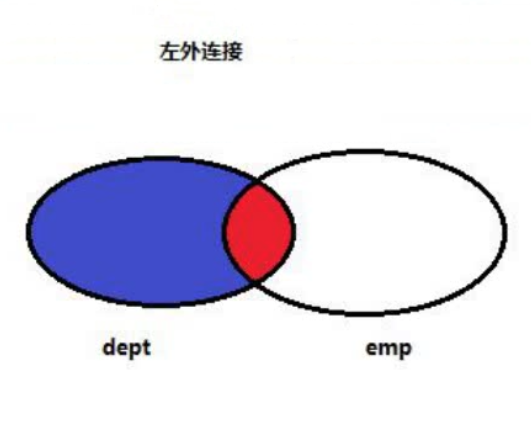
左连接查询:
在内连接的基础上保证左边表的数据全部显示
-- 左连接 --
select .... from 左表 left join 右表 on 关联条件;
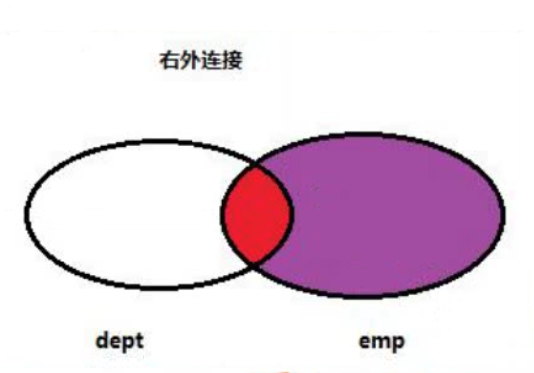
右连接查询:
在内连接的基础上保证右边表的数据全部显示
-- 右连接 --
select .... from 左表 right join 右表 on 关联条件;
连接查询是以内连接为基础上的拓展。
|
|
|
小结:
内连接:查询公共部分,满足连接条件的部分
左外连接:以左表为主表,查询出左表的所有数据,再通过连条件匹配出右边表的数据,如果满足连接条件,展示右边的数据,如果不满足,右边的数据通过 null 代替。
右外连接:以右表为主表,查询出右表的所有数据,再通过连接条件匹配出左边表的数据,如果满足连接条件则展示左表的数据,如果不满足,左边的数据通过 null 代替。
4. 子查询【重点】
什么是子查询?
一个查询语句里至少包含2个select。
个查询语句的结果作为另一个查询语句的条件
查询语句的嵌套,内部查询成为子查询
子查询要使用括号
子查询结果有三种情况:
子查询的结果是一个值
子查询的结果是单列多行
子查询的结果是多行多列
子查询结果是一个值的时候
子查询结果作为父查询的查询条件
-- 结果为一个值的子查询 --
select .... from 表 where 条件字段[= > < <>] (子查询);
子查询结果是单列多行的时候
结果集类似一个数组,父查询使用 in 运算符
-- 结果为单列多行的子查询 --
select .... from 表 where 条件字段 in (子查询);也就是说条件字段是否在子查询结果集中作为父查询条件。
子查询结果是多行多列的时候
结果集是多行多列,肯定在 from 后面作为表
子查询作为表需要取别名,否则无法访问表中字段。
-- 结果为多行多列的子查询 --
select .... from (子查询) as 表别名 where 条件;
-- 如果有多个表作为子查询 --
select a.*.b.* from (子查询1) a,(子查询2) b where a.id=b.id;
子查询小结:
子查询我们要考虑的是子查询的结果是一个值还是多个值,然后根据值来选择作为什么条件。
单值,作为 where 后的条件
单列多行,作为 where 后条件,用 in
多行多列,放在 from 后作为虚拟表,取别名
5.事务
5.1 什么是事务?
事务是指逻辑上的操作,要么全部成功,要么全部失败。
5.2 事务的作用?
保证一组操作全部成功或者失败。
5.3 MySQL进行事务管理
自动事务管理(MySQL默认)
手动事务管理
自动事务管理
一条sql语句就是一个事务(自动开启事务,自动提交事务)。
手动事务管理
start transaction ; 开启事务
commit ; 提交事务
rollback ; 回滚事务
假设抛出异常就回滚事务即可。
一句话:没问题就提交,有问题就回滚。
查询事务「了解」
-- 查询事务是否开启 --
show variables like '%commit%';
-- 设置自动事务开关 0:off 1:on --
set autocommit = 0;
5.4 回滚点「了解」
什么是回滚点?
在某些成功的操作之后,后续的操作可能成功可能失败,但是不管成功还是失败,前面的操作都已经成功,可以在当前的成功位置设置一个回滚点。可供后续失败操作返回到该位置,而不是返回所有操作。
回滚点的操作:
-- 设置回滚点 --
savepoint 名字;
-- 回到回滚点 --
rollback to 名字;
回滚点小例子:
-- 开启事务 --
start transaction ;
-- sql语句操作 --
update....
-- 设置回滚点 --
savepoint 名字;
-- sql语句操作(假设这里sql有问题异常) --
update....
