
互联网架构之下的数据存储技术选型逻辑

之前一篇文章介绍了在互联网架构下如何使用MySQL解决千万数据量的选型问题,详见:一天几千万订单,也是MySql做存储吗?
那除了MySQL之外,互联网技术架构体系之下还有哪些数据存储技术在应用?以及他们选型背后的逻辑是什么?
今天简单聊聊这个。
业务架构下的存储服务
随着互联网、移动互联网、物联网大潮的高速发展,互联网与智能手机的广泛使用,人们有了更多的时间是被互联网支配的。
作为平台型的互联网大厂,一些日活过亿的APP后端,每天所面对的数据量势必非常非常的大。
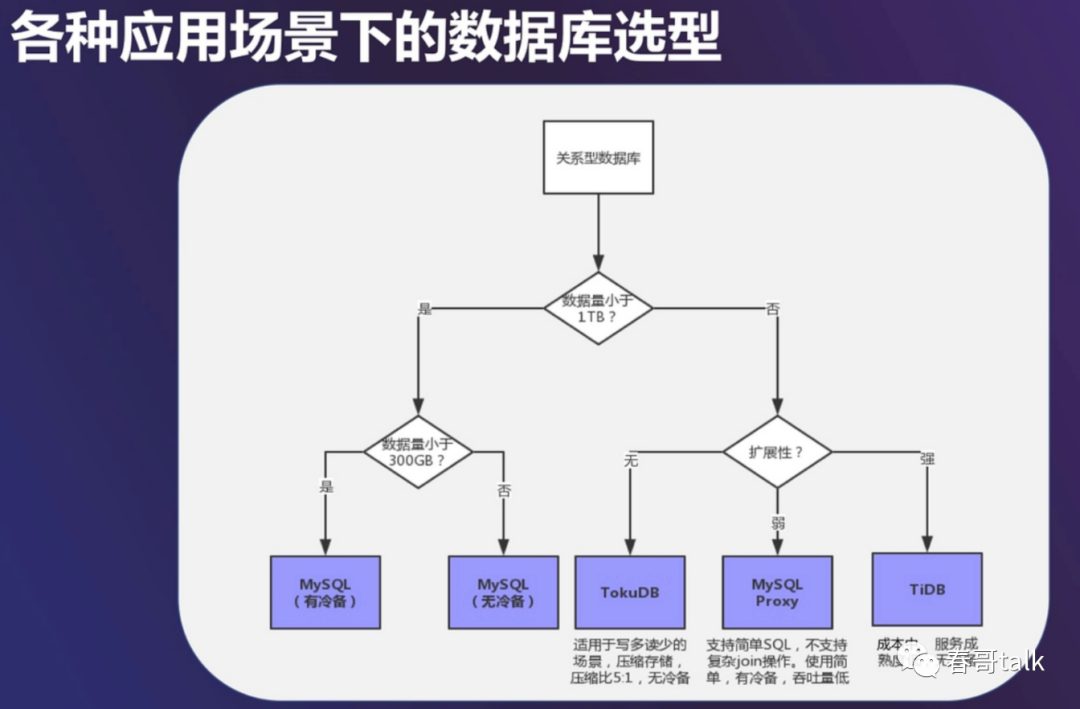
传统软件公司,或者早期的互联网公司的数据存储主要使用关系型数据库技术,比如Oracle就是其中的代表。
但传统的关系型数据库在可扩展性方面也存在着一些缺陷,即使采用并行数据库集群,最多也只能管理百台机器左右,总之海量数据的管理成本将会非常高。
目前电子制造业技术快速发展,包括磁盘、SSD、内存在内的存储设备成本都在大幅下降。不排除有些公司或者业务,已经选择大量使用基于内存的KV存储数据实现服务性能大幅提升。
其实这真的是一种选择,特别是在云原生时代之下,比如PingCAP创始人黄东旭就说:TiDB在云上不会考虑有磁盘这件事,内存那么便宜。
Redis是著名的内存KV数据库,大家肯定用的比较多。
对于内存数据库来说,首先要解决的第一个问题就是数据的高可用性。
看下Redis是如何做数据副本维护的:

Master负责数据读写,可以有多个Slave来存储数据副本,副本只读且不做更新操作。
Slave初次启动之后,从Master获取数据,在数据复制过程中,Master是非阻塞的,可以同时支持读写操作。Master采用快照增量异步方式完成数据复制。
由于Master更新数据和Slave接收数据副本过程存在时间差,可能存在数据丢失的情况。
上面的逻辑其实是一种学习的逻辑,就是从what开始。
但对于日常技术选型过程中,我更推荐从问题本身出发的技术选型思维。

