
进击的数据分析:像炒菜一样做策略



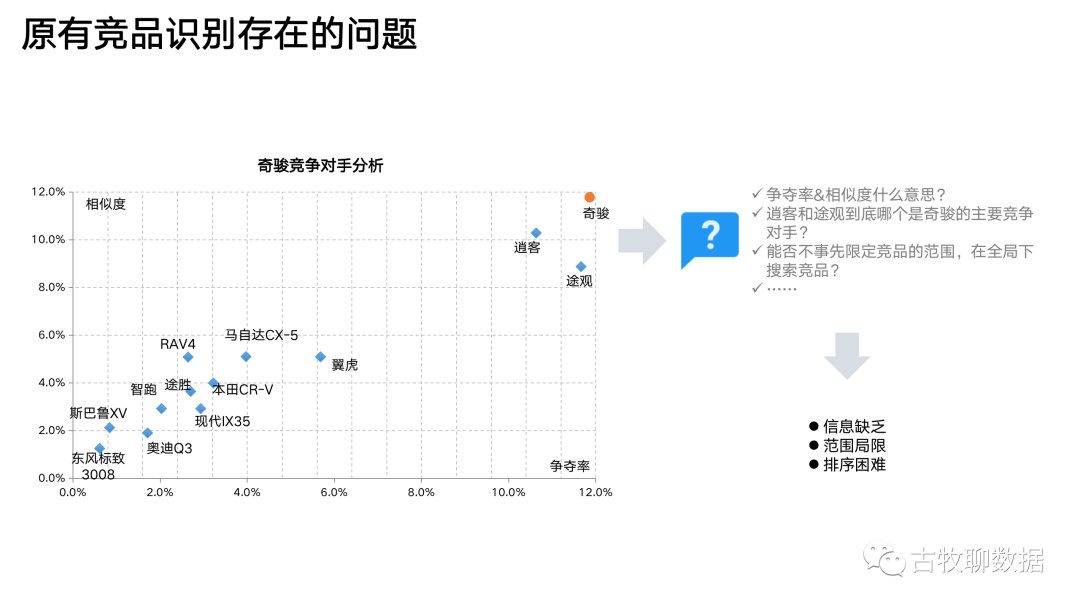
上面这个散点图,是竞品分析的传统做法。以汽车行业举例,右上角的那个奇骏就是广告主爸爸的儿子——本品,剩下的那些都是竞品,哪个离奇骏最近,哪个就是本品的最大竞品。传统做法从相似度和争夺率这2个维度来拆解“竞争”这个概念,试图量化点与点之间的距离。但有问题,因为相似度和争夺率是这么计算的:
相似度:在一段时间内,既搜过本品也搜过竞品的用户,在搜过本品或搜过竞品的总用户中的比例(本品与竞品的交集/本品与竞品的并集)
争夺率:在一段时间内,搜索过本品的用户中,有多少人还搜索过某个竞品(本品与竞品的交集/本品)
问题1:如果我事先不输入任何竞品,这个方法就行不通(相似度和争夺率的核心都是算交集,可你不告诉我跟谁交,我怎么算?)。相当于它无法突破已知的经验范畴,而我们往往就是需要数据告知一些经验以外的东西
问题2:这个方法中,只应用了“重合”这一个特征。然而用户的搜索行为是一个连续的序列,是有前后顺序(先搜A再搜B和先搜B再搜A,不一样)、有次数多寡(搜了10次A和只搜了1次A,不一样)、有距离远近的(刚搜完A就搜B,和搜完A之后又搜了CDE之再搜B,不一样),这些信息在传统方法中,都没有体现出来
问题3:传统方法下,谁是竞品需要看图说话。那么问题来了,就拿图里的逍客和途观来说,看上去跟奇骏都比较近,到底哪个才是最强劲的竞争对手?


