
大模型厂商选型,大厂这次赢麻了!
AI 大模型开启洗牌模式,大厂赢麻了。
仅仅过去了半年多,大模型赛道即将迎来一次大洗牌。
根据第三方网站 SimilarWeb 的监测数据,今年 6 月 ChatGPT 的网站与移动客户端的全球流量(PV)环比下降了 9.7%,美国地区的流量环比下降了 10.3%。
ChatGPT 的独立访客数量(UV)下降了 5.7%,访客在网站上花费的时间也下降了 8.5%。
这是自 2022 年 11 月 30 日发布以来,ChatGPT 首次出现流量负增长。
很显然,初期的新鲜感已经消退,AI 要回到现实了。
在谷歌内部泄漏的一份文件中,一位内部的研究者表示:「我们没有护城河,OpenAI 也没有。」

就在 7 月 18 日,Meta 又放出大招,开源 Llama 2。

Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体,效果强于 GPT-3。
Llama 2 开源就算了,甚至还可直接商用,简直是一次降维打击。
这意味着,很多小公司的研发计划泡汤,毕竟已经有这么强的免费可直接商用的大模型面世了。
在国内,自从百度在 3 月份打响大模型的第一枪后,国内各大公司开启了“狂飙”模式。互联网公司、学术界大佬纷纷下场,发布了 79 款 10 亿参数以上的大模型。
我汇总国内的部分成果,感兴趣的小伙伴,可以看一看:
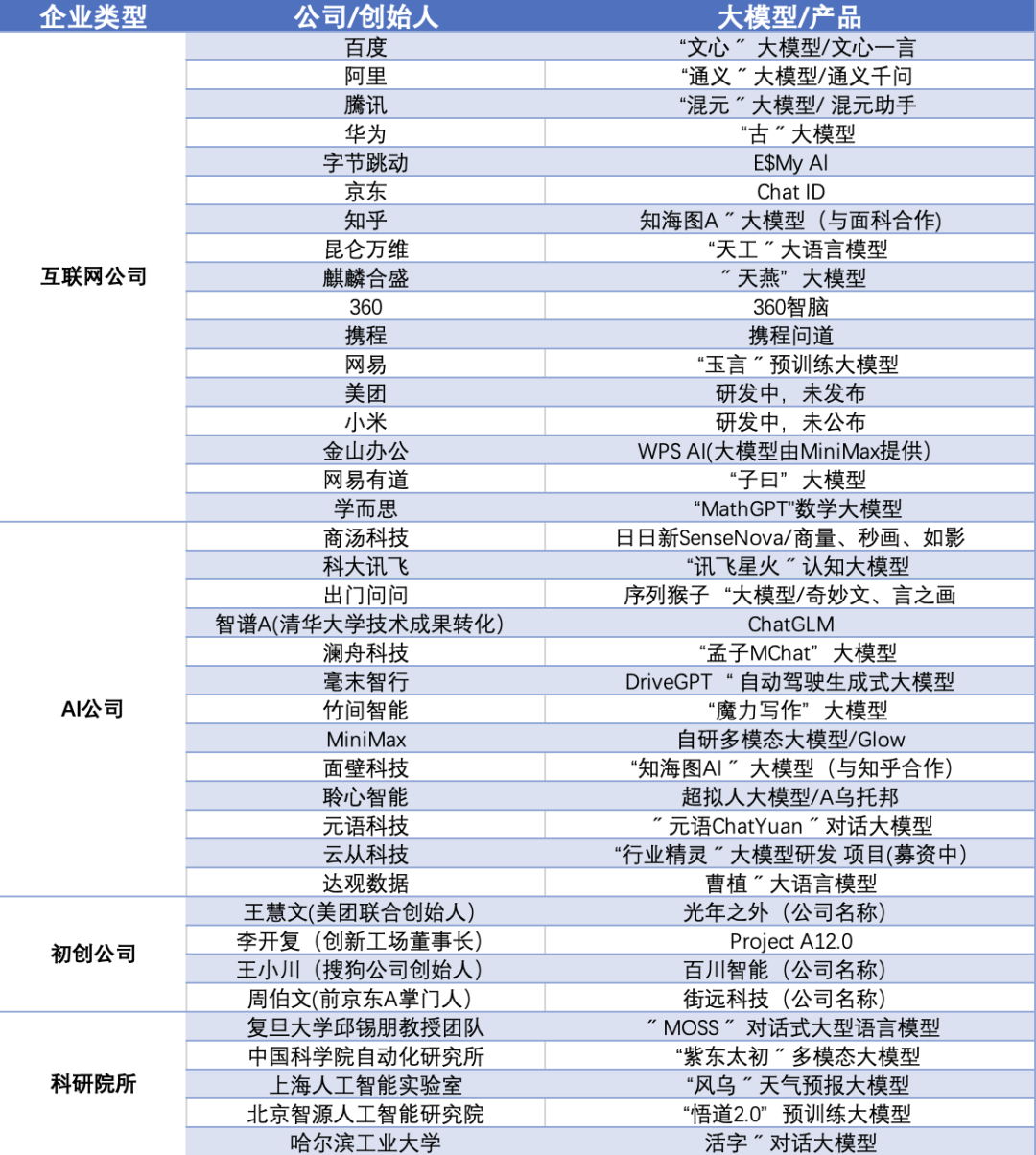
这么多大模型,一眼看过去,真是“眼花缭乱”。
那么问题来了:大模型技术,哪家强?