选型背后的逻辑是对问题的理解
在互联网场景下,在数据的使用上,对数据的一致性要求没有银行那么高。很多时候更看重数据的高可用及架构的可扩展性。因此NoSQL数据库对很多互联网应用场景是非常合适的。
NoSQL数据库不追求应用场景的统一,而是对不同类型应用有专门的NoSQL数据库来进行存储管理。
这也是NoSQL数据库的一个特点,就是说在NoSQL数据库选型时,考虑到其使用的场景反而更重要,而不是简单的站在NoSQL本身的技术视角去考虑问题。
每一个NoSQL产品的背后其实是多种分布式问题解决方案的体现,不同的NoSQL产品是解决分布式下的特定问题的。
有的问题是如何从包含数亿成员的集合中快速找到某个成员属于这个集合;
有的问题是如何极其高效的将大数据量写入存储系统中;
有的问题是如何高效的判断海量数据中哪些数据发生了变化;
有的问题是如何高效的压缩与解压PB级的数据;
所以不同场景选择什么样的数据库,其背后的选型逻辑是你怎么定义你当前遇到的问题。
如果只是简单的kv存储解决数据库qps压力,其实说实话选择Redis还是memcache差别不大,更别说选择什么样的redis分片集群机制了。
比如以下这两种选型方式我不太赞成,这种看起来还是一种浅层次的对比,没有到问题本质的层面。
bad case1:
bad case2:

比如如何判断一个数在海量数据中?
有的人会直接去想:redis怎么判断元素是否在数据集合中?
而你一旦意识到需要不断挖掘这个问题,你会发现它是个大数据量下的Bloom Filter问题。
Bloom Filter常用于高效监测某个元素是否在巨量集合中。那就可以就这这个点去看现有你已经具备的NoSQL了,哪些可以解决这个问题,实在不行你是否可以基于现有的存储NoSQL自己搞个。
比如Chrome浏览器怎么进行恶意URL判断的?网络爬虫怎么对以及爬过的URL判断的?比特币怎么对历史交易进行验证的?数据库领域怎么解决两个差异巨大的表Join过程的?
其实抽象下来,都是Bloom Filter的问题。但你看到Chrome背后的redis了吗?
所以不从问题出发,而是拿着NoSQL去直接解决这个事,就是拿着锤子找钉子,想用redis去解决一切。
很多人都懂了“不要拿着锤子找钉子”这句话的道理,但为什么在技术选型的时候还是犯这个错误?
两个原因:
这句话还仅仅停留在嘴上,并没到心里,很多时候可能只是个谈资;
对问题没有深挖,还是在看得见的二手信息中做判断,要穿透现象看本质;
一旦找到了你要解决的技术问题的本质,再做选型就非常简单了。
以这个例子来说,你就看各个NoSQL如何支持BF的。或者看不同NoSQL用BF解决什么问题就。这比你死记硬背一些Redis、Cassandra特性好用得多。

那你怎么快速定位海量数据下少量变化的数据内容呢?
我们就遇到过类似的问题,比如我们做营销推荐。营销本身就是千店千面的,而且外卖是很强的LBS场景,理论上方圆五公里的商家数量是有限的。
但每个商家有属于不同类型的门店,有的是大连锁,有的是小连锁,有的是品牌,有的就是小店。
商家在后台可以给自己商家设置对于不同用户画像的满减、同享、津贴等各种活动。平台运营也可以对品牌商家设置不同的营销策略。商家也可以参加平台的活动。
而且不同活动有不同的时间段,比如午高峰是从11:00~13:00。10:59领取的券和11:00领取的券效果和参加的活动是不一样的,最后结算的价格是不一样的。
这一系列问题你应该怎么解决,既要数据一致性、又要高QPS、还要做活动频繁上下线、对不同人千人千面、解决多个活动冲突曝光的问题?
你可以考虑下。
数据库选型只是数据存储选型的一部分
其实选择什么样的数据库,只是数据存储选型的一部分。
不仅要考虑存储量、使用场景、数据结构、分布式算法,还需要考虑数据分片之后的分布式协调。
比如分布式锁就是其中常见的一个分布式协调问题。比较著名的分布式协调管理系统包括:谷歌的chubby、雅虎的zk、以及现在常用的etcd。
当数据量变大之后,做了分片之后,多个客户端应用程序之间需要同步,并对系统环境或资源达成一致共识。
比如那个服务应该作为leader、多个服务对一个竞态数据做并发、网络分区之后脑裂了怎么办。
这些问题都是在大量数据选型,需要考虑的存储之外的问题。
比如我们做异地多活的时候,数据是需要多个可用区之间做复制的,那么数据之间如何解决冲突问题?冲突了用哪份数据?怎么知道哪个节点数据同步落后了?分区了怎么达成共识?怎么低成本解决数据不一致问题?
其实借助的就是很多分布式系统的协调方案,而并没有哪类NoSQL是可以直接解决类似问题的,我们需要针对不同NoSQL的特性做进一步的封装实现来解决我们当前的难题。