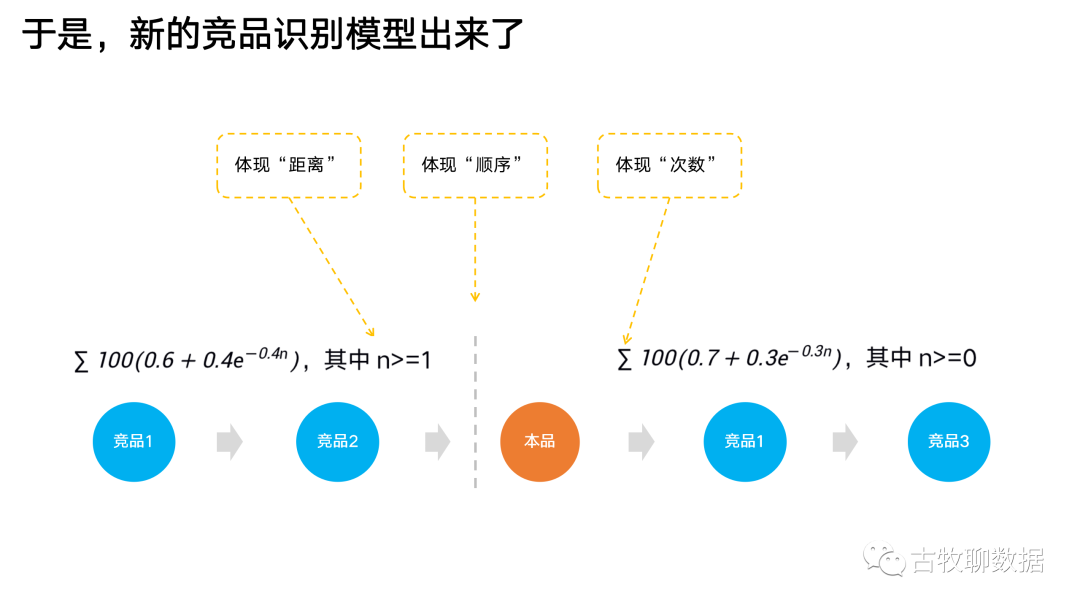
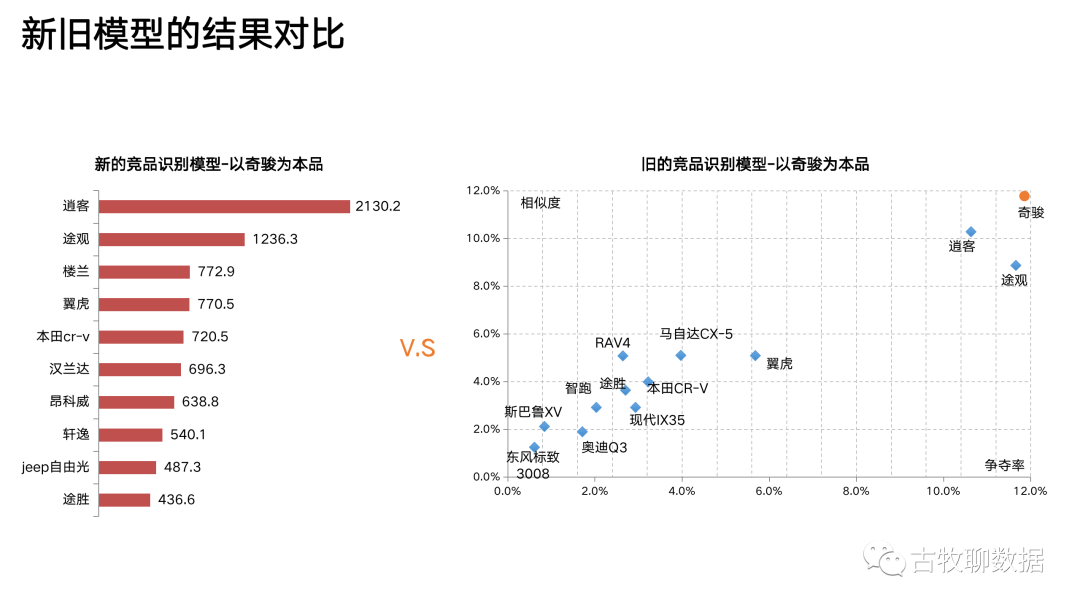
评论