
PowerBI DAX 表连续运算及上下文转换失效

DAX 中的表有两类:基表(base table)以及用作临时用途的表(table)。参考:DAX 中的表。
我们发现两个重要问题,这也是很多小伙伴提问的。这里来讲清楚。它们是:
临时表的再汇总
上下文转换的失效
下面通过一个案例来了解这个问题。
首次聚合 - 忘记上下文转换导致错误
先来看一个案例,构造一个计算表,如下:
TestTable =
VAR _table_agg =
ADDCOLUMNS(
SUMMARIZE(
'Order',
'Product'[Category] ,
Customer[Gender]
),
"Sales" , SUMX( 'Order' , [LineSellout] )
)
RETURN _table_agg结果如下:
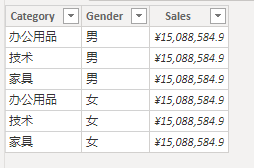
观察结果发现并不对,原因是:SUMX( 'Order' , [LineSellout] ) 发生在 ADDCOLUMNS 迭代第一个参数的表所产生行上下文中并未使用上下文转换。
首次聚合 - 带有上下文转换正确结果
为了让结果是正确的,现在带有上下文转换,如下:
TestTable =
VAR _table_agg =
ADDCOLUMNS(
SUMMARIZE(
'Order',
'Product'[Category] ,
Customer[Gender]
),
"Sales" , CALCULATE( SUMX( 'Order' , [LineSellout] ) )
)结果如下:
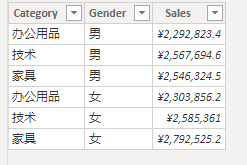
这个结果是正确的,由于使用了 CALCULATE 会产生上下文转换,使得 ADDCOLUMNS 迭代的行转换为筛选上下文,并在新的筛选上下文中计算聚合得到正确结果。
再次聚合 - 带有上下文转换却无效
现在基于刚刚的结果,做以下实验:
TestTable =
VAR _table_agg =
ADDCOLUMNS(
SUMMARIZE(
'Order',
'Product'[Category] ,
Customer[Gender]
),
"Sales" , CALCULATE( SUMX( 'Order' , [LineSellout] ) )
)
VAR _table_agg2 =
ADDCOLUMNS(
SUMMARIZE( _table_agg , 'Product'[Category] ) ,
"Total Sales" ,
CALCULATE( SUMX( _table_agg , [Sales] ) )
)
RETURN _table_agg2其中的 _table_agg2 使用和 _table_agg 完全一样的做法,使用了 CALCULATE 来进行上下文转换,我们的动机是希望 _table_agg2 可以在 _table_agg 的基础上再汇总。这个动机和想法都是对的,但结果如下:
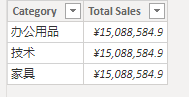
虽然带有上下文转换,但是这个转换并不能筛选 _table_agg ,这是一种重要事实。
很多时候,我们会使用计算表,而且会基于一个计算表连续运算去再次汇总得到一个新的汇总表,这时候试图用上下文转换的方式来实现意图的类似操作都会失效。因为:转换为筛选上下文后的筛选环境是无法筛选 _table_agg 的。
限于篇幅,我们补充结论如下,但不再展开:
1、行下文的确转换为了筛选上下文。
2、筛选上下文的确继续发挥了筛选的作用。
3、因此,上下文转换合理的发生且是生效的。
4、对此场景无效的原因是:筛选上下文仅仅对于数据模型表(基表)有用,对 VAR 定义的表是不存在筛选上下文说法的。
正确的再次聚合
那如果要实现再次聚合怎么做呢?这里给出两个方法,通过对比来感受不同方法的作用。
方法一:
TestTable =
VAR _table_agg =
ADDCOLUMNS(
SUMMARIZE(
'Order',
'Product'[Category] ,
Customer[Gender]
),
"Sales" , CALCULATE( SUMX( 'Order' , [LineSellout] ) )
)
VAR _table_agg2 =
ADDCOLUMNS(
SUMMARIZE( _table_agg , 'Product'[Category] ) ,
"Total Sales" ,
SUMX( _table_agg , IF( [Category] = EARLIER( [Category] ) , [Sales] ) )
)
RETURN _table_agg2结果如下:
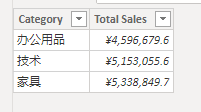
通过自主显式地筛选,得到正确的计算。这里的筛选的意义在于:
选择与当前行范围一致的数据子集。
那么,从这点来看,显然迭代整个表是有些浪费的。
这里可以用 VAR 来代替 EARLIER 使得整个计算更容易理解。
方法二:
TestTable =
VAR _table_agg =
ADDCOLUMNS(
SUMMARIZE(
'Order',
'Product'[Category] ,
Customer[Gender]
),
"Sales" , CALCULATE( SUMX( 'Order' , [LineSellout] ) )
)
VAR _table_agg2 =
GROUPBY(
_table_agg , [Category] ,
"Total Sales" ,
SUMX( CURRENTGROUP() , [Sales] )
)
RETURN _table_agg2得到结果:
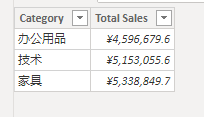
没有错,这里用到了一个比较特别的函数:GROUPBY。
而这个场景中,几乎就是 GROUPBY 的最佳使用场景,请看看它解决了什么问题,它解决了直接从内存表中获得与行上下文中内容匹配的集合的作用,这个作用是筛选上下文无法作用到的地方,而它的功效恰恰就干了这个事情。
GROUPBY
你可以查询微软官方文档或者《DAX 权威指南》对 GROUPBY 的使用解释。
微软的文档并没有说出 GROUPBY 的使用时机。《DAX 权威指南》对比了该函数与其他函数的区别并给出了一个类似例子来说明 GROUPBY 在上述场景下的功效。而本文则给出该使用 GROUPBY 的业务运算定式逻辑。
也就是说:当我们需要在业务逻辑本身进行连续汇总时,从第二次开始,使用这个方法体验了这个函数活着的意义。
最佳定式
本文的出发点是:连续型聚合表构造运算。
第一步往往构造一个轻度汇总的聚合表。
第二步再基于这个轻度汇总的表进一步聚合得到新的聚合表。
在该场景下的定式:
TestTable =
VAR _table_agg1 =
ADDCOLUMNS(
SUMMARIZE( ... ),
"KPI" , ...
)
VAR _table_agg2 =
GROUPBY(
_table_agg1 , [...] ,
"New KPI" ,
SUMX( CURRENTGROUP() , [KPI] )
)
RETURN _table_agg2性能分析
性能分析,是要基于功能实现作为前提的。在前文给出的方法中,通过对比,使用 GROUPBY 遥遥领先,这里就不给出细节。
总结
用 GROUPBY 定式可以解决临时表的再汇总问题。至于观察到的上下文转换的失效,并非真正的失效,而是筛选上下文是不会影响 VAR 定义的表的,它只能影响数据模型中的基表。通过这个案例,我们得到了新的定式;同时加深了对上下文转换的理解。
没有错,我们在这里谈的是该何时使用何种技术来解决何种业务的定式思维和底层逻辑。
让数据真正成为你的力量
Create value through simple and easy with fun by PowerBI
Excel BI | DAX Pro | DAX 权威指南 | 线下VIP学习
扫码与PBI精英一起学习,验证码:data2021
PowerBI MVP 带你正确而高效地学习 PowerBI
点击“阅读原文”,即刻开始
↙