-- 回到回滚点 --
rollback to 名字;
-- 提交事务 --
commit ;
注意:
建议手动开启事务,用一次就开启一次
开启事务后,要么commit,要么rollback
一旦事务提交或者回滚,当前事务就结束了
回滚到指定回滚点,这时候的事务是没有结束的
总结:
设置回滚点可以让我们在失败的时候回到回滚点,而不是回到事务开启的时候。
5.5 事务特性和隔离级别
事务特性【面试题】
原子性(Atomicity)
一致性(Consistency)
持久性(Durability)
隔离性(IsoIation)
原子性:是指事务是一个不可分割的单位,事务中的操作要么全成功,要么全失败。
一致性:事务前后数据的完整性必须保持一致。
持久性:是指一个事务一旦被提交,它对数据库中的数据是永久性的。
隔离性:是指多个用户并发操作数据库时,一个用户的事务不能被其他用户的事务所干扰,多个并发事务直接数据要相互隔离,事务直接互不干扰。
事务的隔离级别
可以设置事务的隔离级别解决读的问题。
不考虑隔离级别会引出一些问题:
脏读
不可重复读
幻读
事务在操作时的理想状态:所有事物之间保持隔离,互不影响。因为并发操作,多个用户同时访问同一个数据,可能引发并发访问问题
| 并发访问问题 | 含义 |
| 脏读 | 一个事务读取到了另一个事务尚未提交的数据 |
| 不可重复读 | 一个事务中2次读取的数据内容不一致,要求的是一个事务中多次读物的数据是一致的,这是事务update时引发的问题 |
| 幻读 | 一个事务中2次读物的数据的数量不一致,要求在一个事务中多次读取的数据的数量是一致的,这是insert或delete时引发的问题。 |
以上的问题可以用隔离级别解决。
事务的四个隔离级别
| 级别 | 名字 | 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 1 | 读未提交 | read uncommitted | 是 | 是 | 是 |
| 2 | 读已提交 | read committed | 否 | 是 | 是 |
| 3 | 可重复读 | repeatable read | 否 | 否 | 是 |
| 4 | 串行化 | serializable | 否 | 否 | 否 |
MySQL默认隔离级别是可重复读。
隔离界别越高,安全性越高,性能越差。
设置隔离级别
-- 设置隔离级别 --
set session transaction isolation level 隔离级别 ;
查询当前事务的隔离级别
-- 查询当前事务隔离级别 --
select @@tx_isolation;
演示数据库安全性问题的发生
解决子脏读问题:
设置隔离级别为读已提交read committed
-- 解决【脏读】的隔离级别 --
set session transaction isolation level read committed ;
解决不可重复读
-- 解决【不可重复读】的隔离级别 --
set session transaction isolation level repeatable read ;
串行化隔离级别
-- 【串行化】的隔离级别 --
set session transaction isolation level Serializable;
也就是数据的读,如果B事务正在操作未提交,要等B事务提交事务后,A事务才可进行查询到数据,也就是串行化隔离级别。
一般使用MySQL默认的第3级可重复度的级别就行。
6.数据库的备份和还原
命令行方式
备份
-- 备份 --
mysqldump -u用户名 -p密码 数据库 > 文件路径/数据库名.sql;
还原 (要先创建数据库)
-- 还原导入 --
source 文件路径;Navicat方式
这个方式就不说了嗷。
7. 数据库三大范式
建立科学的、规范的数据库需要满足一些规则来优化数据的设计和存储,成为范式。
第一范式:
数据库表的每一列都是不可分割的原子数据项,不能集合、数组等非原子数据项。简而言之,每一列不可再拆分,成为原子性。
遵循第一范式,需要什么字段的数据就查询什么数据(方便查询)。
第二范式:
在满足第一范式的前提下,表中的每一个字段都完全依赖于主键。
简而言之:
一张表只描述一件事情
表中的每一个字段都依赖主键
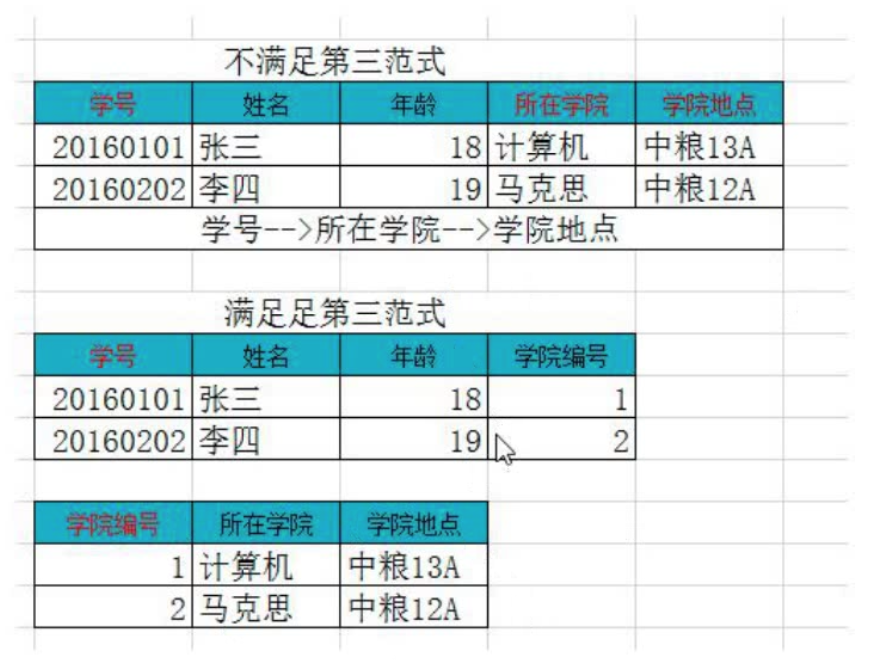
第三范式:
在满足第二范式的前提下,表中每一字段都直依赖于主键,而不是通过其他的列来间接依赖主键。
这个意思:(方便修改数据)
完结。