互联网架构下的分布式存储服务
在互联网架构下,还有一些分布式存储服务,但大家关注的没有mysql或者redis多。
分布式文件系统
其主要的功能有两个:
存储文档、图像、视频之类的Blob类型数据;
作为分布式表格系统的持久层;
分布式键值系统
是一种只支持KV的增删改操作的数据库,上面介绍的redis是其中的一种。
淘宝的Tair是阿里自研一个分布式kv存储引擎。
其分为持久化存储和非持久化存储两种方式:
非持久化:可以看做一个分布式缓存,类似redis和memcache;
持久化:是将数据放在磁盘中;
分布式表格系统
其对外提供表格模型,每个表格由很多行组成,通过唯一标识,每一列包含很多列,整个表格在系统中全局有序。
谷歌的Bigtable是分布式表格系统的始祖,它有双层结构,底层采用GFS作为持久化存储。GFS+BigTable双层架构是一种里程碑似的架构,其他分布式表格系统对其都有一定借鉴。
分布式数据库
关系数据库Oracle、MySQL、SqlServer在互联网及软件场景广泛应用。可以说如果没有关系型数据库,就没有IT行业的今天。
关系数据库很长时间只能运行在单机之上,但技术人并没有放弃将其变为分布式架构下的产品。
其中衍生出了很多思路想要解决关系数据库的扩展性问题。
比如在应用层划分数据,将数据划分到不同的关系数据库上;有的则是在关系数据库内部支持数据自动分片;或者干脆重写存储引擎,变成新的分布式关系数据库。
数据库中间层是属于在应用层划分数据的一种方式,做好数据拆分,屏蔽后端数据库拆分细节。这种思想也大量用于NoSQL数据库的分布式扩展架构之下。
互联网架构之下对数据使用,不只有OLTP场景需要应对大数据量的架构问题。OLAP也是其中需要面对的问题,接下来简单说下大数据常用架构体系及AI时代的大数据架构体系。
大数据
大数据分析是互联网公司使用数据的另一个主要场景,比如从海量的数据中挖掘知识,过程上包括数据源收集、数据存储管理、数据分析与挖掘、数据监控展现等。

大数据与AI
大数据前几年在组织上可能还是属于独立的一部分。但这几年随着人工智能、AI的场景不断落地,大数据+AI慢慢变成了一个业务之下了。
比如大数据平台之上会有风控部门、数据分析部门、数据推荐部门、用户画像部门、各种指标平台等。
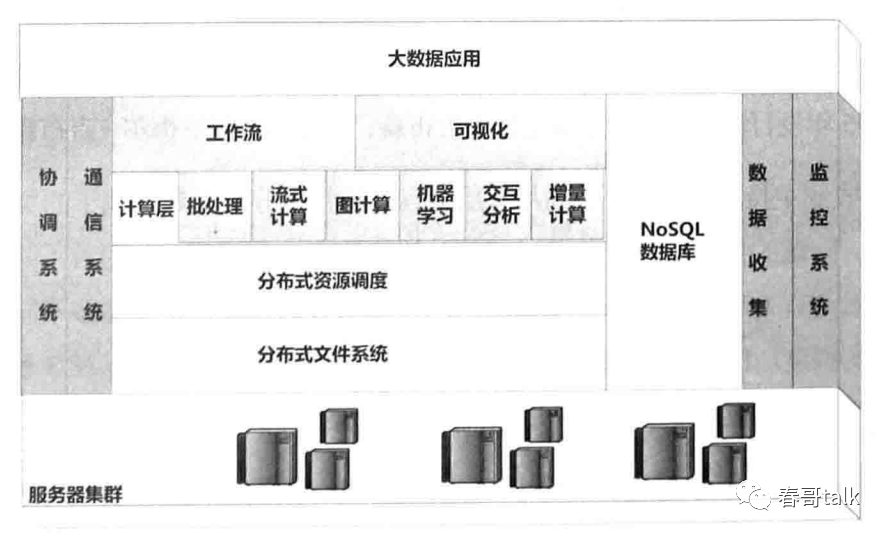
所以新的在大数据系统体系下包括,大数据存储、批处理、流式计算、交互式数据分析、图数据库、并行机器学习等在内的多个方向。
脑中还有很多想法,一时半会写不完,有时间再写吧。
希望对你有用。