通用大模型的能力是基础,为了盈利,最终都要走上行业大模型的道路,要从通用面向产业。在通用大模型的基础上,针对业务场景 finetune 大模型适配特定场景。
所以显而易见,谁能更好的服务各个产业,谁就能活到最后,谁就能从“千军万马过独木桥”中胜出。
医疗问诊、法律咨询、情感服务、客服咨询等等,有太多太多的业务,可以用做过特定场景训练的大模型所“覆盖”。
有提供大模型训练能力的公司,提供训练服务,有业务数据的产业提供训练数据,大家配合起来才能实现共赢。
开源的背景下,发展到最后,技术不再是壁垒。数据、算力平台、业务渠道才是。
就像当年的云计算市场一样,底层算力和平台能力可以构建壁垒,市场需要算力强悍、模型全面的服务商。
那些在算力、平台、模型、应用方面都有布局的大厂,对企业客户具备更强吸引力。
像百度,其实在这些方面就很有优势。
百度有着自己的云服务器,不用像一些小厂那样,需要与多家云厂商合作,存在利益点和后期分成隐患。
在框架层,百度的飞桨 PaddlePaddle 是中国首个开源的产业级深度学习框架,在中国的市场综合份额排第一。
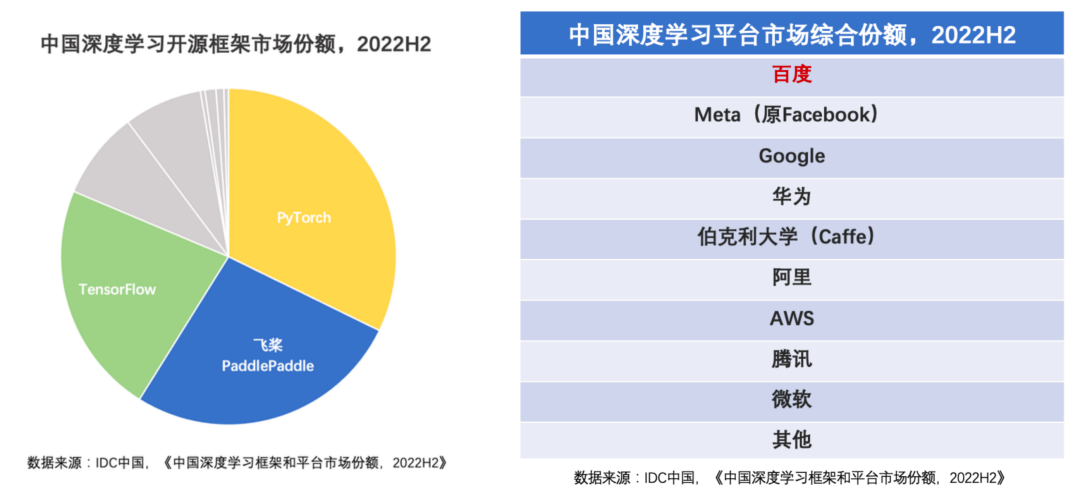
同时,飞桨长期深耕产业落地,连接着 750 万的开发者,20 万家企事业单位。文心共享飞桨生态,解决了大模型研发和部署难题,加快文心的产业落地。
大厂有着持续更新的能力,可长期投入,配套更丰富,更安全,还有着分行业的交付、运维和保障专属团队。
具备硬实力的大厂,在这次洗牌中,行业厂商选型中,具备显著优势。
不过,这都是基于现阶段的理论分析,行业格局如何演变,这没人敢保证。
毕竟,大模型推动的历史车轮,才刚刚开始。布局大模型的公司会经历一轮又一轮的洗牌。
在产业落地的过程中,能力留下来的必定是能够真正解决行业问题,创作价值的公司。
未来的大模型进展如何,我们拭目以待。